SQL을 수행하다 보면 SLOW SQL이 많이 발생합니다.
이럴때, 해당 SQL의 실행계획을 확인 함으로써, 지연을 발생시키는 부분을 쉽게 찾을 수 있습니다.
1. SQL 서식화.
- 보통 SQL을 LOG에서 copy 할경우 가시적으로 보기 힘든경우 사용합니다.

2. 질의 실행 계획보기.
- 질의편집기에 SQL을 작성 후, 질의 실행계획보기를 통하여 해당 SQL의 실행계획을 확인 할 수 있습니다.

2.1 질의실행계획보기 --계속
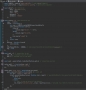
- 질의 실행 계획보기를 실행 시, 질의 계획의 원본, 트리출력, 그래픽출력 등으로 쉽게 확인이 가능합니다.
- 이글에서 주로 다룰 내용은 트리출력이며, 보다 사용자가 보기 편리한 구조로 이루어져 있습니다.

- 해당 내용을 분석하면, olympic 테이블과 record 테이블은 서로 inner join으로 조인이 이루어 집니다.
- olympic 테이블은 FULL SCAN이 일어났으며, 모두 디스크 io가 발생하였습니다.
- record 테이블은 primary key(host_year)을 사용하여 인덱스 범위검색을 하였습니다.
- 이때, olympic 테이블에서 추출한 레코드는 총 25개 이며, record 테이블에서는 2000개의 레코드를 추출하였습니다.
- olympic 테이블에서의 전체 row는 25건이며, 페이지로는 1게 페이지 사용중입니다.
- record 테이블의 전체 row는 2000건 이며, 페이지는 8페이지로 나뉘어져 사용중입니다.
* 이와 같이 질의 실행계획을 실행함으로써 비용, 카디널리티, 전체 row/page를 기반으로 질의 최적화를 이룰 수 있습니다.
3. SET TRACE ON
- 질의 편집기에서도 질의의 trace 정보를 확인 할 수 있습니다.
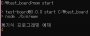
- 우선 아래와 같이 질의편집기에 trace mode를 동작시킵니다.

- 그 이후, TRACE 정보를 확인 할 SQL을 수행시킵니다.

- 마지막으로 SHOW TRACE 를 통하여 해당 SQL의 TRACE정보를 확인합니다.

- 아래 trace 질의 결과를 보면 아래와 같습니다.
- TRACE 정보
Trace Statistics:
SELECT (time: 0, fetch: 58, ioread: 0)
SCAN (index: olympic.pk_olympic_host_year), (btree time: 0, fetch: 2, ioread: 0, readkeys: 1, filteredkeys: 0, rows: 1) (lookup time: 0, rows: 1)
SCAN (index: record.pk_record_host_year_event_code_athlete_code_medal), (btree time: 0, fetch: 2, ioread: 0, readkeys: 441, filteredkeys: 0, rows: 441, covered: true)
- 우선 olympic 테이블은 pk index를 사용하였으며, 인덱스에서의 2번의 fetch가 있었습니다.
- 검색을 위해 읽은 readkey는 1개 이며, 추출된 row도 1건입니다.
- record테이블 같은 경우도 마찬가지로 pkindex를 사용하였으며, 2번의 fetch가 있었습니다.
- 총 441개의 읽어 441개의 row를 추출하였으며 covered 되었습니다.
4. 마무리
- 위와 같이 질의실행계획 확인 및 trace정보를 확인 함으로 써, 현재 사용하고 있는 SQL이 왜 느린지를 확인 할 수 있습니다.
- 또한 어떠한 인덱스가 효율적인지와, 불필요한 인라인뷰나 정렬이 사용되는지도 확인이 가능합니다.
- 이러한 비효율을 제거한다면, 최적화된 DBMS 활용이 가능합니다.
 CUBRID 커버링 인덱스(covering index) 이야기
CUBRID 커버링 인덱스(covering index) 이야기