CUBRID 10은 새로운 기능이 추가 되었습니다. 그 중에서 문자열 압축기능이 추가되었습니다.
지금부터 문자열 압축 기능에 대해서 알아보도록 하겠습니다.
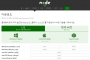
문자열 압축 기능은 아래의 표와 같습니다.

CUBRID 문자열 압축은 255byte
이상에서만 실행되고, 압축이 효율적이지 않으면 압축을 실행하지 않습니다.
문자열 압축률이 얼마나 좋은지 테스트하기 위해서 문자열 압축 기능이 없는 CUBRID 9.3과 10.1에서 테스트 데이타 10만건을 입력하고, 테이블 크기를 확인하는 방법으로 진행하였습니다.
“케이스 #1”은 중복 되지 않는 문자열 데이타를 입력하고 압축률을 확인하였고, “케이스 #2”는 중복 된 데이타를 입력하고 압축률을 확인하였습니다.

각 케이스별로 데이타 10만건을 생성한 방법은 아래 표와 같습니다.
먼저 테스트 데이타 1건을 입력하고, “insert 테이블 select ...” 구문에서 카탈로그 테이블과 카테시안 곱(Cartesian Product)을 활용하여 테스트 데이타를 생성하였습니다.

위 표의 SQL문으로 데이타 10만건을 입력하고 테이블 크기를 확인하였습다.
테이블 크기는 “show heap capacity of 테이블명;” 명령을 실행하고
Num_pages 값을 확인하였고, 결과는 아래 표와 같습니다.

“케이스 #1”의 중복되지 않은 문자열의 데이타를 입력하고 확인 한 “Num_pages”의 결과는 동일하였습니다.
이유는 입력되는 데이타의 압축결과가 원래값과
동일하기 때문에 압축을 실행하지 않았고, Data도 원본 데이타를 입력했기 때문에 동일한 것입니다.
“케이스 #2” 에서는
중복 된 데이타가 입력되어 압축률이 938% 로 처리되었습니다.
CUBRID 10 문자열 압축기능에서 압축 된 문자열을 푸는 시점은 “데이터베이스에서 읽을 때 압축된 문자열을 해제”한다고 하였습니다.
그러면 “데이타 추출 하는 시간은 얼마나 차이가 날까?”라는 의문점이 생길
것입니다.
위 질문에 대한 결과를 얻기 위해서 아래와 같은 스크립트를 작성하고, 테스트를
진행하였습니다.
아래 스크립트는, 실행할 SQL문을 파라미터로 받아서 SQL문을 실행하고 결과를 resut_sql.txt에 기록하고, 실행 전 시간에서 완료시간을 뺀
값을 출력하는 스크립트입니다.

스크립트는 아래와 같이 실행하였습니다.
![]()
사내 테스트서버 장비에서의 50만건 추출에 대한 소요시간은 아래와 같이 측정되었습니다.
아래의 측정시간은 절대적인 수치는 아니며 장비의 성능, OS설정, 스토리지 IO 성능
등에 따라서 변경 될 수 있습니다.

CUBRID 9.3에서 10만건의 데이타를 추출하는데 소요된 시간은 1.04317초 였고, 10.1은 0.848578초 였습니다.
시간차이는 -0.194592초였습니다.
즉, 압축된 501byte 데이타
10만건에 대해서 압축을 해제하여 추출하는데 처리속도가 -0.19초
빠르게 나타난 것입니다.
문자열 압축에 대한 테스트 결과를 정리하면, DISK에 저장 되는 용량은 9.3에서는 57 MB( 3,704 * 페이지크기 16K )였고,
10.1에서는 5 MB( 357 * 페이지크기 16K )를 사용 하였습니다.
처리시간은 0.19초 빨라졌습니다.
CUBRID 10에서 추가 된
문자열 압축기능은 디스크 사용량은 줄이고, 처리성능은 높아졌습니다.