이번 주에 셋째 아들(R1.4)이 릴리스되었다. 점점 더 릴리스가 손에 익어 가는 것 같지만, 아직 갈 길이 멀다. 5월이나 6월쯤의 상반기 메이저 버전이 릴리스되기 전에 릴리스가 내 손에 모두 익어야 할텐데, 만만치는 않은 것 같다.
제품 개발 사이클
CUBRID 2008 R1.3이 릴리스 되자마자 한숨 돌릴 틈도 없이 바로 서스테이닝(Sustaining) 이슈의 스펙을 정리해야 했다(서스테이닝=1차 생산 업무. NHN의 서스테이닝 부서=제품 양산 부서, LG전자 사업부). 일반적으로 개발자들은 릴리스가 되고 다음 릴리스를 준비하는 동안 아주 짧은 시간이지만 몸과 맘의 여유를 가지고 새로운 개발을 준비할 수 있다.
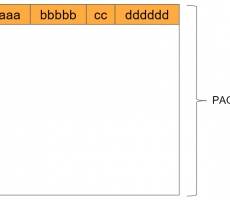
하지만 문서와 스펙을 담당하는 PM은 릴리스될 때는 매뉴얼과 릴리스 노트를, 릴리스를 준비할 때는 스펙을 작성해야 한다. (다음 그림을 보면, 릴리스 앞 뒤로 쉴 틈이 없다.)
스펙의 어려움
개발 담당자가 없는 스펙을 이번에 할당받았다. 이는
1. 스스로 해당 기능을 공부하고 정리한 뒤, 바뀔 방향에 대해서 주변 사람과 토의하여 결론을 내야 하고
2. CUBRID 오픈 소스 프로젝트 홈페이지(nFORGE)에 올려서 개발자들과 올바른 방향을 이끌어 내야 한다는 걸 의미한다.
3. 또한, 서스테이닝 스펙 개발은 짧은 시간에 정리하고 개발에 반영한다는 것도 내포하고 있다.
이런 내용 때문에 서스테이닝 스펙이 부담이 되는 것이고, 스펙 이슈 앞에만 서면 내가 작아지는 것 같다.
해당 이슈에 대해서 얼마나 공부하고 물어보면 적당한 것인지를 판단하는 것이 어렵다. 인터넷, 소스코드를 뒤져보면 알 수 있는 것인데, 개발자에게 물어봐서 성의가 없는 사람으로 비칠까 많이 두렵다. 물어보는 사람으로서 기본적인 예의는 갖추어야 대답하는 사람이 재미가 있을 것이다.
2개의 이슈를 받아서 팀장님을 비롯한 개발자를 괴롭혀서 1개는 해결했고, 1개는 아직도 미결인 상태로 있다. 이 글을 포스팅하고 나서 주변 개발자를 괴롭혀서 해결 상태로 바꾸어야겠다. :-)
CUBRID 64비트 버전 스펙
CUBRID는 올 해에 두 번의 변신을 준비하고 있는데, 64비트 버전과 HA 버전의 출시이다.(CUBRID 오픈 소스 프로젝트의 WIKI에서 로드맵) 64비트 버전의 스펙은 알맹이만 담고 있기 때문에 개발자들을 제외하고는 이해하기가 어렵다. 그래서 나의 손길을 기다리고 있다. 나 스스로 PM이라고 인정하기 위해서는 뭔가 큰 건의 스펙을 써야만 하기 때문에 내가 자원하였다. 내 본래 업무를 제쳐두고, 잠깐 편하자고 후방에만 있으면 앞으로 계속 자신감을 가질 수 없을 것이란 생각이 들었다. 로마의 카이사르도 루비콘 강을 건너지 않았다면 로마의 수많은 장군 중의 한 명이 되지 않았겠는가?
용기는 내었는데 역시나 내 주변의 정리되지 않은 일(매뉴얼의 리뉴얼, CUBRID 오픈 소스 프로젝트의 nFORGE 개편, …)에 끌려 다니다가 보니 아직 3페이지를 넘어가지 못하고 있다. 다음 주부터는 좀 더 시간을 투입하여, 스펙의 큰 가닥이 잡히도록 해야겠다. 내가 쓴 스펙이 사람들에게 읽힌다니, 얼마나 가슴 두근거리는 일인가?
나는 게으른 PM?
릴리스 노트를 적을 때만 되면 나는 부지런한 PM과 게으른 PM 사이에서 갈등을 한다. 게으른 PM이라면 개발자들에게 자세한 초안을 요구해야 하고, 부지런한 PM이라면 개발자들의 간단한 메모와 이슈 트래커의 내용을 참고하여 릴리스 노트를 적을 것이다. 이슈 트래커에 적힌 많은 내용을 보고 핵심적인 부분이 뭔지를 짧은 시간에 알아내는 것은 쉬운 일이 아니다. 오랜 경험과 코드 리뷰 참여가 없이는 불가능하다고 봐야 한다.
1명이 커버할 수 있는 범위가 한정이 있으므로, 절충안으로 개발자가 간단한 초안을 만들면 PM이 완전한 문구를 만들어 내는 방법을 도입하였다. 릴리스 노트에 정성을 들이는 개발자가 흔치는 않기 때문에 계속 개발자를 압박해야 하는데, 개발자들은 PM이 할 일이 아닌가라고 반발하는 경우가 있다. PM이 릴리스 노트와 스펙만 담당하는 게 아니기 때문에 글 쓰는 노력을 줄여야 한다. PM은 문장을 검사하는 문지기가 되고, 해결된 이슈가 PM이라는 문만 통과하면 릴리스 노트는 자동으로 생성되는 프로세스를 상상해 본다. 이게 되려면 개발에 참여하는 모든 사람이 동의하고 적극적으로 참여해야 할 것이다.
이슈 트래커의 어려움
이슈 트래커는 SW 개발 과정에서 버전 관리 시스템과 더불어 핵심적인 기능을 담당한다.(관련 URL: http://en.wikipedia.org/wiki/Issue_tracking_system, http://www.ibm.com/developerworks/kr/library/s_issue/20071127/) 사실 회사에 다니면서 이슈 트래커의 편리함에 왜 이런 걸 진작에 사용하지 않았을까 하는 생각을 할 때가 있다.
개발 중 발생하는 모든 커뮤니케이션을 메일이 아니라 이슈 트래커를 이용하기로 결정했다. 이슈 트래커를 사용하면 업무 히스토리가 개인의 메일함에 저장되는 것이 아니라 시스템에 저장되기 때문에 시간이 많이 지난 뒤에도 정보를 사용할 수 있다, 그런데 메일에서 쓰던 방식으로 커뮤니케이션을 하게 되니, 이슈 트래커는 단순한 텍스트이기 때문에 중요한 내용을 표시할 수도 없고 찾기도 굉장히 어렵게 되었다. 그래서 이슈로 등록한 매뉴얼 수정 내용을 처리하는 것이 단순히 바뀐 내용을 찾던 것에서 이슈 트래커를 쫓아서 내용을 검수해야 하니까 시간 투입이 굉장히 많이 되었다.
이슈 트래커 같은 시스템은 사람이 하는 일을 줄여주어야 하는데 매뉴얼 개정 작업에서는 오히려 일이 늘어났고, 프로세스는 초심자가 품질 높은 결과를 만들어 내야 하는데 초심자가 붙어서는 일을 할 수 없게 된 것이다. 이슈 트래커를 활용해서 매뉴얼 개선 작업의 프로세스를 어떻게 손을 봐야할 지 고민이다.
초보 PM의 티를 빨리 벗고 싶은데, 어떤 일에 능숙해지면 “초보”라는 글자 두 개를 뗄 수 있을까?