CUBRID상에서 서비스 개발 및 운영 시 마주치게 되는 여러가지 문제를 해결하기 위해서는 오류코드(메세지)에 대한 해석과 서버에서 생성하는 다양한 로그에 대한 해석이 중요합니다.
이번 글에서는 해석에 치중하기 보다는 CUBRID 9.3 기준으로 어떤 종류의 오류코드(메세지)가 있는지 어떤 종류의 로그들이 생성되는지를 우선으로 살펴보겠습니다. 향후 시간이 되면 해석에 대해서도 글을 올리도록 하겠습니다.
C 또는 JAVA언어를 이용하여 서비스 개발시 참고할 수 있는 오류 코드 종류는 아래 표와 같으며, 이를 활용하여 Source Debugging과 다양한 조건 및 상태에 따른 분기가 가능한 프로그램을 개발할 수 있습니다.
응용관련 CCI 오류코드 (오류 메시지) JDBC 오류코드 (오류 메시지) CAS 오류코드 (오류 메시지) DB관련 데이터베이스 서버 오류코드 (오류 메시지)
먼저 발생하는 오류 코드 종류에 대해서 알아 보도록 하겠습니다.
1. 응용관련 메시지
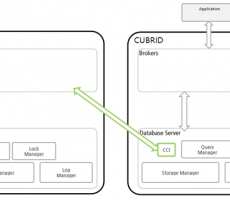
1.1 CCI에서 발생한 오류 코드 구분
CUBRID에서는 C기반 응용프로그램 개발을 위해 CCI(C Client Interface)제공하며, 오류 발생 시 음수 값을 반환합니다.
발생하는 오류 코드 구분 규칙은 다음과 같습니다.
- 20002 ~ -20999 : CCI API 함수내에서 발생한 오류 코드
- 10000 ~ -10999 : CAS에서 발생한 오류 코드.
- 20001 : 데이터베이스 서버에서 발생한 오류 코드
오류코드 목록, 각 항목에 대한 상세 메시지, 프로그램 예제 및 CCI 함수에서 사용하는 구조체에(struct) 대한 자세한 내용은 아래의 큐브리드 매뉴얼 CCI 오류코드 URL를 참고 바랍니다.
https://www.cubrid.org/manual/ko/9.3.0/api/cci.html#cci-error-codes
1.2 JDBC에서 발생한 오류 코드 구분
CUBRID에서는 Java 기반 응용프로그램 개발을 위해 JDBC 드라이버(cubrid_jdbc.jar)를 제공합니다. CUBRID JDBC 드라이버는 2.0 스펙을 기준으로 개발되었으며 설치 위치는
<CUBRID 설치 디렉터리>/jdbc 디렉터리에 위치하며 JDK 1.6에서 컴파일한 것을 기본으로 제공합니다.
Java 응용프로그램에서 오류는 SQLException Class를 통해 오류 정보를 얻을 수 있으며, 오류 코드 구분 규칙은 다음과 같습니다.
- 21001 ~ -21999 : JDBC 메소드 내부에서 발생한 오류 코드
- 10000 ~ -10999 : CAS에서 발생한 오류 코드
- 0 ~ -9999 : 데이터베이스 서버에서 발생한 오류 코드
오류 코드 및 오류 메시지를 출력하는 예제는 아래의 URL를 참고 바랍니다.
https://www.cubrid.org/manual/ko/9.3.0/api/jdbc.html
데이터베이스 서버 프로세스는 오류 발생 시 서버 오류 코드 항목을 사용합니다. 서버 오류는 서버 프로세스를 사용하는 모든 작업에서 발생할 수 있습니다. 예를 들어 질의를 처리하는 프로그램 또는 cubrid 유틸리티 사용 중에도 발생할 수 있습니다.
CCI 에서는 dbi.h를 포함할 수 있으므로 오류 코드명을 사용하는 것이 프로그램 가독성을 위해 권장되며, JDBC 에서는 dbi.h 파일을 포함할 수 없으므로 오류 코드 번호를 직접 사용합니다. JDBC에서는 SQLException 클래스의 getErrorCode() 메서드를 통해 오류 번호를 얻을 수 있습니다.
데이터베이스 오류 코드 및 메시지에 대한 자세한 내용은 아래의 URL를 참고 바랍니다.
https://www.cubrid.org/manual/ko/9.3.0/admin/control.html#database-server-error
1.4 CAS 오류 코드
브로커의 응용 서버(CAS) 프로세스에서 발생하는 오류로, CCI 또는 JDBC 드라이버를 이용하여 접속하는 모든 응용 프로그램에서 발생할 수 있습니다.
관련 오류코드 및 메시지에(CCI/JDBC)에 대한 자세한 내용은 아래의 URL를 참고 바랍니다.
https://www.cubrid.org/manual/ko/9.3.0/admin/control.html#cas-error
다음은 서버에서 발생하는 로그에 대한 내용을 살펴보겠습니다.
브로커 로그의 경우 응용서버(WAS)에서 연결되는 과정을 시작으로 질의문 및 바인드 변수, 최종 수행시간 및 건수등에 대한 내용을 포함하고 있어, 성능이슈 및 장애발생에 대한 원인분석 시 사전 징후를 체크해 볼 수 있는 용도로 활용해 볼 수 있습니다. 운영 환경에서 APM 솔루션이 구축되어 실시간 및 사후 분석이 가능한 환경이라면 브로커 로그를 비활성화 할 수도 있습니다.
브로커 관련 로그에는 접속 로그, 오류 로그, SQL 로그가 있으며 각각의 로그는 설치 디렉터리의 log 디렉터리에서 확인할 수 있습니다.
- 접속 로그는 응용 클라이언트 접속에 관한 정보를 기록하며 $CUBRID/log/broker의 위치의 <broker_name>.access 형태로 저장됩니다.

- 오류 로그는 응용 클라이언트의 요청을 처리하는 도중에 발생한 오류에 관한 정보를 기록하며, $CUBRID/log/broker/error_log 위치의 <broker_name>_<app_server_num>.err 형태로 저장됩니다.
![]()
- SQL 로그는 응용 클라이언트가 요청하는 SQL을 기록하며, $CUBRID/log/broker/sql_log 위치의 <broker_name>_<app_server_num>.sql.log 형태로 저장된다. 저장여부 및 위치,용량(기본값 : 10MB)을 파라메타 설정으로 변경할 수 있다.

2.2 데이터베이스 서버 로그
데이터베이스 서버 로그는 master에서 발생하는 로그, 각 유틸리티에서 발생하는 로그 및 데이터베이스 서버에서 발생하는 로그로 구분됩니다.
- master 로그는 HA에 대한 정보와 서버들의 연결에서 발생하는 오류 정보를 확인할 수 있습니다. 위치는 $CUBRID/log/<hostname>_master.err 입니다.
- 각 유틸리티에서 발생하는 로그는 유틸리티 실행시 발생하는 로그를 저장하는 것으로 위치는 $CUBRID/log/<db name>_<utility name>.err 입니다.
대표적으로 cubrid_utility.err 로그는 DB 기동 및 정지와 관련 유틸리티들이 실행된 로그를 저장하는 로그 파일입니다.
- 데이터베이스 서버에서 발생하는 로그는 제한된 IP에서 접속을 시도하거나 정상 임계치를 벋어난 성능 이슈 및 오류 발생 등의 로그입니다.
로그는 $CUBRID/log/server 위치하며, <db name>_<start date_time>.[access | event | err] 의 파일명으로 저장됩니다.
서버 로그에 대한 자세한 정보는 아래의 URL를 통해 자세한 내용을 참고 바랍니다.
https://www.cubrid.org/manual/ko/9.3.0/admin/control.html#server-logs