
NEWS
-
Read More
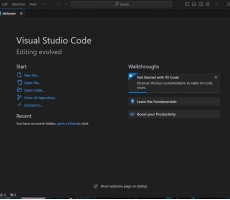
Visual Studio Code 소개
시작하며 Visual Studio Code (이하 VSCode) 는 마이크로소프트에서 오픈소스로 개발하고 있는 코드 에디터입니다. VSCode는 활용하기에 따라 메모장과 비슷한 기능을 하기도, IDE(통합 개발 환경) 로써의 기능을 하기도 합니다. 이미 많은 개발자들이 VSCode를 사용하고 있습니다. 그러나 VSCode의 사용이 낯선 개발자들을 위해 이 글에서는 VSCode의 기본적인 사용 방법을 소개드리려고 합니다. 설치 및 시작 VSCode는 공식 웹 사이트(https://code.visualstudio.com)에서 자신의 운영체제에 맞는 버전을 다운로드 받아 설치할 수 있습니다. 설치하고 난 뒤 VSCode를 실행하면 다음과 같은 화면을 마주할 수 있습니다. 이제, 수정하고 싶은 파일을 VSCode 내부로 끌어다 놓거나, Open File, Open Folder 를 통해 파일 및 폴더를 열어 로컬에 있는 코드를 개발할 수 있습니다. 하지만 VSCode의 성능을 온전히 이용하려면 확장(Extension)을 설치하여 응용하는 것을 추천합니다. 확장 (Extensions) 확장은 다음 버튼을 누르거나 Ctrl+Shift+X 를 입력하여 확장 탭에 진입할 수 있습니다. 초기에는 확장이 설치되지 않은 상태인데, Search Extensions in Marketplace 라고 적혀... -
Read More

CUBRID Internal: B+ 트리의 노드(=페이지)와 노드 분할 방법
목차 1. 개요 2. B+ 트리의 노드(= 페이지) 2.1. 오버플로 노드 (BTREE_OVERFLOW_NODE) 2.2. PAGE_OVERFLOW 페이지 3. 노드 분할 3.1. 노드 분할이 발생하는 경우 3.1.1. 새로운 키가 입력되는 경우 3.1.2. 기존 키의 크기가 증가하는 경우 3.1.3. 기존 레코드에 테이블 레코드의 OID가 추가되는 경우 3.1.4. 기존 레코드에 MVCC 아이디가 추가되는 경우 3.2. 사용자가 키를 입력하는 패턴에 따라 달라지는 노드 분할 #1 3.2.1. 시나리오 #1 - 1부터 27까지 오름차순으로 증가하는 패턴으로 키를 입력하는 경우 3.2.2. 시나리오 #2 - 1부터 27까지 불규칙 패턴으로 키를 입력하는 경우 3.2.3. 비교 결과 4. 똑똑하게 노드 분할하기 4.1. 사용자가 키를 입력하는 패턴에 따라 달라지는 노드 분할 #2 4.1.1. 오름차순으로 증가하는 패턴으로 키를 입력하는 경우 4.1.2. 내림차순으로 감소하는 패턴으로 키를 입력하는 경우 4.1.3. 불규칙 패턴으로 키를 입력하는 경우 5. 루트 노드 → 브랜치 노드 → 리프 노드 순서의 노드 분할 6. 참고 개요 큐브리드는 B+ 트리 인덱스를 사용하고 있습니다. B+ 트리 인덱스는 새로운 키가 입력되거나 기존 레코드가 변경될 때, B+ 트... -
Read More
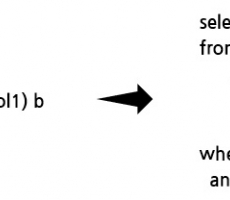
DBMS와 효과적인 SQL 처리
DBMS는 SQL을 효과적으로 처리하기 위해서 어떠한 노력을 하고 있을까요? - 질의 재작성기(Query Rewriter) 여러 개발자에게 동일한 요구사항을 주고 질의를 작성하게 하면 서로 다른 형태로 작성할 수 있습니다. 질의를 어떻게 작성하느냐에 따라서 성능에 차이가 발생할 수 있기 때문에 개발자가 질의를 효과적으로 작성하는 것은 중요한 일이지만, DBMS가 상당부분 그 일을 대신하고 있습니다. 위 질의를 작성한 그대로 수행하게 되면 부질의 결과를 임시파일에 저장하고 그것을 재가공해야 합니다. 하지만 오른쪽 질의처럼 작성되어 있다면, 따로 부질의를 수행해서 저장할 필요도 없고, 인덱스의 사용도 가능합니다. 위와 같이 부질의를 제거하고 주질의에 합병하는 것을 뷰머징이라고 합니다. DBMS는 가능한 경우 뷰머징을 진행하며, 인라인 뷰와 뷰 객체에 대해서도 동일하게 합병을 진행합니다. 부질의가 뷰머지가 불가능한 경우에 주질의에 있는 조회조건을 부질의로 넣는 것을 predicate push라고 합니다. 조회시 스캔하는 양을 줄일 수 있기 때문에 상당히 성능을 향상시킬 수 있습니다. 필요 없는 select list와 조인 테이블 그리고 order by절등을 제거하여, 필요... -
Read More
이노베이션 아카데미와 CUBRID의 산학협력
이노베이션 아카데미 (42서울) 42SEOUL(42서울)은 아키텍트급 소프트웨어 인재를 양성하는 것을 목적으로 하는 교육 과정이며, 프랑스에서 시작된 에꼴42의 교육 방식 및 인프라를 수입하여 운영하는 형태를 띈다. 에꼴42(Ecole 42)는 프랑스의 대형 통신사 CEO이기도 한 자비에 니엘(Xavier Niel)이라는 억만장자가 프랑스에서 2013년에 설립했다. 설립 당시에도 자기주도 학습 및 동료 평가를 내세운 무료 소프트웨어 교육 기관이라는 점으로 주목받았다. 현재는 브라질, 미국, 일본 등 세계 여러 곳에도 42 캠퍼스가 있다. 2019년에 대한민국 서울에도 42 서울 캠퍼스가 들어왔다. 42의 특징 중 하나로, 자기주도적 학습을 지향하기에 교재나 교수가 따로 없고 모든 것은 스스로 인터넷 또는 각종 도서 등을 통하거나 동료들과의 협업 및 교류를 통해 학습을 하게끔 유도한다. 교육생들 스스로 방법을 찾아 나아가라는 의도이며, 정해진 교재 및 교수가 없기 때문에 필연적으로 많은 삽질과 불분명한 요구사항을 맞닥뜨리게 된다. 심지어 문제를 풀어야 하는데, 뭘 배우고 공부해야 하는지 조차도 제대로 알려주지 않는다. 이는 소프트웨어 현장을 그대로 모방하여 실전 경... -
Read MoreNo Image
Index의 capacity에 관한 정보 열람
Index Capacity 정보 들어가며 DBMS의 여러 기능 기능이나 구성 요소들 중에서 가장 중요한 것은 무엇일까요? Index는 '가장' 중요한은 아니더라도 적어도 '아주 아주' 중요한 요소가 아닐까 생각 합니다. Index가 없다면 데이터를 쌓아 두기만 할 수 있을 뿐 사실상 관리는 못하는 그런 시스템이 될 테니까요. 자료가 많으면 많을 수록 Index는 더 중요해 집니다. 이렇게 중요한 Index를 분석할 때에도 목적에 부합하는 여러가지 도구와 방법들이 있을 수 있습니다. 이 페이지에서는 그 중에서 Index의 Capaicty에 대한 정보를 리뷰해 보고자 합니다. 기본적인 사용 방법이나 설명은 매뉴얼을 통해 얻을 수 있으므로 여기서 설명은 생략합니다. INDEX CAPACITY 정보 얻기 우선 CUBRID에서는 Index의 Capacity 정보를 다음과 같은 두 가지 방법으로 쉽게(?) 알아 볼 수 있습니다. 1. diagdb tool ------------------------------------------------------------- BTID: {{0, 5952}, 5953}, idx0 ON dba.tbl, CAPACITY INFORMATION: Distinct Key Count: 0 Total Value Count: 0 Average Value Count Per Key: 0 Total Page Count: 2 Leaf Page Count: 1 NonLea... -
Read More
CUBRID의 개발 문화: CUBRID DBMS 프로젝트 빌드 가이드와 빌드 시스템 개선
시작하며 이전 포스팅에서 CUBRID의 개발 문화: CUBRID DBMS는 어떻게 개발되고 있을까? 라는 주제로 블로그 글을 작성했었던 기억이 납니다. 날짜를 들여다보니 2021년 4월 29일에 작성되었으니 코로나 팬데믹을 이겨내고 CUBRID에서 여러 프로젝트를 진행하느라 시간이 훌쩍 지나갔네요. 그 사이 CUBRID는 11.2 (elderberry) 버전 릴리즈를 지나 11.3 (fig) 버전 릴리즈를 앞두고 있습니다. 이번에도 마찬가지로 [CUBRID의 개발 문화]라는 말머리를 가지고 CUBRID DBMS 프로젝트 빌드에 대한 이야기를 해보려고 합니다. 이전 포스팅의 ‘CUBRID DBMS는 어떻게 개발되고 있을까?’에서 소개했던 개발 프로세스와 프로젝트 기여 가이드의 내용과 조금 주제가 달라보일 수 있는데, 프로젝트 빌드에 대한 내용이 어떻게 개발 문화로까지 이어질 수 있는지 소개해 드리려고 합니다. 빌드 준비하기 누군가 코드를 기여하려고 할 때 빌드는 가장 먼저 해야 하는 첫 발걸음이면서, 동시에 제일 첫 번째로 마주하는 어려움입니다. 먼저 개발 환경에서 프로젝트를 빌드하기 위해서 여러 도구와 라이브러리를 설치하고, 프로젝트의 빌드 방법을 알아야 합니다. 이 때 기여하려... -
Read More
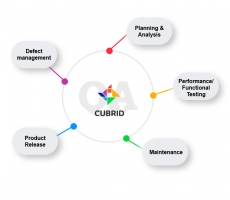
CUBRID QA 절차 및 업무 방식 소개
큐브리드의 QA 절차 및 업무 방식에 대해 소개하겠습니다. CUBRID QA팀이 하는 일? QA(Quality Assurance)팀은 CUBRID의 품질 보증에 대한 전반적인 절차를 다루는 업무를 맡고 있습니다. 단순 테스트뿐만 아니라, 개발 프로세스에 직간접적인 관여와 QA Tool 확장 및 유지보수, 제품 결함 관리, 제품 릴리즈 등 제품이 출시되는 과정에서 여러가지 일을 하고 있습니다. 특히, 개발과정의 처음부터 끝까지 참여하여 품질 저하에 문제가 될 만한 부분이 있는지 검증하고, 개선안을 제안하는 등 개발 프로세스 전반적으로 개입하여 제품 품질을 높이는 일을 하고 있습니다. CUBRID QA 절차 CUBRID QA 절차는 크게 다음과 같이 볼 수 있습니다. 각 절차에 대한 상세한 과정은 다음과 같습니다. 1. Kick off 참여 -먼저, 개발팀으로부터 프로젝트를 할당 받으면, 킥오프를 참여합니다. 요구사항 및 목표를 파악하고, 사용자 관점에 부합하지 않을 경우 개선을 요청합니다. 프로젝트에 따라 검증방법이나 절차가 달라질 수도 있고 때에 따라 새로운 환경이 필요할 수 있기 때문에 여러 가지 의견들을 종합하여 팀 내 담당자를 선정합니다. 2. 테스트 환경 구축 -프로젝트를 위해 어... -
Read More
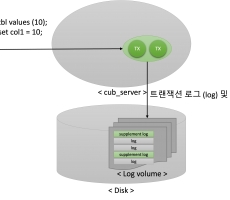
CUBRID Flashback
Introduction 큐브리드 11.2 버전이 릴리즈되면서 Flashback 기능도 함께 소개되었습니다. 아래에서는 큐브리드에서 제공하는 Flashback 에 대한 기능을 이해하기 위한 Background와 흐름, 그리고 사용방법에 대해 소개해드리겠습니다. Background Supplemental logging 사용자가 트랜잭션을 수행하면 트랜잭션 로그가 기록됩니다. 트랜잭션 로그에는 사용자가 변경하기 전의 데이터 (UNDO)와 사용자가 변경한 후의 데이터 (REDO)가 저장됩니다. Flashback에서는 별도의 전용 데이터 공간을 만들기 보다는 이미 로그 볼륨에 저장된 트랜잭션 로그를 사용합니다. 트랜잭션 로그의 UNDO와 REDO를 이용해 사용자가 수행한 SQL구문을 추측합니다. 하지만 트랜잭션 로그에는 데이터베이스의 물리적인 변경에 대한 데이터만을 가지고 있기 때문에, 논리적인 단위 (SQL 구문)으로 반환해야하는 Flashback을 위해서는 추가적인 데이터가 필요합니다. 추가적인 데이터에는 트랜잭션을 수행한 사용자 정보 등이 있으며, 해당 정보는 Supplemental log를 통해 저장됩니다. 따라서, Flashback을 수행하기 위해서는 ‘supplemental_log’ 시스템 파라미터를 1 또는 2로 설정해줘야... -
Read More
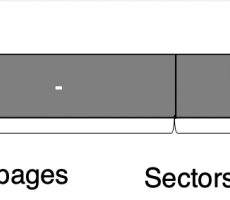
CUBRID Internal: Disk Manager #1: 볼륨 헤더(Volume Header)와 섹터 테이블(Sector Table)
이전글: CUBRID Internal: 큐브리드의 저장공간관리 (DIsk Manager, File Manager) 볼륨은 어떻게 관리될까? - 볼륨 헤더(Volume Header)와 섹터 테이블(Sector Table) - 앞선 글에서 디스크 매니저(Disk Manager)가 섹터의 예약(reservation)을 관리한다고 이야기하였다. 이번 글에서는 볼륨 내의 섹터들이 어떻게 관리되는지에 대한 구체적인 이야기와 이를 위해 볼륨이 어떻게 구성되어 있는지를 다룬다. 여기서 다루어지는 볼륨의 구조는 그대로 non-volatile memory (SSD, HDD 등)에 쓰여진다. 볼륨 구조 디스크 매니저의 가장 큰 역할은 파일생성과 확장을 위해 섹터들을 제공해주는 것이다. 이를 위해 각 볼륨은 파일들에 할당해줄 섹터들과 이를 관리하기 위한 메타(meta)데이터로 이루어져 있다. 메타데이터들이 저장된 페이지를 볼륨의 시스템 페이지(System Page)라고 하며, 볼륨에 대한 정보와 각 섹터들의 예약 여부를 담고 있다. 시스템 페이지는 다음과 같이 두가지로 분류할 수 있다. 볼륨 헤더 페이지 (Volume Header Page, 이하 헤더 페이지): 페이지 크기, 볼륨 내 섹터의 전체/최대 섹터, 볼륨 이름 등, 볼륨에 대한 정보를 지니고 있는 페이지 섹터 테이... -
Read More
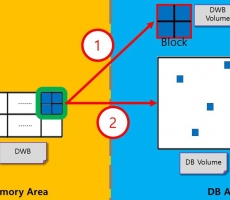
CUBRID Internal: 큐브리드 데이터의 디스크 저장 (Double Write Buffer)
들어가며 데이터베이스의 데이터는 디스크로부터 메모리에 할당되어서 읽힌 다음 수정을 하기도 하고, 새로이 생성되어 메모리에 할당되는 데이터가 있다. 이러한 데이터는 결과적으로는 디스크에 저장되어야 영구적으로 저장됨을 보장할 수 있다. 이 글에서는 큐브리드에서 데이터를 디스크에 저장하는 방법 중 하나를 소개하여서 큐브리드 제품에 대한 이해를 돕고자 한다. 현재 글을 쓰는 시점의 버전은 11.2이다. Double Write Buffer Double Write Buffer의 정의, 목적, 매커니즘을 거쳐 모듈에 대해 전반적인 설명을 하고자 한다. Double Write Buffer 란? 큐브리드는 기본적으로 Double Write Buffer를 통해서 디스크에 데이터를 저장한다. Double Write Buffer는 메모리와 디스크 양쪽에 구성되어 있는 버퍼영역이다. 기본적으로 2M의 크기로 설정되어 있으며, cubrid.conf 파일 내에서 그 크기를 32M까지 조절 할 수 있다. Note 큐브리드에서는 Double Write Buffer를 사용해서 DB페이지를 디스크에 저장하는 방법과 DB 페이지를 바로 디스크에 저장하는 방법이 있다. 이번 글에서는 Double Write Buffer를 사용해서 저장하는 방법만 언급하도록 하겠다. Double Write...