CUBRID는 10.1 version 이상부터 restoreslave란 명령어를 제공한다.
CUBRID 9.3.x version 까지는 온라인 재구성을 위해 자체적으로 제공되는 shell script를 사용하였으나,
10.1 version 이상부터는 restoreslave 명령을 통해 보다 편하게 작업을 할 수있다.
해당 명령어를 통해 master의 구동 상태와는 상관 없이, slave를 재구축 할 수 있으며, 시나리오는 아래와 같다.
1. HA 서비스 중, 이중화가 깨졌을때.
(1) 필요 환경 : master - slave의 이중화 환경.

(2) 필요 파일 : master 서버의 backup file
(3) 시나리오
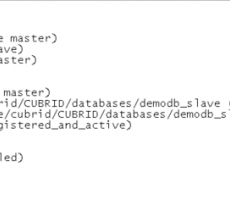
- DB의 이중화가 깨지는 것을 재연하기 위해 slave의 db_ha_apply_info의 데이터를 삭제한다.
- slave의 heartbeat를 종료한다.
slave)
$> csql -S -u dba --sysadm demodb
sysadm> delete from db_ha_apply_info;

- 위의 이중화 로그를 삭제하였을 경우, 동기화는 더이상 이루어지지 않는다.
- 위의 행위로 인하여 DB 이중화가 깨졌다고 판단하고 이중화복구를 진행하여보자.
- master에서 backup 받은 backup file은 slave에 옮겨놓은 상태이다.
slave)
$> cubrid service stop -- cubrid sevice 종료
$> ps -ef | grep cubrid -- CUBRID process가 모두 내려갔는지 확인한다.
$> cubrid restoreslave -s 'master' -m host_name -B . -o result.txt demodb
* -s 옵션은 backup을 받은 node를 지칭한다. ('master', 'slave', 'replica')
* -m 옵션은 master node의 hostname을 지칭한다.
* -B 옵션은 backup file의 경로.
* -o 옵션은 output message
- restoreslave가 모두 완료 되었으면 cubrid heartbeat start를 통하여 정상 구동여부를 확인한다.

2. HA 서비스 중, 외부 요인으로 인하여 slave의 DB가 삭제되었을때.
(1) 필요 환경 : master - slave의 이중화 환경
(2) 필요 파일 : master 서버의 backup file
(3) 시나리오
- slave의 서비스를 중지 시킨 후, slave DB 디렉토리를 삭제한다.
slave)
$> cubrid service stop
$> rm -rf db_name or cubrid deletedb db_name
- 이후, slave의 databases.txt파일을 참조하여 해당 위치에 동일한 디렉토리를 생성한다.
* 만약 deletedb로 삭제하였을 경우, $CUBRID/databases/databases.txt파일을 master의 내용과 동일하게 설정하여야한다.
- 명령어에서 알수 있듯이 DB에 대한 restoredb기능이 있기 때문에, DB 복구후 자동으로 이중화 작업이 진행된다.
- master에서 backup 받은 backup file은 slave에 옮겨놓은 상태이다.
slave)
$> cubrid restoreslave -s 'master' -m host_name -B . -o result.txt -u demodb
* -u 옵션 : databases.txt 파일을 참조하여 해당 위치에 DB를 복구한다.
- 위의 시나리오와의 차이는 -u 옵션으로 databases.txt에 등록된 위치에 DB를 복구할 수 있다는 것이다.
- restoreslave가 모두 완료 되었으면 databases.txt 파일의 db_vol_path에 해당 DB가 정상적으로 복구되었는지 확인한다.
- 마지막으로, cubrid heartbeat start를 통하여 정상 구동여부를 확인한다.
3. 고려사항.
(1) restoreslave 명령을 사용하여 DB 복구 시 최초 복구 시점은 backup 시점이다.
(2) 즉 backup 시점 이후의 모든 트랜잭션은 구동 후 반영되어진다.
(3) 이정보는 cubrid applyinfo 명령을 통하여 확인이 가능하며, delayed log page count 가 0 이 되어야, 모든 트랜잭션을 반영한 것이다.
(4) 그렇기 때문에 해당 작업이 이루어지기 전에 master에서 backupdb를 실행하여 최신의 backup file로 작업하는 것이 용이하다.

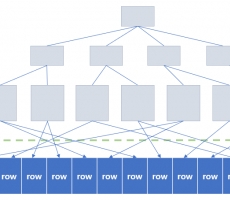
 CUBRID 커버링 인덱스(covering index) 이야기
CUBRID 커버링 인덱스(covering index) 이야기