External Sort
DBMS는 다양한 상황에서 데이터를 정렬합니다. 사용자 요청으로 ORDER BY 절을 통해 정렬하기도 하고, UNION 절이나 DISTINCT 키워드가 사용되었을 때 중복데이터를 제거하기 위해 데이터를 정렬합니다. 그리고 sort merge join과 인덱스 생성시에도 데이터를 정렬합니다. 이렇듯 DBMS에서 정렬은 여러 상황에서 많이 사용되고 있습니다. CUBRID는 어떻게 데이터를 정렬하고 있을까요? external_sort.c 파일을 분석한 내용을 공유합니다.
Merge Sort
external sort의 기본이 되는 merge sort부터 살펴보겠습니다. merge sort는 데이터를 분할하고 합병을 반복하면서 정렬하는 알고리즘입니다.
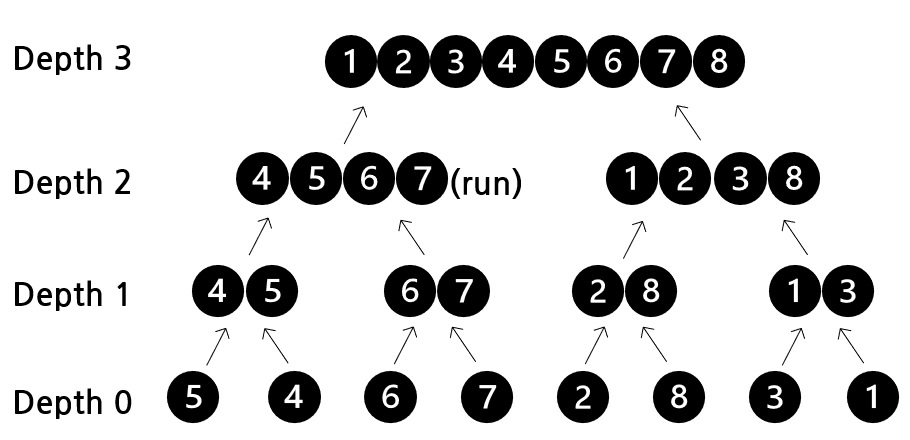
정렬이 필요한 데이터를 분할하는데 분할된 조각을 run이라고 합니다. 분할이 완료되면 두 개의 run을 합병합니다. 위 그림은 분할 이후 합병하는 과정을 나타낸 것입니다. 합병을 진행하면 정렬된 새로운 run이 생성됩니다. 합병을 계속 진행하여 한 개의 run이 남을 때까지 반복하면 데이터 정렬이 완료됩니다. 그렇다면 두 run의 합병은 어떻게 진행이 될까요? depth 2의 두 run이 합병되는 과정을 살펴보겠습니다.
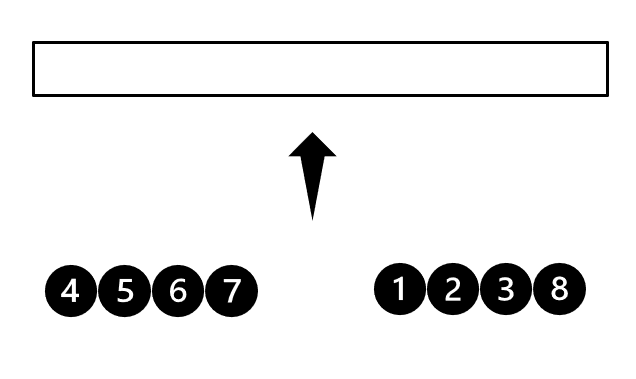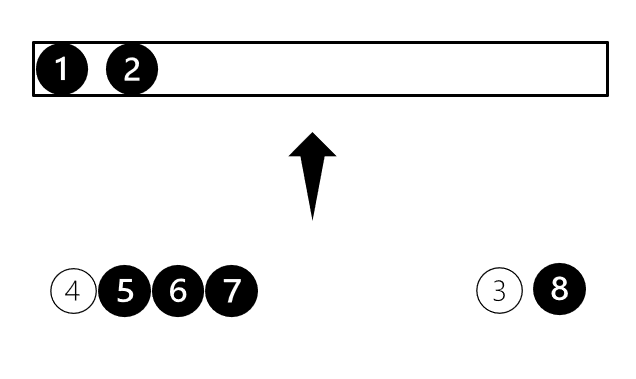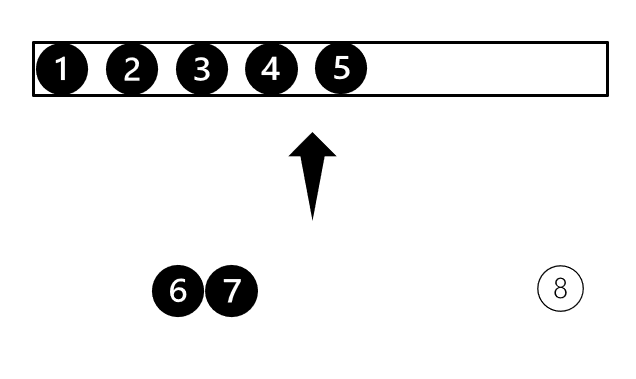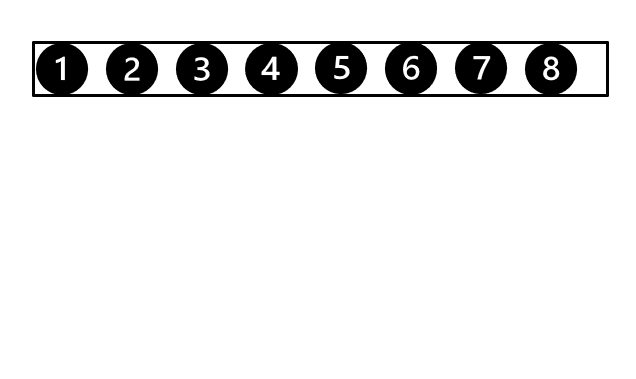
위 그림처럼 정렬이 진행됩니다. 두 run이 정렬되어 있기 때문에 왼쪽의 두 데이터를 비교하여 가장 작은 데이터를 선택할 수 있습니다. 이러한 비교를 마지막 데이터까지 진행하면 정렬이 완료됩니다. 최대 데이터 비교회수가 두 run의 데이터 수의 합를 넘지 않는 알고리즘입니다. 정렬이 되어 있는 상황에서는 가장 좋은 합병 방안입니다. 하지만 데이터 수가 서로 비슷하지 않고 한쪽이 매우 적다면 이야기는 달라집니다. 이때는 이분검색을 통한 삽입정렬이 유리할 수 있습니다. 좋은 성능을 내기 위해서 비슷한 크기의 run이 합병되도록 하는 것이 중요합니다.
K-way Merge Sort
위에서 살펴본 일반 merge sort가 2-way merge sort입니다. k-way merge sort는 k개의 run을 동시에 합병을 진행하는 알고리즘입니다. 아래는 4-way merge sort의 예시입니다.
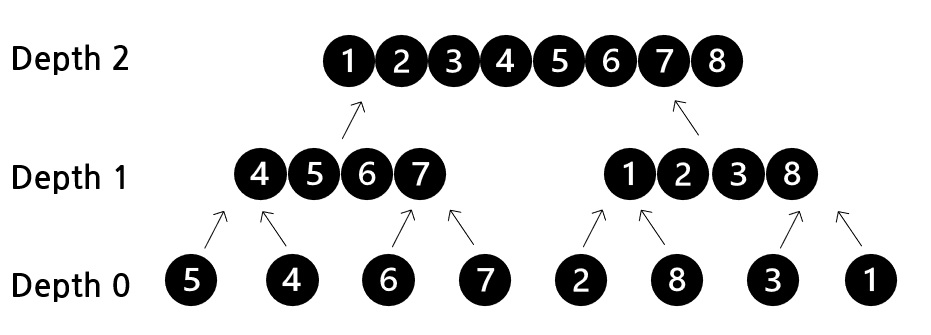
k-way merge sort에서 k의 개수를 늘릴수록 유리할까요? k가 늘어날수록 여러 개의 run을 한 번에 합병하기 때문에 tree의 depth는 낮아집니다. 위 그림을 비교하면 4-way가 2-way보다 depth가 낮은 것을 확인할 수 있습니다. k에 따른 depth를 수식으로 표현해보겠습니다. 현재 depth를 x라 할 때 run의 길이는 kx입니다. 최종 depth일 때 run이 하나이므로 전체 데이터수(N)를 아래와 같이 정의할 수 있습니다.
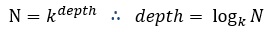
k가 커지면 depth가 줄어들긴 하는데 일정 지점부터는 아주 천천히 줄어들 것입니다. depth가 줄었다는 것은 합병 횟수가 줄었음을 의미합니다. 이렇게 보면 k 값을 크게 하는 것이 유리해 보입니다. 하지만 한 가지 더 생각해야 하는 부분이 있습니다. 그것은 최저값을 구하기 위해 추가되는 비교 횟수입니다. 우선 2-way merge sort의 전체 데이터 비교 횟수를 생각해 보겠습니다. 한 depth에서 데이터 비교 회수의 평균을 @ * N이라고 @를 가정하겠습니다. 데이터 비교회수가 각 run의 합 그러니까 전체 데이터 수를 넘지 않으므로 @는 1과 0 사이의 소수일 것입니다. 그렇다면 전체 데이터 비교회수는 아래와 같은 수식으로 표현할 수 있습니다.

k-way merge sort는 데이터 최저값을 구할 때 2-way merge sort보다 (k-1)번 더 비교해야 최저값을 구할 수 있습니다. 그렇다면 (k-1) * @ * N * logkN 이 전체 데이터 비교 횟수입니다. 여기서 우리가 궁금한 것은 N이 고정되었을 때 k에 따른 데이터 비교 횟수의 변화입니다. N과 @는 상수이므로 제거하고 수식을 좀 더 단순화하면 k * logkT (T=상수)가 됩니다.
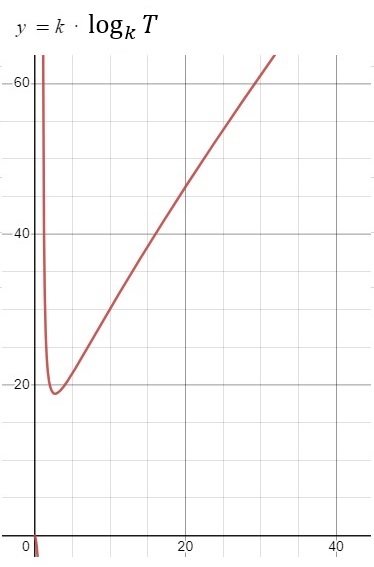
위 그래프에서 확인할 수 있듯이 k-way merge sort에서 k는 적절한 특정 값에서 가장 효율적일 것입니다. 한 가지 더 생각해볼 것은 합병 시 데이터 비교를 얼마나 효과적으로 하느냐에 따라서 그래프가 달라질 수 있다는 점입니다. 데이터 비교회수를 k의 반으로 줄이면 그래프의 기울기가 완만해질 것입니다. 데이터 비교회수를 log2k까지 줄일 수 있다면 k값과 관계없이 동일한 비교회수를 얻을 수 있을 것입니다. 실제로 구현 시에는 임시 파일에 대한 리소스 관리 등 k를 늘렸을 때 부수적으로 관리되어야 하는 항목들이 추가로 실행속도에 영향을 줄 것입니다. CUBRID는 정렬할 데이터양에 따라서 한 번에 합병할 run을 2개에서 4개(SORT_MAX_HALF_FILES)까지로 제한하고 있습니다.
External Sort
DBMS는 정렬할 데이터의 크기가 메모리를 넘을 수 있다는 것을 고려해야 합니다. external sort가 그 문제를 해결하는 알고리즘입니다. 가용 메모리 안에서 데이터를 정렬하고 그 결과를 임시파일에 저장합니다. 그 조각이 한 개의 run이 되고 모든 데이터가 저장될 때까지 반복합니다. 그리고 저장된 run을 모두 합병하면 정렬이 완료됩니다. 가용 메모리 안에서 정렬을 진행하는 internal phase와 파일에 저장된 run을 합병하는 external phase로 구분됩니다.
Internal phase (sort_inphase_sort())
설정된 메모리 크기만큼 데이터를 분할하여 정렬을 진행하는 단계입니다. sort_buffer_size 시스템 파라미터에서 정렬 메모리크기를 설정할 수 있습니다. 설정값의 메모리는 세션별로 할당되며 기본값은 2M입니다. run의 정렬이 완료 되면 결과를 임시 파일에 저장합니다.

internal phase에서는 메모리 안에서 정렬을 2-way merge sort로 진행합니다. 첫번째로 데이터를 메모리에 적재하는데 합병을 위한 공간을 데이터크기만큼 확보합니다. 메모리 적재가 완료되면 저장된 데이터의 정렬을 진행합니다(sort_run_sort). 먼저 데이터를 run으로 분할합니다(sort_run_find). 여기서 한가지 성능 향상을 위한 가정이 있습니다. 실제 데이터는 어느정도 정렬되어 있을 가능성이 높다는 점입니다. run을 지정할 때 다음 데이터와 비교하여 정렬되어있다면 같은 run으로 지정합니다. 역순으로 정렬되어 있으면 run 지정 후 순서를 뒤집어 저장합니다(sort_run_flip). 동일한 depth의 run이 두개가 되었을 때 합병을 진행합니다(sort_run_merge). 같은 depth의 run만 합병을 진행하는 이유는 비슷한 크기의 run을 합병하는 것이 효율적이기 때문입니다. 또한 run의 첫 데이터를 비교할 때는 마지막 데이터도 같이 비교하는데, 비슷한 데이터가 모여있다고 가정하고 데이터 비교를 줄이려는 방안입니다. 합병이 완료되어 한 개의 run만 남으면 정렬이 완료됩니다. 정렬된 결과는 메모리에서 임시파일로 옮겨 저장합니다(sort_run_flush). 임시파일에 저장된 여러개의 run의 정보는 file_contents 구조체에 저장되어 관리됩니다. 모든 input 데이터가 소진될때까지 반복하면, 여러개의 run이 저장된 2~4개의 임시파일이 결과로 남습니다. 이제 최종 정렬까지 임시파일의 합병만이 남았습니다.
External pahse (sort_exphase_merge())
임시파일에 저장된 여러 개의 run을 합병합니다. 합병을 위한 동일한 크기의 임시파일 저장공간이 추가로 있어야 합니다.
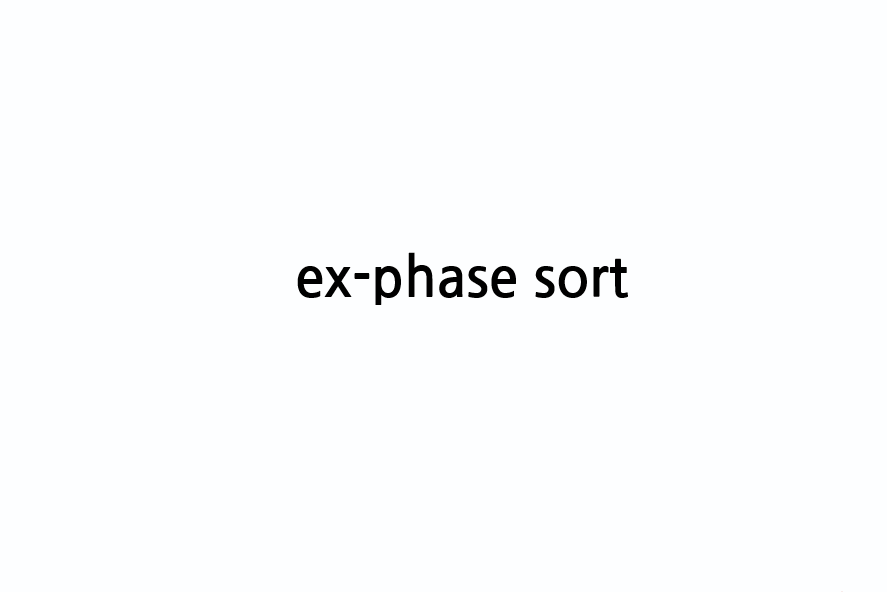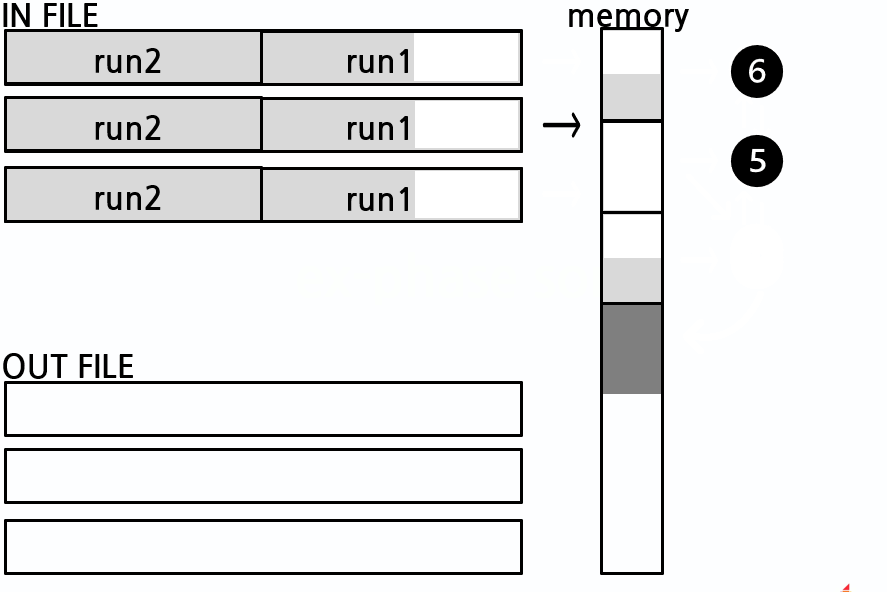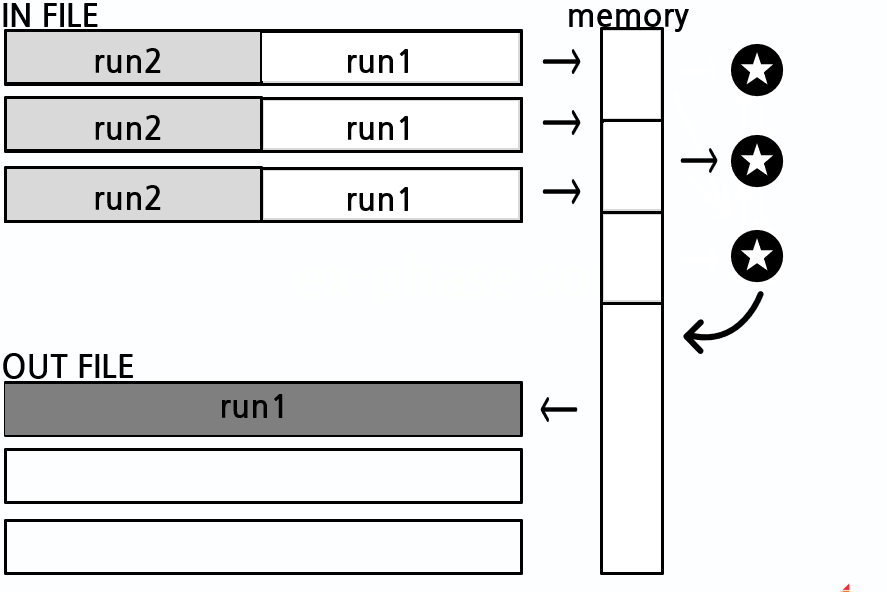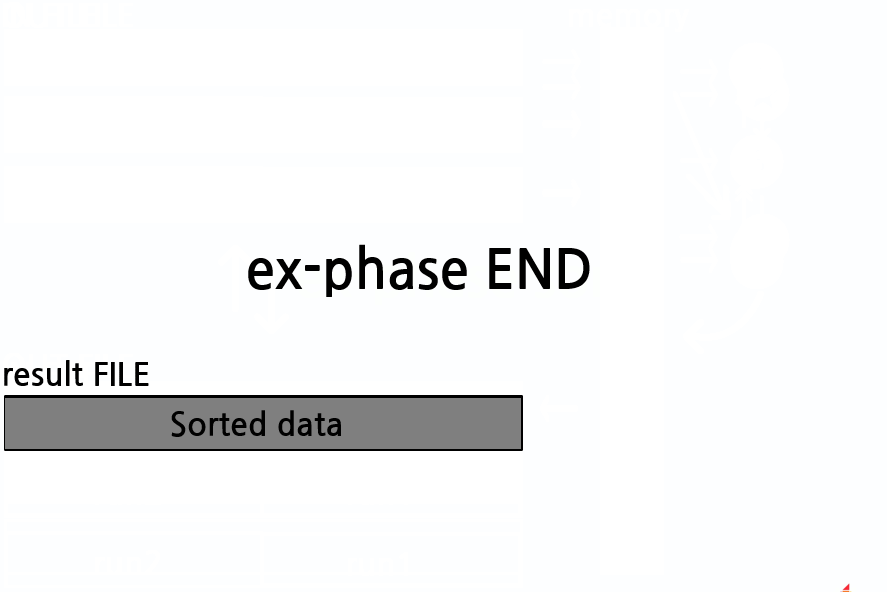
internal phase의 결과인 2~4개의 임시파일이 external phase의 입력값이 됩니다. 먼저 합병하기 위해 메모리 공간을 분할하는데 절반은 합병을 위한 공간에 할당하고 나머지 공간은 임시파일 개수만큼 분할하여 할당합니다. 그 다음 임시파일에서 데이터를 메모리로 읽어옵니다(sort_read_area). 이때 임시파일에 저장된 page 구조 그대로 메모리에 저장합니다. 임시파일의 page가 각각의 메모리 공간에 적재되면 레코드를 한 개씩 가져와 정렬합니다. 가장 작은 레코드를 합병 공간으로 이동시키고 새로운 레코드를 추가합니다. 데이터 비교 횟수를 줄이기 위해 레코드 비교시 linked list 구조로 정렬을 유지합니다. 또한 page를 처음 읽을 때 page의 마지막 레코드와 비교하여 page의 전체 레코드가 작은지 확인합니다. 만약 그렇다면 해당 page의 전체 레코드를 비교없이 합병공간에 담을 수 있습니다. 합병 공간이 가득 차면 출력 임시파일에 데이터를 저장합니다(sort_write_area). 위의 작업을 계속 반복하면 결국 입력 임시파일의 run은 모두 소진될 것입니다. 이제 input 임시파일과 output 임시파일을 서로 교체합니다. in_half와 out_half 변수를 교체하여 그 작업을 진행합니다. 위의 작업을 계속 반복하여 한 개의 run이 남게 되면 모든 정렬 과정은 마무리됩니다.
Sort parallelism
CUBRID는 정렬 병렬처리를 지원하지 않습니다. 그런데 소스코드에는 반영하려 했던 흔적이 남아있습니다. 지금은 비활성화 되어 있지만 internal sort에서 해당 로직을 확인할 수 있습니다. 데이터를 분할해서 새로운 worker thread에 할당하여 병렬처리를 하고 있는데, 그 숫자를 제한하지 않고 있습니다. 아마도 일반적인 질의를 위한 것이 아니라 데이터 이관 시 인덱스 생성에 사용하기 위해 추가된 로직으로 보입니다. external phase는 고려되지 않아 반쪽짜리 로직입니다만, worker thread를 사용하여 병렬처리하고 mutex로 thread간의 완료를 확인하는 점은 이후에 병렬 처리 개발 시에 활용할 수 있는 부분으로 보입니다.
정렬에 대하여
DBMS에서 정렬은 인덱스 생성, 데이터 중복 제거, 사용자의 요청 등 다양한 상황에서 진행됩니다. 그러므로 DBMS의 성능과 밀접한 관련이 있습니다. 필자는 올해 진행 중인 OPTIMIZER 개선 과제가 완료되면 질의 병렬처리를 진행할 예정입니다. 아마도 병렬 질의의 여러 기능 중 정렬이 가장 먼저 진행될 것 같습니다. k-way merge 알고리즘이 병렬처리에 용이해 보이기 때문입니다. 그리고 개선이 가능한 사항도 보입니다. internal phase에서 최초 run의 길이가 가변적이기 때문에 비슷한 크기의 run을 합병하기 위한 추가 로직이 있다면 더 효율적으로 동작할 것으로 생각됩니다.
정렬을 분석한 이유는 통계정보에 중복이 제거된 데이터 수(Number of Distinct Values)가 필요했기 때문입니다. 분석을 하다보니 필요이상으로 진행이 된것 같습니다. 아무튼 원하는 결과는 달성되었고, 좀 더 분석된 내용은 이후 과제 수행 시 도움이 될 것입니다. 다음에는 현재 진행 중인 OPTIMIZER 개선과 관련된 내용을 적어보도록 하겠습니다.