
무중단 서비스를 위한 DB 서버 이중화 구축
죽지 않아야 한다. 날리지 말아야 한다. 빨라야 한다.
* 본 게시글은 월간 마이크로소프트웨어 7월호에 게재된 내용입니다.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
오보명 obm@nhn.com | NHN Business Platform 서비스 플랫폼 개발 센터에서 플랫폼 확산 업무 및 오픈소스 라이선스 컨설팅 업무를 담당하고 있다. 4년 전 CUBRID라는 국산 DBMS와 인연을 맺은 이후, CUBRID 의 국내/해외 확산 업무를 담당하고 있으며 CUBRID 글로벌 커뮤니티 사이트(http://cubrid.org)를 운영하면서 전세계 개발자들과 소통하고 있다.
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2011년 6월 17일(금) 자정 00:00부터 오전 09:30분까지 국내 홈쇼핑 선두 업체의 쇼핑 사이트가 시스템 점검을 이유로 서비스 운영을 일시 중단했다. 해당 업체의 2010년 매출액과 온라인 쇼핑 매출 비율(30%)을 고려할 때, 1시간 당 매출액은 약 2,700만원이고, 9.5시간 동안 올릴 수 있는 매출액은 약 2억 5천만 원에 이른다. 물론, 대부분 고객들이 잠을 자는 시간이어서 실제 손실액은 훨씬 적었을 것이다. 당일 필자는 에어컨 가격을 알아보고 있었는데, 결국 다른 쇼핑 사이트에서 이를 구매했다. 서비스가 죽지 않아야 하는 이유? 바로 매출과 직결되기 때문이다.
왜 서비스는 중단되는가?
서비스 중단의 유형은 원인에 따라 크게 두 가지로 구분할 수 있다. 운영자가 예측하지 못한 장애 상황이 발생한 경우, 그리고 운영자가 의도적으로 서비스를 중단하고 시스템 점검과 같은 상시 운영 업무를 처리하는 경우이다. 이때 문제가 되는 것은 전자의 경우이다. 천재지변, 네트워크 단절, 운영 서버 리소스의 과다 사용, 하드웨어 고장 등의 이유로 장애가 발생하는 경우, 운영자가 원인을 판단하고 서비스를 정상 복구하기까지 상당한 시간이 소요되기 마련이다. 후자의 경우는 다행히 작업 시간을 미리 예측할 수 있지만, 사용자 방문이 가장 적은 새벽에 점검 작업을 수행하여야 하므로 운영자는 늘 피곤할 수 밖에 없다. 근본적으로 피곤은 “간” 때문이기는 하지만, 운영자의 피곤을 줄일 수 있는 확실한 방법은 바로 HA(High Availability) 시스템 구축이다.
서비스에 적합한 HA 솔루션 선택
서비스 가용성을 높이기 위한 방안으로 DBMS벤더들은 각각 다양한 방식으로 HA 솔루션을 지원한다. 아래 표는 각 제품 별 특징을 요약한 것이다.
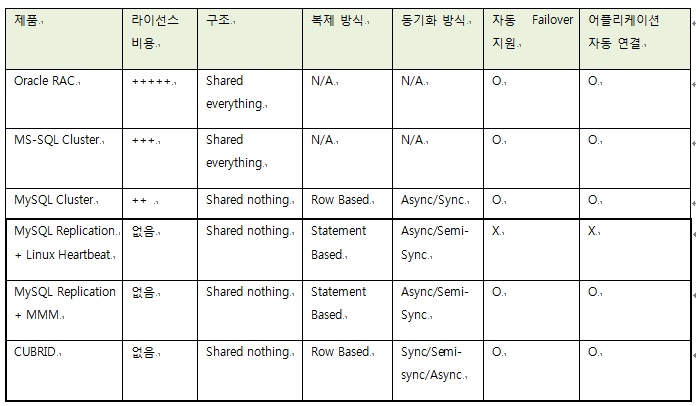
표 1. 제품별 HA 솔루션의 특징 요약
Oracle RAC 및 MS-SQL Cluster는 공유 스토리지 기반의 구조를 따르고 있으며, MySQL과 CUBRID는 복제(Replication)을 사용하여 데이터베이스를 여러 대의 서버에 분산하는 구조를 채택하고 있다. 그 외에도 마스터/슬레이브 데이터베이스 간 동기화 방식과 복제 방식, 자동 절체(Auto-Failover) 기능의 유무, Failover 이후 어플리케이션의 자동 연결 여부 등 제품마다 동작 방식, 지원 기능 및 구축 비용이 매우 상이하다. 운영자는 예산, 서비스 규모 및 부하 패턴을 고려하여 적합한 솔루션을 채택할 수 있다.
지금부터는 비용 부담 없이 공개된 매뉴얼만으로 쉽게 고가용성 시스템을 구축할 수 있는 MySQL과 CUBRID에 대해 더욱 상세히 살펴보고자 한다.
목표 1. 죽지 말아야 한다.
웹 서비스 제공자는 누구나 서비스 가용성이 100%이기를 바랄 것이다. “서비스는 죽지 말아야 한다”는 목표를 달성하기 위해서는 데이터베이스 서버의 죽음을 미리 대비하고, 죽음을 반드시 알려야 한다. 이를 위해 CUBRID HA는 아래와 같은 기능을 제공한다.
• DB 서버 다중화 구성
• 복제 기반의 데이터베이스 동기화
• 장애 감지 및 Failover
1) DB 다중화 구성
CUBRID HA는 읽기/쓰기 부하를 담당하는 마스터 노드, 장애 시 마스터 기능을 대체하는 슬레이브 노드, 읽기 부하 분산을 담당할 수 있는 복제 노드를 조합하여 다양하게 구성할 수 있다. 아래는 CUBRID HA 구성의 예이다.
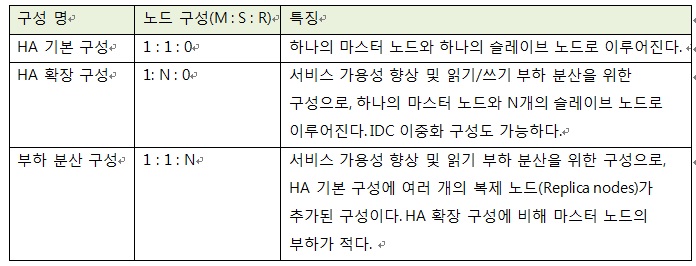
표 2. CUBRID HA 구성의 예시
아래 그림처럼 CUBRID HA 기본 구성을 한 후, 마스터 서버에 장애가 감지되면, 브로커 미들웨어가 등록된 슬레이브 DB 서버의 상태를 확인하여 연결을 수립한 후, 사용자 요청(읽기/쓰기)을 처리한다. 만약, 브로커 서버와 DB 서버를 각각 분리한 구성에서 브로커 서버에 장애가 감지되면, 마찬가지로 인터페이스(JDBC, PHP, CCI 등)에 등록된 2차 브로커 서버의 상태를 확인하고 연결을 수립한다.
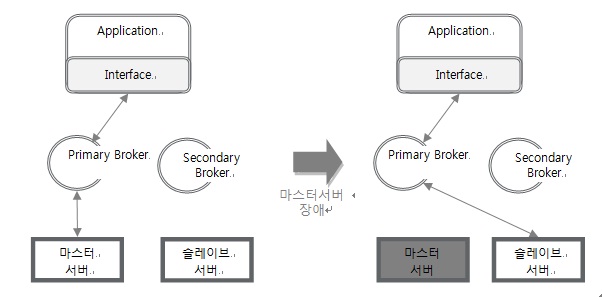
그림 1. CUBRID HA 구성에서 마스터 장애 시 Failover
MySQL 기반의 HA 환경을 무료로 구성하는 대표적인 방법으로는 1) MySQL 복제와 Linux Heartbeat 패키지를 사용, 2) MySQL 복제와 MMM(Master-Master Replication Manager) 솔루션을 사용하는 것이다. 1)은 운영 편의성 측면에서 매우 취약한 구성인데 이유는 마스터 DB 서버에서 장애가 감지되더라도 운영자가 수동으로 Failover를 하고, 슬레이브 DB 서버와 연결되도록 어플리케이션의 연결 정보를 수동으로 갱신하여야 하기 때문이다. 한편, 2)의 경우는 CUBRID와 마찬가지로 자동 Failover 및 어플리케이션 자동 연결 기능이 지원된다.
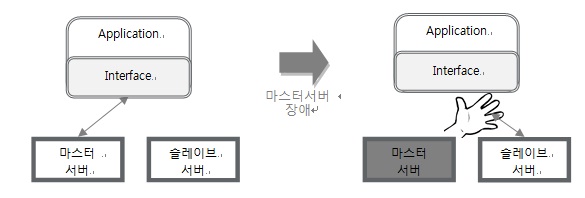
그림 2. MySQL 복제+ Linux HB 구성에서 마스터 장애 시 Failover
2) 복제 기반의 데이터베이스 동기화
CUBRID와 MySQL는 데이터베이스 동기화를 위해 복제 기법을 사용하지만, 복제의 동작 방식이 서로 다르다. CUBRID는 마스터 노드에서 데이터(row)의 변경 사항을 로깅하여 이를 복제하는 row-based 복제 기법을 사용하고, MySQL은 마스터에서 수행된 SQL 문을 그대로 로깅하여 복제하는 statement-based 복제 기법을 사용한다. Row-based 복제는 마스터의 모든 변경 사항에 대해 복제할 수 있고 보다 적은 LOCK을 사용하게 되어 동시성이 높다는 장점이 있다. 한편, statement-based 복제는 슬레이브로 SQL문만 복제하므로 마스터 서버에 부하를 덜 주지만 마스터와 슬레이브 사이에 데이터베이스 불일치가 발생할 수 있다.
그림 3은 CUBRID HA 구성에서 복제 방식을 나타낸 것이다. 마스터 노드에서 데이터가 변경되면 트랜잭션 로그와 복제 로그가 슬레이브 노드로 복사 및 반영되면서 마스터 및 슬레이브 데이터베이스가 동기화된다.
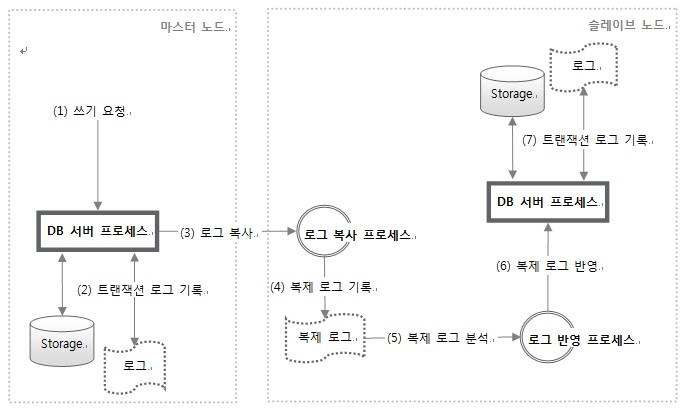
그림 3. CUBRID Row-based 복제 방식
3) 장애 감지 및 Failover
CUBRID는 HA 기능이 구현되었던 초기 버전(2008 R2.1이하 버전)에서는 MySQL HA와 마찬가지로 Linux Heartbeat 패키지를 사용하여 노드 상태를 감지하였으나, NHN 내/외부 서비스에 CUBRID HA 적용 후 Linux Heartbeat 패키지의 불안정한 문제들(예: 부정확한 장애 감지로 인해 원치 않는 failover 발생)과 설정의 어려움이 있어, 이후 버전부터는 자체 구현한 CUBRID Heartbeat을 내장하고 있다.
CUBRID HA로 구성된 모든 노드들은 네트워크를 통해 heartbeat 메시지를 주고 받으며 자신을 제외한 노드의 상태를 감시한다. 만일, 일정 시간 동안 특정 노드로부터 heartbeat 메시지를 수신하지 못하게 되면, 해당 노드에 장애가 발생한 것으로 판단한다.
만약, 마스터 노드에서 장애가 발생하면 즉시 구성 정보와 다른 노드들의 상태 정보를 조합하여 슬레이브 노드 중 마스터가 될 수 있는 후보 노드를 선택하고 이 노드에서 쓰기 연산이 가능하도록 해당 노드의 역할을 변경하기 위한 Failover를 수행한다.
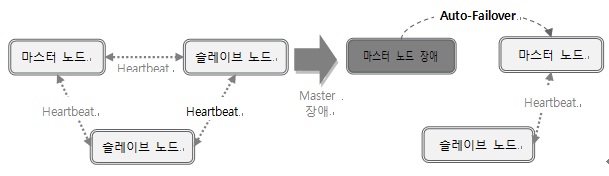
그림 4. CUBRID Heartbeat에 의한 장애 감지와 Auto-Failover
목표 2. 날리지 말아야 한다.
목표 1을 달성했다고 하여 모든 문제가 해결된 것은 아니다. 만약, 장애가 발생한 순간의 트랜잭션이 정상적으로 반영되지 않거나, 마스터 노드와 슬레이브 노드 간 데이터베이스 불일치가 발생한다면 어떻게 될까? 쓰기 연산이 비교적 많은 SNS또는 메신저 사용자라면 누구나 겪었을 경험, 열심히 글을 입력했는데 그 글이 보이지 않는 황당함을 서비스 고객이 겪을 수도 있다.
“날리지 말아야 한다”는 목표를 달성하기 위해 CUBRID HA는 세가지 동기화 모드를 지원하며, 운영자는 서비스 유형에 따라 적절한 모드를 설정할 수 있다.
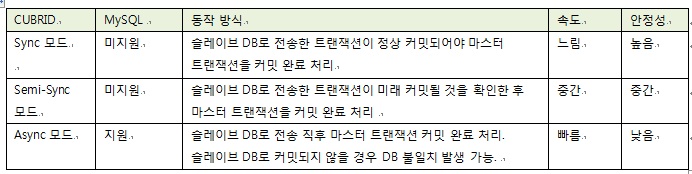
표 3. CUBRID HA의 동기화 모드 비교
목표 3. 빨라야 한다.
목표 1, 목표 2를 달성했다고 해도 여전히 남은 문제, 바로 HA 성능이다. 장애 발생 시점부터 서비스가 정상화될 때까지의 소요 시간을 최소화하기 위해서는, 1) 복제 지연 최소화, 2) 신속한 장애 감지, 3) 가용한 슬레이브 노드로 Failover 수행, 4) 어플리케이션이 슬레이브 노드로 즉시 연결 등 일련의 과정들이 신속 정확하게 수행되어야 한다. 그래야만 서비스 고객들이 순간의 서비스 중단을 눈치채지 못할 것이다.
1) HA 환경에서의 복제 지연 테스트
서비스 가용성과 안정성을 향상시키기 위하여 HA 솔루션을 도입할 때 반드시 고려해야 할 반대 급부가 바로 성능이다. HA 환경에서는 슬레이브 노드로 복제를 수행하므로 마스터 노드에 부하가 증가한다. 또한, 데이터 무결성을 보장하기 위하여 HA 동작 모드를 동기 모드(sync mode)로 설정한 경우, 비동기 모드(async mode)에 비해 마스터 노드에 부하가 증가한다. 문제는 이러한 복제 지연이 “얼마나” 실제 서비스에 영향을 주느냐인데, 이를 검증하기 위하여 간단한 테스트를 수행하였다.
마스터 노드 1개와 슬레이브 노드 1개로 구성된 HA 환경을 구축하고, 테이블 1개에 일정 개수의 레코드가 축적될 때까지 100% INSERT 연산을 수행하는 테스트이다. 일반 환경, HA환경(Async모드), HA 환경(Sync 모드)에서 각각 테스트를 수행하였다.
(CPU: Xeon(R) CPU 3065 @ 2.33GHz, Memory: 4G, OS: Linux CentOS 2.6.18, CUBRID 2008 4.0.0233, MySQL 5.5.11)
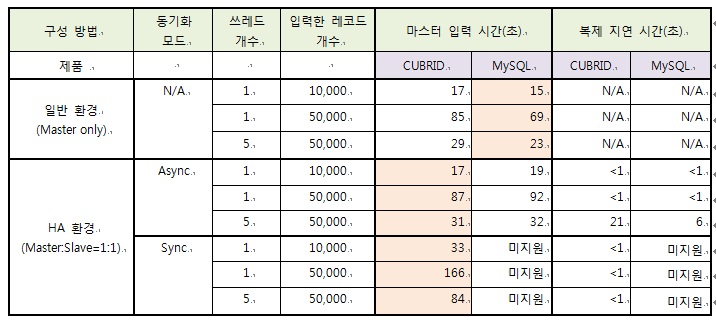
최신 버전의 CUBRID과, MySQL을 적용하여 테스트한 결과, 일반 환경에서는 MySQL의 입력 성능이 평균 20% 더 높지만, HA 환경(Async모드)을 구성했을 때는 CUBRID의 입력 성능이 평균 9% 더 높았다. 또한, HA 환경(Sync모드)을 구성했을 때는 슬레이브 노드에서 트랜잭션이 커밋된 이후에 마스터 노드에서 트랜잭션을 완료 처리하므로 Async일 때보다 약 2배의 시간이 소요되나, 복제 지연은 거의 없는 것으로 확인되었다. 단, 서비스 부하 패턴 및 장애 발생 시점의 복제 데이터 양에 따라 테스트 결과는 상이할 수 있음을 고려하여야 한다.
2) Failover 테스트
서비스 운영 중에 자주 발생되는 장애 유형을 6가지로 분류하고, 각 장애 상황에서 CUBRID HA가 성공적으로 Failover를 수행하는지에 관한 테스트이다. 덧글을 입력할 수 있는 게시판 어플리케이션에서 30개의 동시 쓰레드가 QPS 700 수준의 쓰기 및 읽기 연산을 수행하는 도중 장애가 발생하는 시나리오이다. 단, Failover 시간 및 TPS가 정상화되는데 소요되는 총 시간은 서비스 부하 패턴 및 장애 발생 시점의 복제 데이터 양에 따라 상이할 수 있음을 고려하여야 한다.
(CPU: 4 core * Xeon(R) CPU X3350 @ 2.66GHz, Memory: 4G, OS: Linux CentOS 2.6.18, CUBRID R2.2 Patch 9)
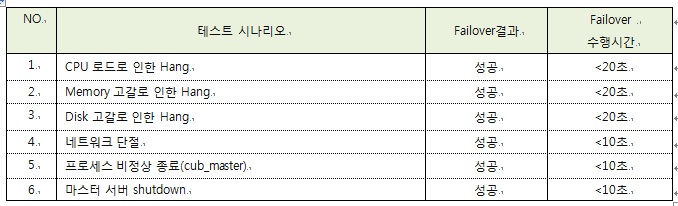
표 4. CUBRID HA의 Failover 성능 테스트 결과
결론. 궂은 날 빛나리라.
지금까지 DB 서버 이중화 구축을 위한 각 제품별 HA 솔루션의 특징을 살펴보고, 비용 고민 없이 도입할 수 있는 오픈소스 제품인 MySQL과 CUBRID의 HA 의 동작 방식과 특징, 그리고 성능을 세가지 목표 관점에서 검토해 보았다.
만약, HA 시스템을 구축할 계획이 있다면 이것만은 명심하자. 걱정 없이 슬레이브 데이터베이스에 실시간 백업(hot backup)을 걸 수 있는 날, 서버 장비가 갑자기 고장 나도 서비스가 중단 없이 운영되는 날, 근무 시간 동안 DB 엔진 버전 업그레이드 작업을 완료하고 퇴근하는 날, 그 날은 온다는 것을.
참고문헌
[1] High Availability, http://en.wikipedia.org/wiki/High_availability, Wikipedia
[2] Failover, http://en.wikipedia.org/wiki/Failover, Wikipedia
[3] Shared Nothing Architecture, http://en.wikipedia.org/wiki/Shared_nothing_architecture, Wikipedia
[4] Oracle Database High Availability, http://www.oracle.com/technetwork/database/features/availability/index.html
[5] Database Mirroring in SQL Server 2005, http://technet.microsoft.com/en-us/library/cc917680.aspx
[6] MySQL HA/Scalability, http://dev.mysql.com/doc/mysql-ha-scalability/en/index.html
[7] CUBRID 4.0 매뉴얼, http://www.cubrid.com/manual/840/index.htm

좋은 글 감사합니다.
좋은 하루 만드세요
:-)