- HASH SCAN
Hash Scan은 hash join을 하기 위한 스캔 방법입니다. view 혹은 계층형 질의에서 Hash Scan이 적용되고 있습니다. view와 같은 부질의가 inner로써 조인될 경우 인덱스 스캔을 사용할 수 없는데, 이 경우 많은 데이터를 반복 조회 하게 되면서 성능 저하가 발생됩니다. 이때 Hash Scan이 사용됩니다.
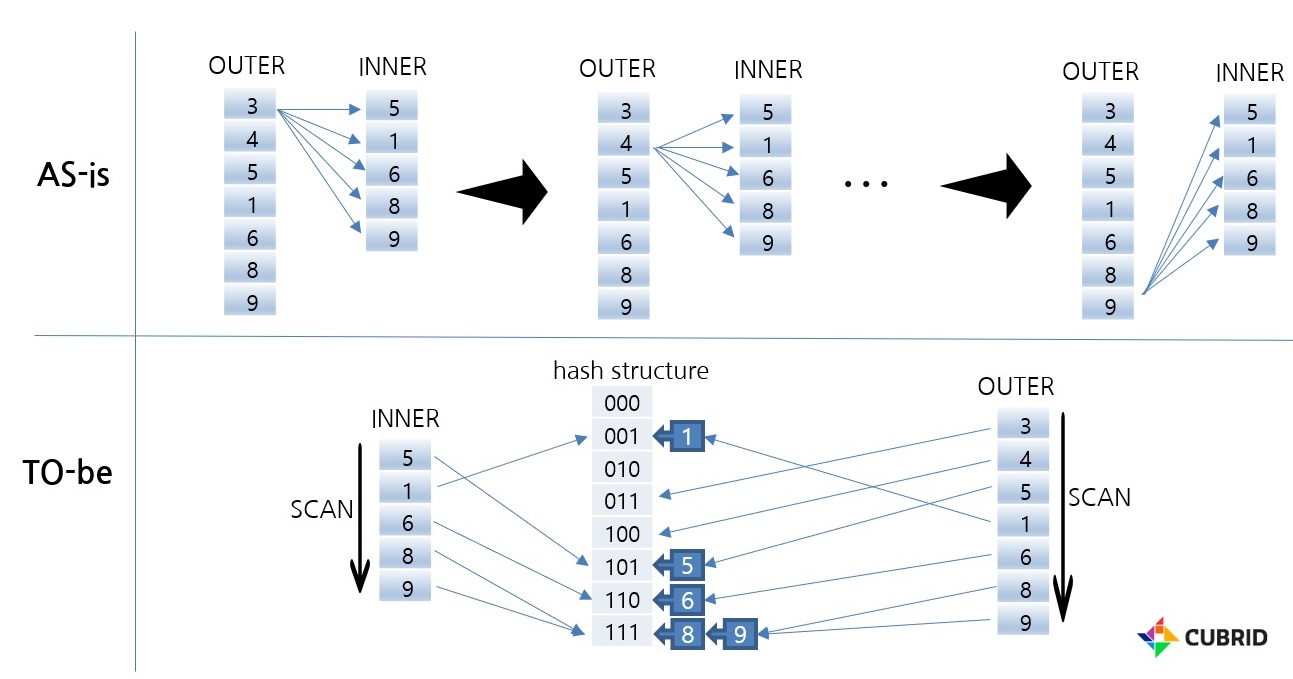
위 그림은 인덱스가 없는 상황에서의 Nested Loop join과 Hash Scan의 차이를 보여줍니다. NL join의 경우 OUTER의 Row수만큼 INNER의 전체 데이터를 스캔합니다. 이에 반해 Hash Scan은 해시 자료구조 빌드 시 INNER 데이터를 한번 스캔하고, 조회시 OUTER를 한번 스캔합니다. 그렇기 때문에 상대적으로 매우 빠르게 원하는 데이터를 조회할 수 있습니다.
여기서는 Hash Scan의 내부 구조를 프로그램 개발 진행 과정의 흐름으로 작성하였습니다.
- IN-MEMORY HASH SCAN
CUBRID의 Hash Scan은 데이터양에 따라서 in-memory, hybrid, file hash의 자료 구조를 사용하고 있습니다. 먼저 in-memory 구조부터 살펴보겠습니다. memory의 장점은 random access시 성능 저하가 없다는 점입니다. 하지만 단점은 메모리 크기가 한정되어 있다는 것입니다. 단점 때문에 모든 케이스에서 사용할 수는 없지만, 장점 때문에 가장 빠른 방법입니다. 이러한 장점은 chaining hash 구조에 적합합니다.
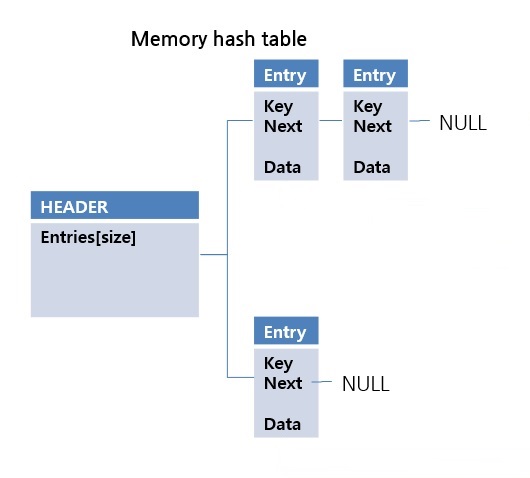
hash key 값의 충돌이 발생하면 next pointer에 새로운 엔트리를 넣어주는 방식입니다. 구현이 간단하고 속도가 빠른 구조입니다. 하지만 file 형식으로 구현 시에는 random access 문제나 space utilization 관련 문제가 발생할 수 있습니다. 이에 대한 자세한 내용은 file hash 구조에서 설명하겠습니다. CUBRID는 제한된 크기 이내에서만 in-memory hash scan을 진행합니다. max_hash_list_scan_size 시스템 파라메터를 사용하여 제한 크기를 변경할 수 있습니다.
이 단계에서는 in-memory hash 자료구조를 구현하는 것보다 OPTIMIZER, EXECUTOR를 분석하고 어느 부분을 수정해야 하는지에 대해서 더 많은 고민이 필요했습니다. 이에 대한 자세한 내용은 생략합니다. 아래 링크에서 확인해 주세요. JIRA에서는 설계 관련 내용을, GIT에서는 소스코드 수정과 리뷰의 결과를 확인하실 수 있습니다.
JIRA : http://jira.cubrid.org/browse/CBRD-23665
GIT : https://github.com/CUBRID/cubrid/pull/2389
- HYBRID HASH SCAN
in-memory hash 자료구조의 값에 DATA가 아니고, temp file의 OID(Object Identifier)를 저장하는 방식입니다.
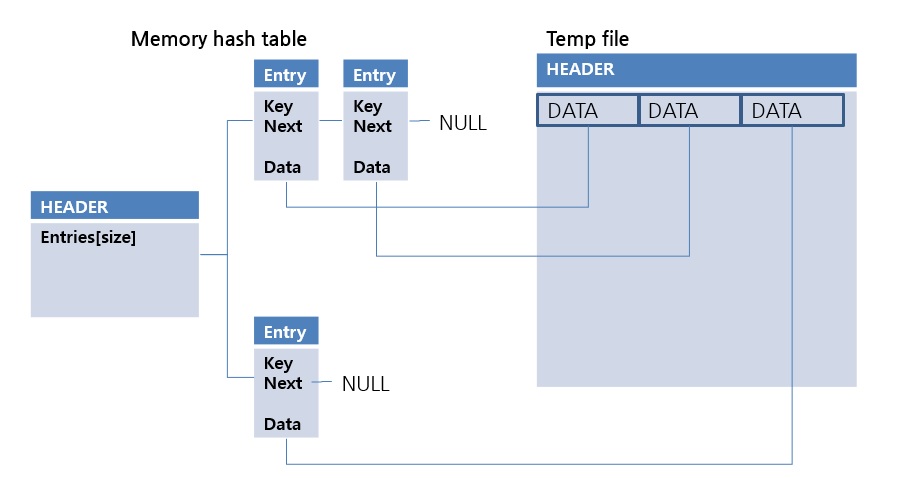
DATA 보다 OID의 크기가 작기 때문에 in-memory hash 자료구조를 더 큰 데이터 집합에서 사용할 수 있는 방법입니다. 조회시 temp file의 데이터를 읽어야 하므로 in-memory hash 방법보다 상대적으로 느린 방법입니다. hash scan에서 두번째로 고려되는 스캔방법입니다. 자세한 내용은 아래 링크를 확인하세요.
JIRA : http://jira.cubrid.org/browse/CBRD-23828
GIT : https://github.com/CUBRID/cubrid/pull/2537
- FILE HASH SCAN
file hash 자료 구조를 사용하는 스캔 방법입니다. extendible hash 자료구조를 사용하고 있습니다.
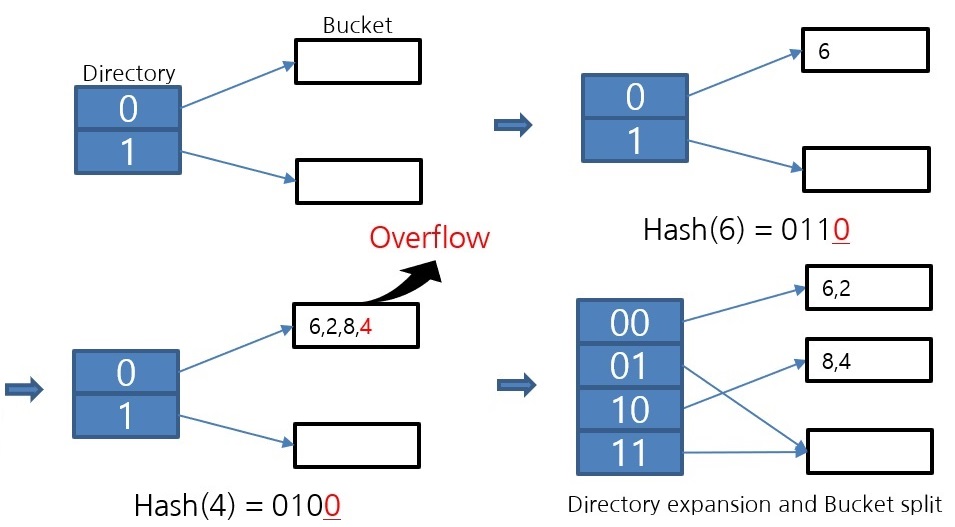
위 그림은 extendible hash 알고리즘의 동작을 나타냅니다. overflow가 발생하면 해당 Bucket을 분할하는 방식으로 동작합니다. 이렇게 분할하는 방식으로 동작하기 때문에 Bucket의 공간 사용률을 50% 이상으로 유지할 수 있는 알고리즘입니다. 한 개의 bucket이 디스크 I/O 최소 단위인 page로 구현되어 있기 때문에 Bucket 공간 사용률이 높을수록 디스크 I/O를 줄일 수 있습니다. 이러한 이유로 file hash scan은 extendible hash 알고리즘을 사용합니다.
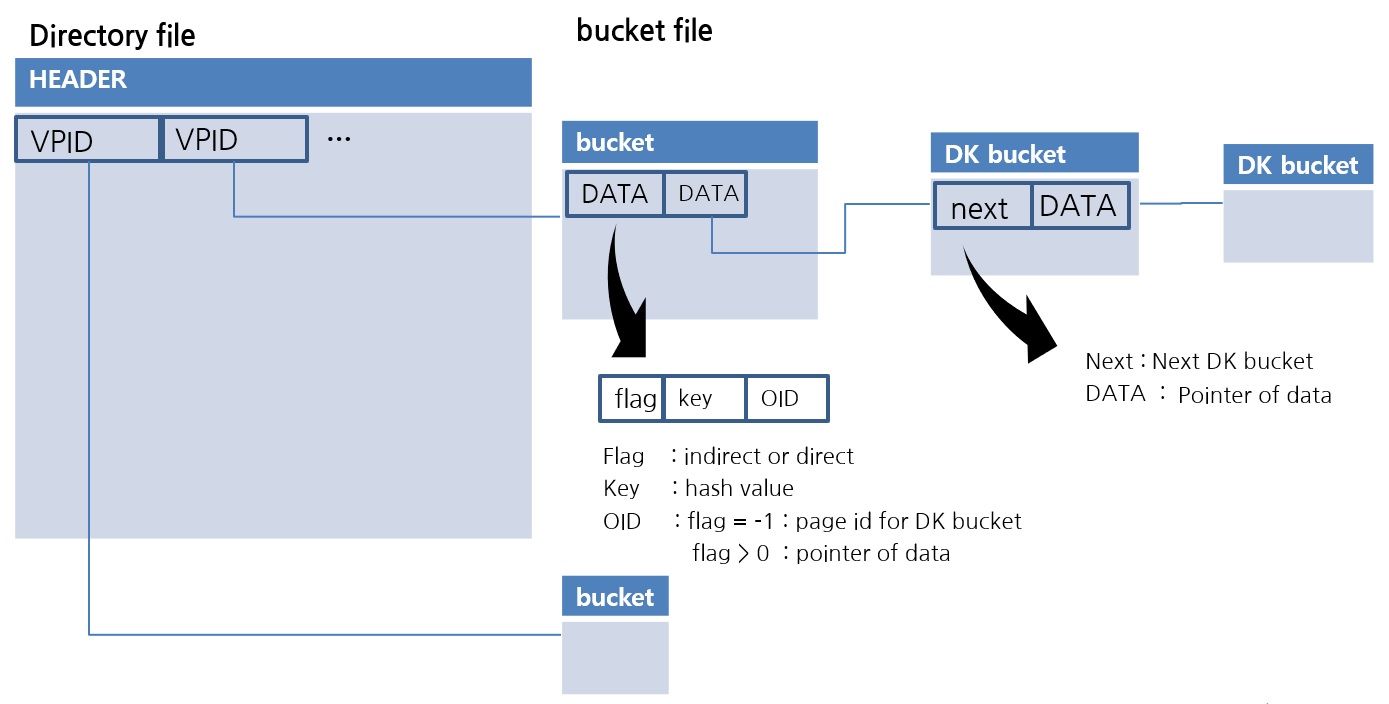
CUBRID에서 extendible hash 자료구조가 구현된 모습입니다. Directory 파일에는 VPID가 저장되는데 이는 Page Identifier입니다. 한 개의 Bucket은 하나의 page로 구현되었습니다. Bucket 안의 데이터는 정렬되어 있어서 조회 시 이진 검색을 사용합니다.
extendible hash 자료구조가 가지는 한 가지 단점은 중복데이터값에 대한 예외가 없다는 것입니다. 예를 들어 같은 값이 한 개의 Bucket에 모두 저장되어 Overflow가 발생된다면 더는 저장이 불가능한 알고리즘입니다. 이를 위해 Duplicate Key Bucket을 새롭게 만들고 이것을 chaining 형태로 추가하였습니다. 일정량 이상의 데이터가 중복되어 입력될 경우 DK bucket으로 데이터가 이동됩니다. 이를 통해 중복 값에 대해서 유연하게 저장이 가능하면서 공간 활용성이 우수한 file hash scan이 완성되었습니다. 역시 더 이상 자세한 설명은 생략합니다. 자세한 내용은 아래 링크를 통해 확인하세요.
JIRA : http://jira.cubrid.org/browse/CBRD-23816
GIT : https://github.com/CUBRID/cubrid/pull/2781
- HASH SCAN for Hierarchical Queries
계층형 질의의 경우 특수한 제약사항이 있는데 조인 이후 계층 간의 조회를 진행해야 하는 점입니다. 이 때문에 조인이 있는 계층형 질의의 경우 index scan을 사용하지 못합니다. 이 상황에서 필요한 것은 hash scan이겠죠? 계층형 질의에도 hash scan을 사용할 수 있게 수정 되었습니다. 자세한 사항은 아래 링크를 확인하세요.
JIRA : http://jira.cubrid.org/browse/CBRD-23749
GIT : https://github.com/CUBRID/cubrid/pull/2520
- HASH JOIN
in-memory hash scan은 CUBRID11 버전에 반영이 되었고, file hash scan은 CUBRID11.2 버전에 반영되어 릴리즈 예정입니다. Hash join기능은 현재 개발 진행 중입니다. hash join 기능의 개발은 OPTIMIZER에 새로운 join method를 추가하는 작업입니다. 현재 CUBRID에는 Nested Loop join과 Sort Merge Join이 있는데 여기에 새로운 join method가 추가되는 것입니다. CUBRID 개발팀에서는 전반적인 OPTIMIZER 개선작업을 진행 할 예정입니다. 이 작업을 통해 OPTIMIZER가 더욱더 최적의 실행계획을 생성할 수 있을 것입니다. 그리고 그 작업과 함께 hash join method가 추가될 예정입니다. hash join 추가 이전에는 실행계획에서 Hash Scan사용 여부를 확인하지 못합니다. 대신에 trace 정보에서 Hash Scan사용 여부를 확인할 수 있습니다.

- HASH SCAN 성능
Hash Scan이 필요한 상황에서 질의의 성능이 이전과 비교가 되지 않을 정도로 빨라졌습니다.
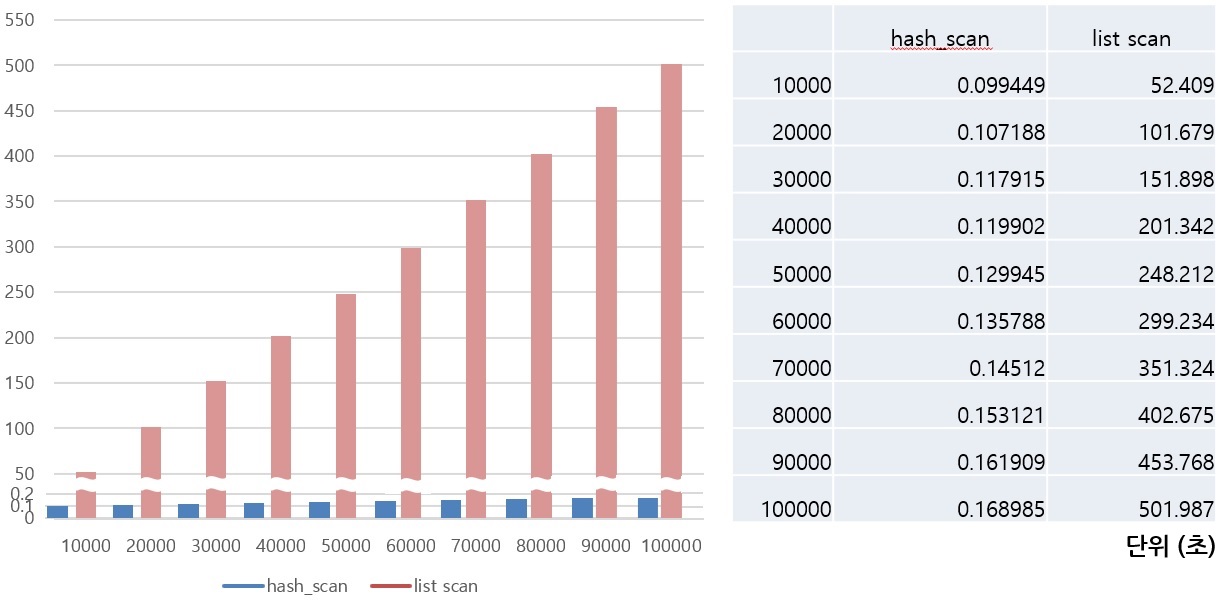
부질의가 inner로써 조인되는 경우나 조인이 있는 계층형 질의에서 이전과 비교했을 때 크게 성능이 향상되었습니다. CUBRID는 이러한 질의 성능 개선을 위해 여러 다른 케이스도 원인을 분석하고 개선 사항을 반영하고 있습니다. 이러한 개선 작업 중 View Merging과 Subquery unnest와 같은 REWRITER 개선 작업이 있는데, 현재는 View Merging관련 개선 작업이 진행되고 있습니다. 다음에는 DBMS에서 질의를 어떻게 변형하고, View Merging과 Subquery unnest와 같은 재작성 기법이 왜 필요한지에 대해서 알아보도록 하겠습니다.
 [CUBRID] QUERY CACHE에 대해
[CUBRID] QUERY CACHE에 대해
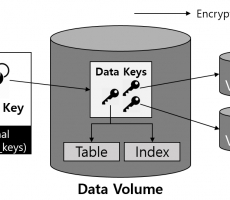
 CUBRID TDE(Transparent Data Encryption)
CUBRID TDE(Transparent Data Encryption)