조인 방법(Join Method) 설명.
2009-12-23 컨설팅팀, CUBRID
적용 대상: CUBRID
본 문서는 아래와 같은 환경에서 테스트 되었다.
CUBRID R1.0 이상
Join Method 개요
CUBRID 에서 지원하는 Join Method에는 두가지가 있다.
중첩 반복 조인 ( Nested Loop Join )
정렬 병합 조인 ( Sort Merge Join )
대부분의 DBMS도 마찬가지로 두가지 종류의 Join Method를 지원하고 있으며 타 DBMS의 경우 부가적으로 Hash Join 기능을 제공하기도 한다. CUBRID 의 경우 인터넷 서비스에 유리한 중첩 반복 조인(NLJ) 을 사용하는 것이 정렬 병합 조인( Sort Merge Join ) 이나 해쉬 조인( Hash Join ) 을 사용하는 것보다 OLTP 성 온라인 서비스를 하는 경우에 적합하다고 할수 있다.
Join Method 비교
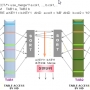
중첩 반복 조인의 경우 다음과 같은 로직으로 실행 된다. NLJ 특성상 OLTP성 서비스에 유리하다.
For each tuple in R as r do
For each tuple in S as s do
If r and s satisfy the join condition
Then output the tuple <r,s>

2) 특징 정리
|
특징 |
설명 |
|
순차적 |
두 테이블간의 연결 및 최종 운반 단위 산출까지 순차적으로 진행 된다. |
|
선행적 |
선행(Driving) 테이블의 처리 범위가 전체 일의 양을 결정 한다. 즉, 후행(Driven) 테이블의 경우 선행 테이블의 처리 범위가 적을수록 비교해야 하는 범위가 줄어 든다고 할 수 있다. |
|
종속적 |
후행(Driven) 테이블의 경우 선행 테이블의 결과를 받아서 처리 결과를 만들게 된다. 즉, 선행테이블의 범위에 영향을 크게 받는다. |
|
연결 고리의 중요성 |
선행 테이블과 후행 테이블간에 연결 고리 (인덱스)가 있는 경우와 없는 경우간의 성능 차이가 크다. |
|
부분 범위 처리 |
NLJ 특성상 부분범위 처리에 유리 하다. |
3) 고려 사항
l 조인에 사용된 인덱스 구성을 고려해야 한다. 여러 개의 테이블이 조인 수행 시 연결고리의 인덱스 가용 여부에 영향을 받는다.
l 선행 테이블(Driving Table) 의 영향을 크게 받으므로 선행 테이블 선정이 매우 중요 하다.
l 대부분이 OLTP성 질의에 사용되며 부분 범위 처리가 될 수 있도록 조건 절에 유의 하여 사용한다.
l 전체 범위 처리가 될 경우 RANDOM I/O 가 많아져 오히려 더 늦을 수 있다.
정렬 병합 조인(Sort Merge Join) 의 경우 좌, 우변의 조건을 만족하는 조건을 Sequential I/O를 사용하여 결과셋을 만든 후 좌, 우변 key 값으로 비교하여 merge 하는 방식을 사용한다. 좌우 변의 결과 셋이 클 경우 ($CUBRID/conf/cubrid.conf 파일의 sort_buffer_pages 에 설정한 page 보다 결과 셋이 큰 경우를 뜻함) TEMP volume을 사용하며 성능상의 문제가 발생할 수 있다. 일반적으로 정렬 병합 조인의 경우 OLTP성 질의 보다는 배치성 통계 작업에 유리 하다.

CSQL 을 사용한 정렬 병합 조인 플랜 생성 예)
csql>;set level 514
csql> select /*+ USE_MERGE ( tab1 tab2 ) */ tab2.col1 from tab2 , tab3 where to_number(tab2.col1) = tab3.col1 and tab2.col1 > '5000' and tab3.col1 > 3000;
csql> ;x
Join graph segments (f indicates final):
seg[0]: [0]
seg[1]: col1[0] (f)
seg[2]: [1]
seg[3]: col1[1]
Join graph nodes:
node[0]: tab2 tab2(10000/224) (sargs 2)
node[1]: tab3 tab3(10000/201) (sargs 1)
Join graph equivalence classes:
eqclass[0]: term[0]
Join graph edges:
term[0]: tab3.col1= to_number(tab2.col1) (sel 0.0001) (rank 3) (join term) (mergeable) (inner-join) (indexable col1[1]) (loc 0)
Join graph terms:
term[1]: tab3.col1 range (3000 gt_inf max) (sel 0.1) (rank 2) (sarg term) (not-join eligible) (indexable col1[1]) (loc 0)
term[2]: tab2.col1 range ('5000' gt_inf max) (sel 0.1) (rank 2) (sarg term) (not-join eligible) (indexable col1[0]) (loc 0)
Query plan:
temp
order: UNORDERED
subplan: m-join (inner join)
edge: term[0]
outer: temp
order: phony (term[0])
subplan: iscan
class: tab2 node[0]
index: pk_tab2_col1_col2 term[2]
cost: fixed 30(0.0/30.0) var 19(3.0/16.0) card 1000
cost: fixed 79(8.0/70.9) var 6(2.5/3.9) card 1000
inner: temp
order: phony (term[0])
subplan: iscan
class: tab3 node[1]
index: pk_tab3_col1_col2 term[1]
cost: fixed 28(0.0/28.0) var 18(3.0/15.0) card 1000
cost: fixed 76(8.0/67.9) var 6(2.5/3.9) card 1000
cost: fixed 155(16.0/138.8) var 638(630.0/7.8) card 100
cost: fixed 798(651.0/146.6) var 1(0.2/1.0) card 100
Query stmt:
select /*+ USE_MERGE */ tab2.col1 from tab2 tab2, tab3 tab3 where tab3.col1= to_number(tab2.col1) and (tab2.col1> ?:0 ) and (tab3.col1> ?:1 )
|
동시적 |
Nested Loops 조인에서는 한쪽 테이블이 읽혀져야(선행 테이블) 후행 테이블을 액세스 할 수 있다. 즉, 순차적으로 액세스 되었다. 하지만, 이 조인 방식은 양쪽 테이블을 동시에 읽고 양쪽 테이블이 조인할 준비가 되었을 때 조인을 시작한다. |
|
독립적 |
NLJ 과 같이 선행 테이블의 처리 결과와 상관 없이 SMJ의 경우 각자 테이블이 가지고 있는 필터링 조건이 실행 성능에 큰 영향을 미친다. |
|
전체 범위 처리 |
정렬 작업이 완료된 이후에 처리 되므로 부분 범위 처리가 이루어 지지 않는다. |
|
연결 고리 |
SMJ의 경우 연결고리 보다는 각자가 가지고 있는 필터링 조건(상수) 의 영향을 받는다. |
|
부분 범위 처리 |
SMJ 의 경우 소트하여 처리한 후에 결과셋을 만드는 작업을 하므로 부분 범위 처리 되지 않으며 일반적으로 통계성 작업이나 배치(Batch) 작업에 주로 사용된다. |
l 통계 작업이나 배치성 작업 처럼 처리량이 많은 질의에 사용 한다.
l 대량 Sort 작업시 TEMP Volume을 사용하므로 OLTP성 업무에 적당하지 않다.
대용량 데이터 베이스 솔루션 1권
새로쓴 대용량 데이터 베이스 솔루션