
이틀 전 큐브리드닷컴 자유게시판에 "객체관계형데이터베이스는 왜 성공하지 못한건가요?"라는 제목으로 문의가 올라왔습니다. 처음에는 댓글 수준에서 간단하게 답변을 드릴까 했었는데 좀더 상세하게 설명을 드리는 것이 좋을 것 같아 정리를 해 보았습니다. 하지만, 제가 개발자나 엔지니어가 아니기 때문에 기술적인 관점보다는 전체적인 시장 관점에서 정리를 하였으며, 다른 시각 혹은 관점이 있을 수 있다는 전제하에서 출발을 하고자 합니다.
우선, 객체관계형(Object-Relational) 데이터베이스에 대해서 살펴보면, ORDB의 연구는 마이클 스톤브레이커 박사와 같은 선구자들에 의해 1980년대에 진행되었으며, 기존 관계형(Relational) 데이터베이스 개념에 객체 개념을 추가한 것입니다. 따라서, 객체지향형(Object-oriented) 데이터베이스와 달리 관계형 데이터베이스의 “편의성(표준 SQL 지원)과 성능을 계승”하고, 객체 개념을 통한 “모델링 장점”이 포함되어 있습니다.
1980년대의 리서치 이후 1990년 초중반에 상용화 제품들이 나오기 시작하는데, 대표적인 제품 중에 하나가 일러스트라(Illustra) - 일러스트라의 모태는 UC Berkeley의 Postgres 리서치 프로젝트이며, PostgreSQL 또한 Postgres에서 파생됨 - 입니다. 일러스트라는 90년대 중반에 인포믹스에 인수되어 “유니버셜 서버(Universal Server)”라는 제품명으로 마케팅이 되었고, 이 시기에 ORDBMS 제품에 대한 이슈가 가장 뜨거웠던 것으로 기억됩니다. (ShootingStar님이 언급해 주신 것처럼 “RDBMS 시장이 궁극적으로 ORDBMS로 바뀔 것이다”라는 전망이 있었던 시기임)
(여담: 인포믹스는 일러스트라를 인수하면서 4개의 DBMS 엔진을 보유하게 되었으며, 이를 지켜 본 당시 오라클 래리 앨리슨 회장이 거침없는 독설을 퍼 붓습니다. “한 개나 잘해”. ^^ 이후 인포믹스는 IBM에 인수되었습니다.)
한편, 오라클은 Oracle 7 이후 5년 만인 1997년에 Oracle 8을 출시하였는데, 키워드로 내세운 것 중 하나가 “SQL 객체 기술”입니다.
June 1997: Oracle 8 released with SQL object technology, Internet technology and support for terabytes of data (출처: http://en.wikipedia.org/wiki/Oracle_Corporation)
즉, Oracle 8부터 객체 개념을 지원하게 되었는데, 객체 개념을 지원한 제품은 인포믹스 유니버셜 서버 등 이미 시장에 존재하고 있었습니다. 즉, 오라클은 시장/기술 선도기업으로서의 평판을 유지해 나가고 있었는데, 객체 기술 관점에서는 후발이 된 것입니다. 아니나 다를까, 1년 뒤인 1998년에 iFS (Internet File System) 등의 기능을 추가한 Oracle 8i를 출시하면서 “인터넷 DBMS”로 제품을 재포지셔닝합니다. 물론, 90년대 말부터 시작된 닷컴 열풍의 시대적인 상황으로 마케팅 전략이 변경된 것이겠지만, 오라클 입장에서는 Oracle 8에서 전달했던 키 메시지의 당혹함(?)에서 가급적 빨리 탈출하고 싶었던 것 같습니다.
이후 1999년에 ANSI SQL:1999 (SQL3)에 객체지향 특성이 포함되었으며, 현재 대부분의 DBMS 제품들은 경중에 따라 객체지향 특성을 제공하고 있습니다. (오라클 웹사이트를 확인해 보면 자사의 제품을 ORDBMS라고 표현한 글을 볼 수 있음)
그러면, 지금부터 큐브리드 관련 이야기를 잠시 하도록 하겠습니다. 큐브리드의 태생은 ORDB이며, 객체지향 기능이 추가된 RDB입니다. (실질적으로 저장구조, 질의모델 등 모든 면에서 RDB를 포함하는 구조임) 하지만, 과거에 상당기간 "차별화" 마케팅을 통하여 다른 RDB에 없는 객체지향 기능을 부각시켰고, 이로 인하여, 오히려 RDB가 아닌 것 같다는 인식을 확산시키는 자승자박의 실수를 범했습니다. 하여 몇 년 전부터 의도적으로 ORDB라는 표현은 자제하고 그냥 RDB로 커뮤니케이션을 하고 있습니다. 또한, 제품 개발 관점에서도 RDB의 성능 및 기능을 향상시키기 위한 노력을 계속 경주해 왔습니다. (예로, 가장 최근에 출시된 CUBRID 2008 R2.1에 Hierarchical Query가 포함됨)
정리하면, 현재 RDB, ORDB를 구분하는 것 자체가 의미가 없는 것 같습니다. 태생이 RDB 제품들은 객체지향 기능을 수용했고, 처음부터 ORDB로 포지셔닝 했던 제품의 사용자 분들도 대부분 RDB를 기반으로 설계 및 구현을 하고 있기 때문입니다. 따라서, ORDBMS 시장점유율이 5%라는 것이 어떤 기준으로 도출되었는지는 모르겠습니다만 특별히 의미 부여를 할 필요는 없다는 판단입니다. 오히려 각 DBMS 제품이 지향하는 시장이 어디이고, 제품은 어떻게 포지셔닝하고 있고, 그 시장에서 요구하는 고객의 니즈를 어떻게 해결해 나가고 있는지를 들여봐 보는 것이 적합할 것 같습니다. 일례로, 사이베이스는 OLTP용 DBMS 제품인 ASE (Adaptive Server Enterprise)와 별도로 DW 전용 제품인 ASIQ (Adaptive Server IQ)가 있습니다. ASIQ는 DW 시장을 타깃팅하고 있고 상당한 성과를 이끌어 낸 것으로 알고 있습니다. (OLTP와 DW는 워크로드 자체가 완전히 틀림) 큐브리드 역시 “인터넷 서비스 최적의 DBMS”를 지향하고 있으며, 제품 경쟁력 제고를 통한 다양한 고객을 확보해 나가고 있습니다.
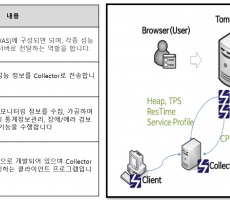
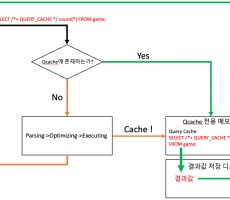
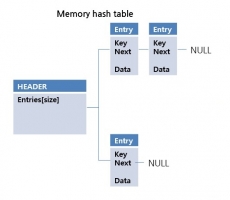
더 친숙하게 다가오는 듯합니다 ^ ^
'ORDB는 RDB의 확장이고, 큐브리드는 ORDB다'라고 인식했던 탓에 생소하게
느껴지던 부분이 정리되는 듯합니다. 말의 순서만 약간 다른데.. 생각이 바뀌네요
잘 읽었습니다~