Timezone
Timezone 하면 딱 생각나는 것은 +09:00, 우리나라는 그리니치 표준시 (GMT)보다 9시간 빠르다는 것이다.
해외 여행중 한국에 국제 전화할 때 꼭 알아야 할 것, "한국 시간 몇시인가?" 잘못하면 식구들 자는 중에 집에 전화할 수 있다.
Timezone이 뭔가? 사전적 정의는 “특정 국가나 지역의 현지시간 (local time)” 이다.
그리니치 표준시의 정오는 경도 0도에 위치한 그리니치 천문대 남중 자오선을 태양이 지나가는 시간이다.
1925년 부터, 특정 지역의 local-time은 그리니치 표준시를 기준으로 몇시간 빠르고 느린가로 표현되어왔다.
그리니치 동쪽은 +, 서쪽은 -로 표현한다.
GMT 시간이 그리니치 천문대를 지나는 태양을 기준으로 하기 때문에 시간이 지구의 자전 주기와 관련 되며,
자전의 흐름이 늦어지면서 오차가 발생되었고 새로운 표준시 제정에 대한 요구가 나오게 되었다.
1972년, 국제 표준시는 그리니치 표준시에서 UTC (Coordinated Universal Time)로 변경되었다.
UTC는 세슘 원자 시계 기반의 세계 표준시이며,
UTC와 GMT는 소숫점 단위에서만 차이가 나기 때문에 일상적으로 같은 수준으로 혼용해서 사용하기도 하나
기술적인 표현에서는 UTC를 쓴다.
Standard Time/Daylight saving time
'Standard Time'이란
- 특정 국가/지역에서- 일광 절약 시간제(Daylight saving time, DST 또는 summer time)를 적용하지 않았을 때- 그 지역의 localtime을 말한다.
전 세계의 60% 국가가 DST 없이 1년 내내 표준시 만을 사용하고 있고, 나머지 지역은 여름동안 1시간 빠른 DST를 채택하게 된다.
Timezone 이름도 이를 반영하여 timezone의 가운데 문자에 다음을 사용한다.
- S: 표준시를 사용중인 경우 (예: EST, KST, PST)
- D: summer time/Daylight Saving time 적용중 (EDT, KDT, PDT)
하루는 24시간 이기 때문에 각 localtime별 시간차가 1시간이라면 서로 다른 localtime은 24개 일 것이다.
실제적으로 45분, 30분을 시간차로 사용하는 지역이 있기 때문에 현재 38개의 지역 시간(localtime)이 사용되고 있다.
KST, JST와 같이 하나의 localtime을 같이 사용하는 timezone이 많기 때문에 timezone 개수는 38보다
훨씬 많다 (CUBRID query를 통해서 확인하니 593개가 있는 것으로 확인된다.
이외에도 Alpa, Brabo, Charlie등의 military time zone도 25개가 있다.
CUBRID CSQL Timezone Command for timezone:
- SHOW TIMEZONES; -- 전체 timezone
- SHOW FULL TIMEZONES WHERE REGION_OFFSET = '+09:00'; -- offset이 +09:00인 timezone 정보

tz database by IANA (https://www.iana.org/time-zones/)
IANA는 timezone에 관련된 공식적인 정보를 text형태로 유지하고 있다.
이 text file은 각 platform 별로 machine processable binary 형태로 변경되어 사용된다
BSD 계열 시스템, GNU C, Android, Java Runtime, .NET, Python, Perl, Go등의 대부분 software
platform이 IANA timezone을 support 한다.
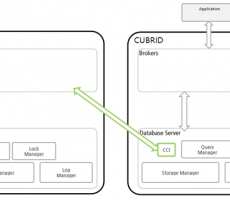
물론 CUBRID도 IANA tz database를 이용하여 timezone 관리를 한다 (CUBRID 10 version).
CUBRID timezone library는 IANA에서 받은 tzdata를 처리하여 (compile) timezone 정보를
library에 저장하고 (libcubrid_timezones.so) 이때 사용된 timezone file의 MD5 checksum을 구하여
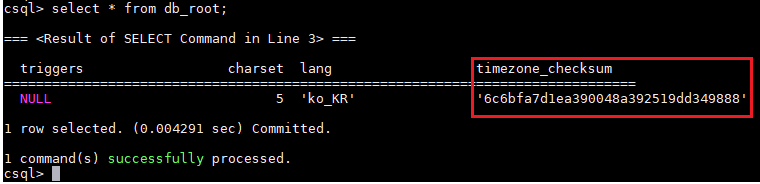
database의 db_root에 저장한다.
Timezone file이 recompile되면 library의 checksum이 변경되고, 이런 경우 db_root에 저장된 checksum과 다르기 때문에
기존 CUBRID server나 tool이 기존의 database와 연동하여 기동되지 않을 수있다.
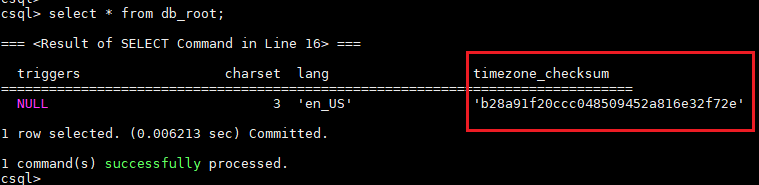
호환성 유지를 위해서는 'make_tz.sh' tool에서 ‘extend’ option을 사용하면 ($ make_tz.sh -g extend)
기존의 database checksum이 새로 생성된 checksum으로 변경되며 새로 build된 timezone library와 호환성이 유지된다.
'make_tz.sh -g extend' option을 수행할 때는 반드시 수행중인 db server를 먼저 중지시켜야 한다.
그렇지 않은 경우 db_root의 checksum update 하는 도중 error 발생함 (databases.txt에 등록된 모든 db 서버)
original db_root
db_root after make_tz.sh -g extend
tz database format
tz_database에는 다음 형태의 2가지 형태의 record가 정의된다.
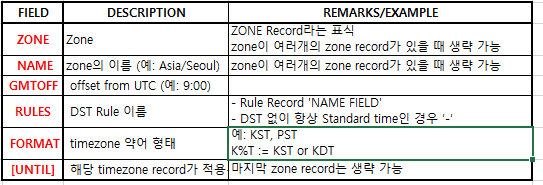
Zone: timezone 정보. 하나의 timezone에 대해서 여러 개의 timezone 정보가 있을 수 있다. (연도/기간별)
Rule: daylight saving rule 정보 (기간별로 여러 개의 record가 있을 수 있다).
Rule: daylight saving rule 정보 (기간별로 여러 개의 record가 있을 수 있다).
Time zone 이름은 “Area/Location” 형태로으로 정의된다. 예를 들어 “America/New_York”, “Asia/Seoul” 형태이다.
현재 사용되는 대룩/대양의 이름은 아래와 같다.
- Africa/America/Asia/Australia/Europe- Antarctica/Arctic/Atlantic/Indian/Pacific- Etc
'Etc'는 관리용 zone으로 'Etc/UTC', 'Etc/GMT', 'Etc/GMT-14', 'Etc/GMT+9' 형태로 사용된다 (for POSIX style compliance)
Location은 지역내의 도시/섬 이름을 사용한다. 때로 localtime은 3 level로 사용하기도 한다 ('America/Indiana/Indianapolis')
ZONE Record Format
Rule Record Format

tz database의 예 (ZONE Record)
- LINE#3: 1912년 1월까지는 KST를 사용했다.
- LINE#4: Timezone이 'JST'로 변경되었다 (1945년 8월까지, 아픈 역사가 timezone에도 남아있다).
- LINE#6: 1961년 8월 10일 Summer time이 적용되고 Rule명은 은 'ROK' 이다.
- LINE#12, 13: 평양은 2015년 8월 부터 2018년 5월까지 GMT+0830을 사용하다 GMT+0900으로 복귀했다.
- Asia/Seoul의 rule record 이름은 'ROK'이다.

tz database의 예 (Rule Record)
- LINE#14: 88 올림픽때 5월 8일 이후 일요일에 Summer Time이 적용되었고
- Line#15: 88년 10월에 Standard Time으로 복귀했다

TimeZone 관련 CUBRID Command/Configuration
- TIME ZONE 검색
csql> SHOW TIMEZONES; csql> SHOW FULL TIMEZONES; csql> SHOW FULL TIMEZONES LIKE 'Asia/S%'; csql> SHOW TIMEZONES LIKE 'Asia/S%'

- Timezone Recompile
$ cd $HOME $ wget https://data.iana.org/time-zones/releases/tzdata2018g.tar.gz $ cd $CUBRID/timezones/tzdata $ tar xvf $HOME/tzdata2018g.tar.gz $ cubrid server stop demodb ## must stop db server before run make_tz $ make_tz.sh -g extend
- db timezone 변경
[cubrid.conf] server_timezone=server_timezone=America/Indiana/Indianapolis
- session timezone 변경
csql> SET SYSTEM PARAMETERS 'timezone=Asia/Seoul'; csql> SET SYSTEM PARAMETERS 'timezone=America/New_York'; csql> SET TIMEZONE 'Asia/Seoul'; csql> SET TIMEZONE '+09';
- timezone 확인 (session timezone은 일반 user도 변경 가능)
csql> SELECT DBTIMEZONE(), SESSIONTIMEZONE();
마무리하며
이 blog를 쓰게된 동기는 CUBRID 10.1 인증 과정에서 TTA 엔지니어가 IANA Timezone data를 compile 하던중
에러를 발견했으니 수정해달라는 요구를 받고서이다.
IANA tzdata를 받아서 처리하다보니 (make_tz.sh) asia FILE의 #1656에 에러가 발견되었다.

살펴보니 적용시간인 AT의 값이 25:00 이었다. 다음날 새벽 1:00라는 의미이다.
CUBRID는 시간이 24를 넘어가면 잘못된 data가 있다고 판단하여 오류를 발생하고 compile을 종료한다.
1656 Line을 해석해보면, 1948년 9월 8일이나 그 이후의 첫번째 토요일 이후 25:00 에 적용된다는 것인데,
달리 해석하면 1일을 더 더해서 9월 9일 이나 그 이후의 첫번째 일요일 새벽 1:00와도 같은 의미가 된다.
결과적으로 아래의 2개의 RULE Record, LINE#4와 LINE#6은 의미상으로 같아진다.

IANA Timezone file을 compile하는 binary인 'gen_tz'에서 25:00을 이해하고, timezone library에서
25:00 style을 support하는 것이 원칙이겠지만, gen_tz가 tz data를 compile하는 과정에서
위의 LINE#6 style로 변환해도 문제가 없을듯하다. 일단 이렇게 수정해서 TTA GS인증용 build를 하고,
10.2 오류 보고하였다.
아래는 수정된 gen_tz가 25:00을 다음날 1:00으로 바꾼 결과이다.
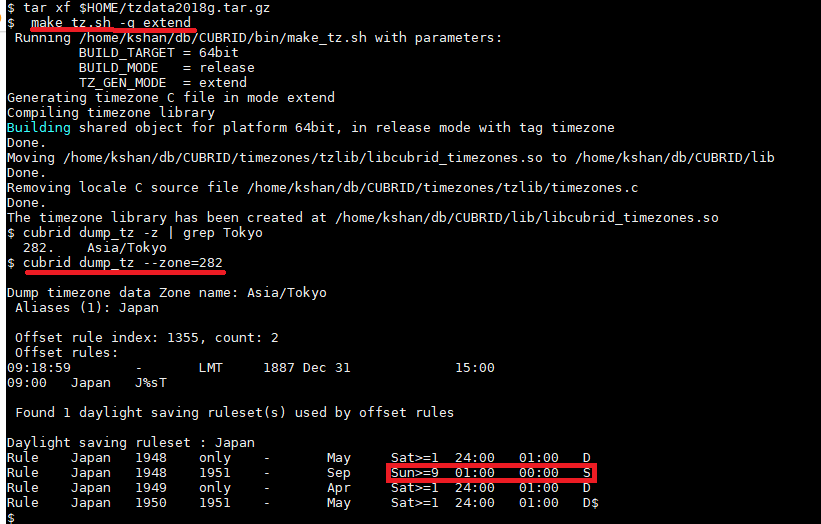
dump_tz는 현재 library에 compile된 tz data를 보여주는 명령어이다.
- IANA tz data를 받아 '$CUBRID/timezones/tzdata" directory에 풀고
- 'make_tz.sh -g extend'를 실행하였다.
- 'dump_tz -z | grep Tokyo' 명령을 실행하여 Asia/Tokyo의 timezone id '282'를 찾은후
- 'dump_tz --zone=282'를 실행해보았다.
결과는 2번째 line이 "8>=Sat 25:00"에서 "9>=Sun 01:00"으로 바뀐 것을 볼 수있다.
CUBRID Cherry Release에서는 위와 같은 Rule record도 정상 처리될 것이다. (참조: RND-811)