얼마 전 큐브리드가 제품 다운로드 10만건을 돌파했다는 소식을 전하면서 지인으로부터 많은 격려와 축하를 받았다. 큐브리드가 한 일이라기 보다는 큐브리드를 사용하고 있는 사용자들이 축하를 받아야 하겠지만 어찌됐던 기쁜 일이 아닐 수 없다. 생각해 보면, 국산 소프트웨어로서 그것도 오픈소스 소프트웨어로서 일반 애플리케이션이나 솔루션이 아닌 DBMS라는 조금은 어렵고 제한적인 소프트웨어를 10만건씩 다운로드 했다는 것은 이례적인 일이 아닐 수 없다.
이러한 결과가 가능할 수 있었던 것은 로그인없이 어느 누구나 제품을 다운로드 할 수 있도록 한 정책덕분도 있겠지만, 큐브리드를 기반으로 한 다양한 오픈소스 소프트웨어와의 연동으로 더 많은 사용자를 확보한 덕분이라고 할 수 있다. 뿐만 아니라, 무료로 진행하는 큐브리드 교육뿐 아니라 실시간으로 제품에 대한 궁금증을 8시간안에 해결해 주는 온라인 기술지원도 있었기에 가능했을 것이다. 그러나 무엇보다 지속적인이고 주기적인 제품 업데이트가 없었다면 가능했을까?
이러한 주기적인 업데이트를 하기 위해 이미 해외를 중심으로 추후 버전에 포함되었으면 하는 기능과 성능에 대한 의견을 적극적으로 수렴하고 있다. 바로 http://cubrid.uservoice.com이다. 사실 DBMS도 일반적인 기능 이외에 회사나 개발자에 따라 요구하는 기능이나 성능이 다를 수 있다. 모두를 충족시킬수는 없지만 개발 일정을 고려해 포함 가능한 기능들은 중장기 계획을 가지고 포함을 시키고 있는 것이다.
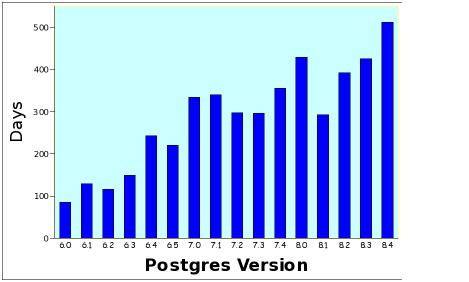
End Point's Blog에 따르면, PostgreSQL의 제품 릴리스는 버전 6이후부터 약 288일이 걸렸다고 한다. 버전 7을 릴리스하려면 367일, 버전 8을 릴리스하려면, 410일이 걸린다고 한다. 그러니까 의견 수렴을 한 신규 버전을 사용하려면 거의 1년 남짓을 기다려야하는 셈이다.
MySQL을 살펴보면, 최초 버전이1999년 1월 5일에 릴리스되었고 그 후 395일 이후인 2000년 6월 28일에 3.23버전이 릴리스 되었다. 공식 버전이 아니였음에도 불구하고 1년여 가까이 걸린 셈이다. 그 후 2001년 1월 17일 공식버전이 릴리스되었는데 결국 공식버전출시에 562일이 걸린셈이다. 4.0버전은 2003년 3월 15일에 출시되어 787일이 걸렸다. 메이저 버전인 5.0버전은 2005년 10월 19일에 출시되고 5.1버전은 1122일 이후인 2008년 11월 14일에 발표되었다. 이러한 MySQL의 릴리스 히스토리로 볼 때 버전 출시에 692일 그러니까 약 2년여가 걸리는 셈이다
큐브리드는 오픈소스화 선언이후부터 산정하는 것으로 하고 살펴보면,
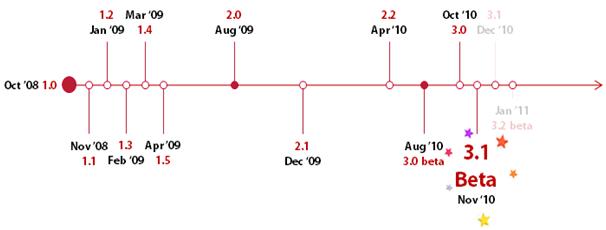
큐브리드 2008 R1.1버전이 2008년 11월 22일 공식 릴리스 된 이후, 55일 이후인 2009년 1월 16일 1.2버전이 릴리스 되었다. 1.3버전은 2009년 2월 2일, 1.4버전은 2009년 3월 12일, 1.5버전은 4월 16일에 각각 릴리스되었다. 메이저 버전인 2.0의 경우에는 2009년 8월 14일 릴리스 이후, 약 151일 이후인 12월 29일에 발표되었다. 2.2버전은 2010년 1월 19일, 2.2버전은 10월 4일 각각 릴리스되었다. 3.0베타 버전이 2010년 7월 19일 릴리스 된 이후, 157일이후에 2.2버전이 릴르스되고 3.0공식버전이 10월 5일 출시되어 베타버전 출시 75일만에 출시된 것이다. 이러한 릴리스 히스토리를 살펴보면 큐브리드는 평균 85일정도의 릴리스 주기를 갖게 된다.
즉, PostgreSQL은 9달에서 13개월정도의 릴리스주기를, MySQL은 약 2년의 릴리스 주기를, 큐브리드는 3개월 정도의 릴리스 주기를 갖고 있는 것이다.
릴리스 주기가 빠르다고 하여 좋은 제품이라 단언하기는 힘들다. 벤더마다 제품 전략이 다르고 기술이 다르며 조직체계가 다르기 때문에 릴리스 주기가 같은 수는 없지만, 제품의 릴리스 주기만을 놓고 본다면 큐브리드가 다른 경쟁제품에 비해 유연성에 있어 조금은 적극적이지 않나 싶다.
벌써 12월 한해도 열흘 남짓 남았다. 늘 이맘때가 되면 송년회다 비즈니스 리뷰에다 정신이 없지만, 집에 가는 발걸음에는 아련함과 쓸쓸함이 녹아 있기 마련이다. 한 해를 정리하면서 돌이켜보면, 큐브리드는 오픈소스 소프트웨어로서, 국산 DBMS로서 힘들고 험난한 여정이였음에도 불구하고 아쉬움과 미련보다는 가능성을 확인할 수 있는 시간이 아니였나싶다