* 질문 등록 시 다음의 내용을 꼭 기입하여 주세요.
|
|
Rocky Linux 8.10 |
|
|
Cubrid 11.4 |
|
|
[도움말]-[버전정보] 확인 |
|
|
K8s, Spring Boot |
* CUBRID 응용 오류, SQL 오류 또는 SQL 튜닝 관련된 문의는 반드시 다음의 내용을 추가해 주세요. 비밀글이나 비밀 댓글도 가능합니다.
* 저희가 상황을 이해하고, 재현이 가능해야 알 수 있는 문제들이 많습니다. 가능한 정보/정황들을 부탁합니다.
| 에러 내용 및 재현 방법 | 재현 가능한 Source와 SQL |
| 관련 테이블(인덱스, 키정보 포함) 정보 | CUBRID 홈 디렉토리 아래 log 디렉토리 압축 |
-------------- 아래에 질문 사항을 기입해 주세요. ------------------------------------------------------------------------
아래 로그와 같이 max_client에 도달하여 접속에 실패하여
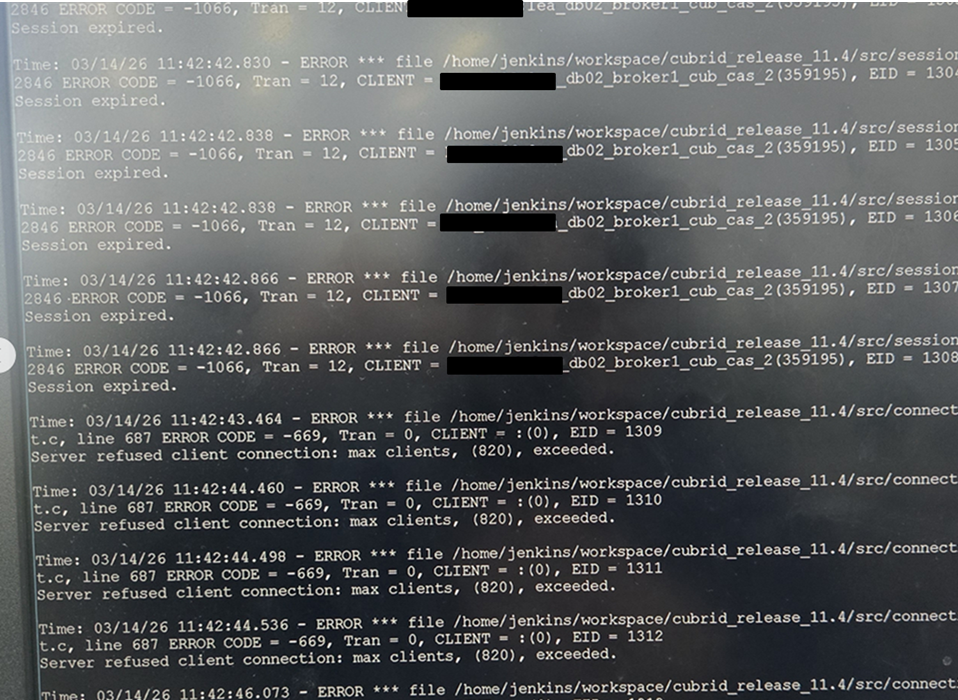
HA환경에서 DB2번으로 정상적으로 failover가 되는 현상이 있습니다.
※ OS에 대한 리소스(CPU, Memory, Disk)는 정상
Application 환경은 Kubenetes의 Pod(Spring Boot) 및 일부 VM이 DB쪽으로 커넥션을 맺고 있는 상태입니다.
- DB 서버에 설정된 max_client = 820
- Spring Boot Connection Pool 최대치 총합 = 240 + @ (300이하임)
위 결과로 보아 커넥션이 맺어지는 수치는 문제는 없어 보입니다. 그리고 브로커 idle 상태도 정상적입니다.
다만, Kubenetes의 Pod가 배포되는 과정에서 기존 Connection이 유지가 된 상태에서 재배포가 되어
Connection Pool에 대한 반납이 제대로 일어나지 않아 누수가 발생하는 것으로 추측은 되는데요
1. max_client에 대한 현황을 확인 할 수 있는 명령어가 없는지요?
ex) 현재 client 수, 어디서 pool을 맺고 있는지
2. DB나 Hikari 설정에서 Connection Pool 반납 또는 누수 방지에 대한 설정이 있을까요?
3. failover 이후 slave였던 DB2서버가 master로 승격 됐을 때 기존 DB1 맺어져 있는 Connection들도 이를 감지하고 새로운 Connection을 맺도록 하는 설정이 있나요?




