DBMS는 SQL을 효과적으로 처리하기 위해서 어떠한 노력을 하고 있을까요?
- 질의 재작성기(Query Rewriter)
여러 개발자에게 동일한 요구사항을 주고 질의를 작성하게 하면 서로 다른 형태로 작성할 수 있습니다. 질의를 어떻게 작성하느냐에 따라서 성능에 차이가 발생할 수 있기 때문에 개발자가 질의를 효과적으로 작성하는 것은 중요한 일이지만, DBMS가 상당부분 그 일을 대신하고 있습니다.

위 질의를 작성한 그대로 수행하게 되면 부질의 결과를 임시파일에 저장하고 그것을 재가공해야 합니다. 하지만 오른쪽 질의처럼 작성되어 있다면, 따로 부질의를 수행해서 저장할 필요도 없고, 인덱스의 사용도 가능합니다. 위와 같이 부질의를 제거하고 주질의에 합병하는 것을 뷰머징이라고 합니다. DBMS는 가능한 경우 뷰머징을 진행하며, 인라인 뷰와 뷰 객체에 대해서도 동일하게 합병을 진행합니다.
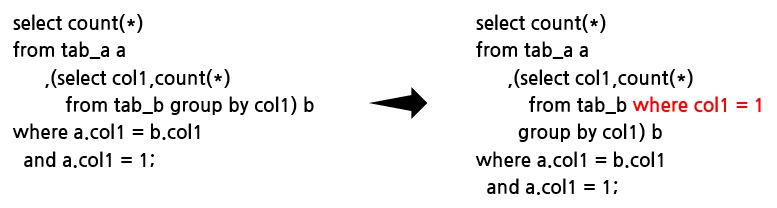
부질의가 뷰머지가 불가능한 경우에 주질의에 있는 조회조건을 부질의로 넣는 것을 predicate push라고 합니다. 조회시 스캔하는 양을 줄일 수 있기 때문에 상당히 성능을 향상시킬 수 있습니다.

필요 없는 select list와 조인 테이블 그리고 order by절등을 제거하여, 필요없는 처리과정을 진행하지 않을 수 있습니다. 해당 항목을 조회 하지 않아도 동일한 결과가 보장될 때 제거가 가능합니다. 테이블은 외부 조인되거나 외례키 관계에서 조인 조건의 컬럼이 유니크한 경우 제거가 가능합니다.
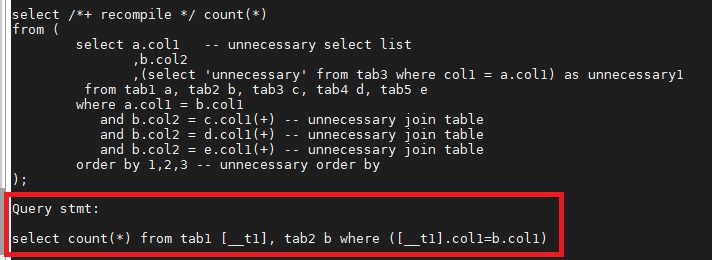
위에서 소개한 재작성 이외에도 DBMS는 다양한 재작성을 진행합니다. CUBRID는 이러한 재작성된 질의를 실행계획에서 직접 확인할 수 있습니다.
- 질의 최적화기(Query Optimizer)
SQL은 어떻게 데이터를 조회할 것인가에 대한 정보를 포함하고 있지 않습니다. 질의 최적화기가 이러한 정보인 실행계획을 생성합니다.

위 질의의 조회조건으로 얼마나 데이터가 필터링될지 예측할 수 있을까요? 만약 'COLUMN'의 값이 고유하다면 한건이 조회 될 것이고, 모두 '1'이라면 전체 데이터가 조회 될 것입니다. 이렇게 조회조건을 평가했을 때 전체 데이터 대비 조회되는 양의 비율을 선택도(selectivity)라고 합니다. 선택도를 통해서 읽어야하는 페이지수와 결과 행수를 예측할 수 있습니다. 예를 들어 'table'의 전체 페이지수는 1000개, 데이터 건수는 10,000개이고 조회조건의 선택도가 0.01이면, 읽어야 하는 페이지수는 10개, 결과 행수는 100건으로 예측할 수 있습니다. 비용계산 공식은 스캔 방법에 따라 다르고 복잡하지만, 기본적인 원리는 선택도를 활용하여 결과 행수와 읽어야 하는 페이지를 예측하는 것입니다.
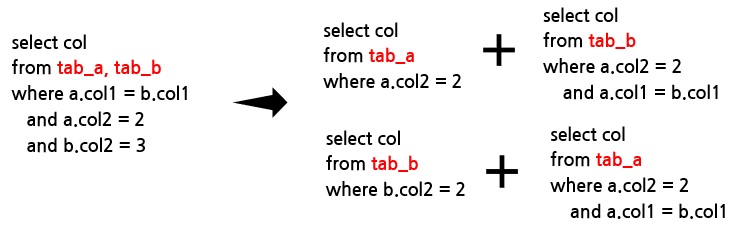
위와 같이 조인된 질의는 각테이블 별로 분리해서 비용을 산출합니다. 첫번째 테이블의 선택도와 전체 페이지수로 비용을 계산하고 두번째 테이블역시 같은 방법으로 비용을 산정합니다. nested loop 조인 방법이라면 첫번째 결과 행수만큼 두번째 테이블 조회를 반복하게 됩니다. 이 경우 전체 비용은 첫번째 비용 + (첫번째 행수 * 두번째 비용) 으로 계산할 수 있습니다. 질의 최적화기는 각각 테이블 순열의 비용을 계산하고, 비교하여 최적의 실행계획을 선택합니다.
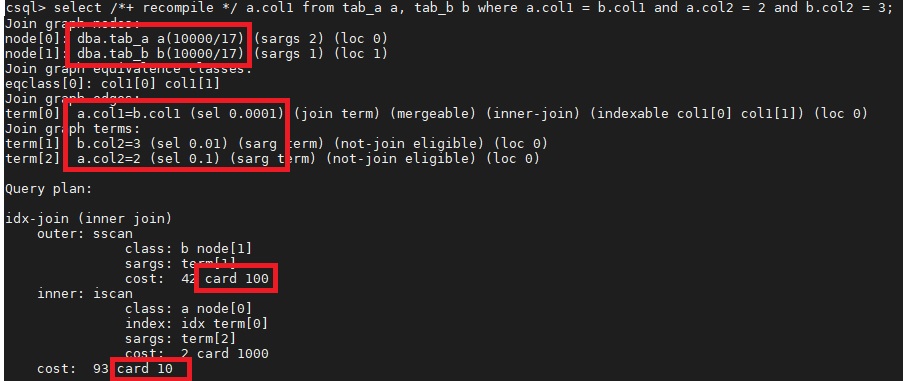
실행계획을 보면 최적화시에 사용된 정보들을 확인할 수 있습니다. 테이블의 전체 건수와 페이지수 그리고 조회조건의 선택도가 얼마인지 확인 할수 있습니다. 실행계획의 card는 cardnality의 약자로 예측되는 결과 행수를 의미합니다. 각각의 정보를 알고 있으면 실행계획을 정확하게 이해하는데 도움이 될 것입니다.
- 질의 실행기(Query Executor)
질의 실행기에서는 성능 향상을 위해 진행 단계를 생략하는 최적화를 진행합니다. 인덱스를 활용하여 정렬과정을 생략하거나 인덱스의 정보만으로도 조회가 가능하면 데이터영역에 접근하는 과정을 생략합니다. 다중 키 범위 최적화와 SORT-LIMIT 최적화와 같이 필요한 양의 데이터만 조회하여 나머지 데이터의 스캔 과정을 생략하기도 합니다.

TRACE 정보를 확인하면 질의 실행기가 어떤 최적화를 진행했는지 알 수 있습니다. 또한 실제로 읽은 페이지수와 결과 행수도 확인 가능합니다.
- 마치며
DBMS는 성능향상을 위해 다양한 최적화를 진행하고 있으며, 사용자는 실행계획과 TRACE 정보를 통해 이것을 확인할 수 있습니다. CUBRID는 이러한 성능 향상을 위한 개선 작업을 지속적으로 진행하고 있습니다. 질의가 더 효과적으로 재작성되도록 다양한 사례의 재작성을 추가하고 보완하였습니다. 효과적인 실행계획을 생성하기 위해서 선택도관련 통계정보의 대상을 인덱스에서 테이블로 확대하고, 규칙기반 최적화는 최소화하는 작업을 진행하고 있습니다. CUBRID는 아직 병렬 질의를 지원하지 않지만 2024년을 목표로 개발을 진행하고 있습니다. 조금씩 꾸준히 사용자 관점에서 개선되는 CUBRID를 기대해 주시기를 바랍니다.
 CUBRID Internal: B+ 트리의 노드(=페이지)와 노드 분할 방법
CUBRID Internal: B+ 트리의 노드(=페이지)와 노드 분할 방법