ANTLR, StringTemplate를 사용해서 PL/SQL을 CUBRID Java SP로 변환하기
CUBRID DBMS(이하 'CUBRID')는 PL/SQL을 지원하지 않습니다.
PL/SQL 문법으로 함수나 서브 프로그램을 만들어서 해왔던 작업들을 CUBRID에서 하려면 Java Stored Function/Procedure(이하 'Java SP')으로 변환해야 합니다.
데이터베이스 개발자나 관리자, 엔지니어는 PL/SQL 문법에는 친숙하지만 프로그래밍 언어에는 친숙하지 않은 경우가 대부분입니다.
또한 어플리케이션 개발은 사용하는 DBMS에 따라 달라지는 부분이 거의 없지만 PL/SQL을 Java SP로 변환하는 것은 새로운 시스템을 개발하는 느낌을 받아서 어려움을 느끼는 것 같습니다.
그래서 PL/SQL 을 Java SP 쉽게 변환하는 방법에 대해서 찾아보던 중 ANTLR에 대해서 알게 되었습니다.
ANTLR는 파서를 만드는 도구입니다.
전세계에 있는 컨트리뷰터들로부터 도움을 받아서 다양한 프로그래밍 언어들의 파싱할 수 있도록 문법 파일들을 지원하고 있습니다.
공식 홈페이지에서는 ANTLR에 대해서 아래와 같이 소개하고 있습니다.
"ANTLR (ANother Tool for Language Recognition)은 구조화 된 텍스트 또는 이진 파일을 읽고, 처리하고, 실행하거나 번역하기위한 강력한 파서 생성기입니다. 언어, 도구 및 프레임 워크를 구축하는 데 널리 사용됩니다. 문법에서 ANTLR은 구문 분석 트리를 구축하고 탐색 할 수있는 구문 분석기를 생성합니다. (https://www.antlr.org/ - What is ANTLR?)"
이 글에서는 ANTLR 개발환경을 구성하는 방법과 PL/SQL 문법 파일에서 파서 클래스들을 만들어내는 방법을 알아보고,
미리 개발한 PL/SQL을 Java SP로 변환하는 클래스를 테스트해보겠습니다.
ANTLR 개발환경은 Intellij, NetBeans, Eclipse, Visual Studio Code, Visual Studio, jEdit 등의 다양한 IDE 도구들을 사용해서 구성할 수 있습니다.
이 글에서는 Eclipse를 사용했습니다.
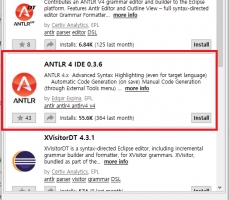
1. Eclipse에 'ANTLR 4 IDE' 설치
Eclipse에서 ANTLR를 사용하기 위해서는 'Help > Eclipse Marketplace...' 에서 ANTLR 4 IDE를 설치해야 합니다.
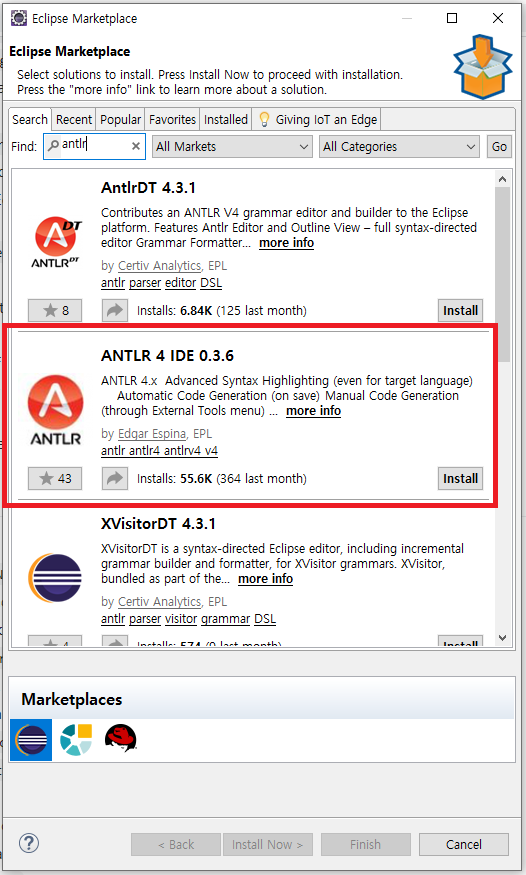
ANTLR 4 IDE를 설치하고 나면 'General > ANTLR 4 Project' 로 프로젝트를 생성할 수 있습니다.
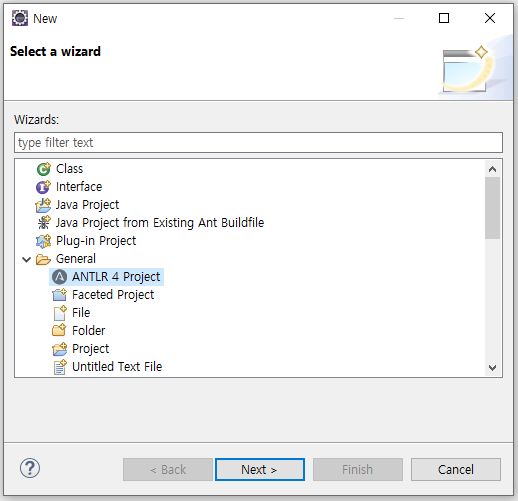
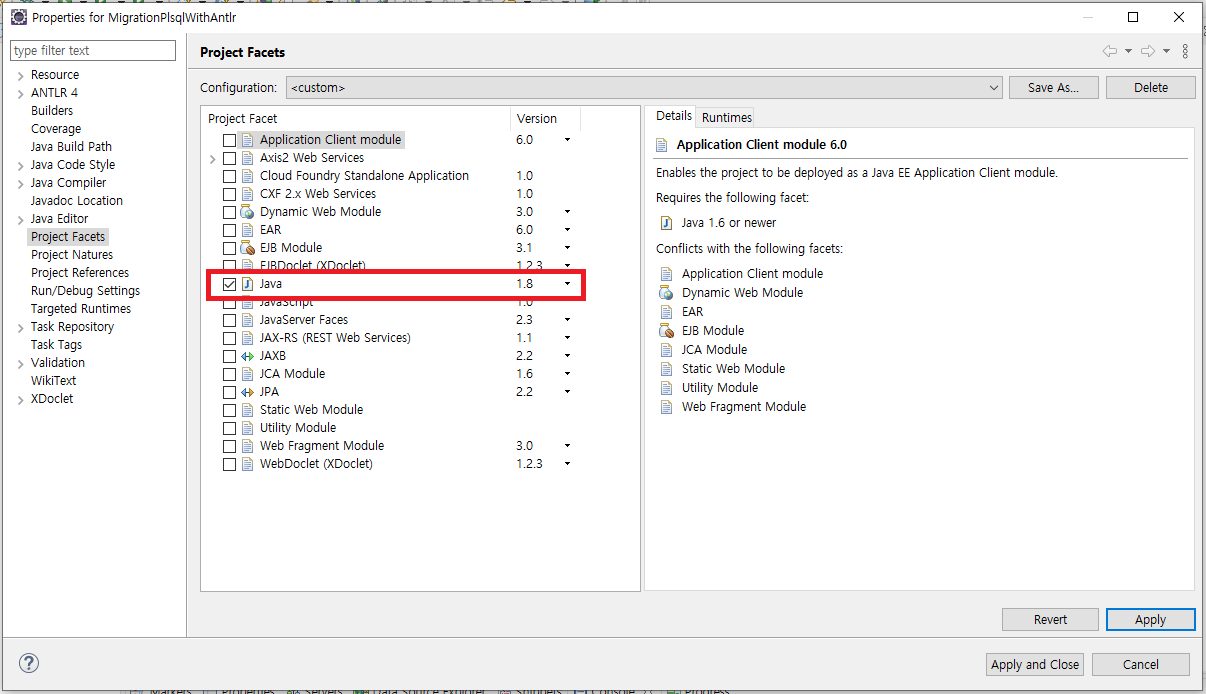
ANTLR 프로젝트 생성을 마치면 프로젝트 설정에서 'Project Facets > Java'를 선택하고 적용합니다.
2. 프로젝트 'Java Build Path > Libraries'에 antlr-4.9-complete.jar 파일 추가
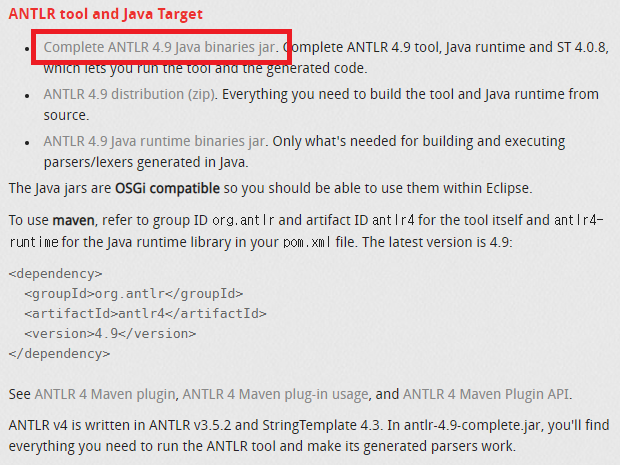
ANTLR 4 IDE는 설치했지만 ANTLR를 사용하기 위해서는 antlr-4.9-complete.jar 파일이 필요합니다.
이 파일은 공식 홈페이지에서 다운로드 받을 수 있으며, 다운로드를 받으면 'Java Build Path > Libraries'에 추가해줘야 합니다.
- 다운로드 : https://www.antlr.org/download.html

3. PL/SQL 문법 파일에서 파서 클래스들을 만들어내는 방법
여기까지 ANTLR 개발환경 구성을 마쳤습니다.
ANTLR로 PL/SQL 파서 클래스들을 만들어내려면 PL/SQL 문법 파일이 필요합니다.
문법 파일은 ANTLR에서 지원하고 있으며, GitHub(antlr/grammars-v4)에서 받을 수 있습니다.
파서 클래스들을 만든 후에 필요한 기본 파서 클래스 파일들도 있으니 같아 다운로드 받아야 합니다.
- 다운로드 : https://github.com/antlr/grammars-v4/tree/master/sql/plsql
- 다운로드 파일 :
* java/PlSqlLexerBase.java
* java/PlSqlParserBase.java
* PlSqlLexer.g4
* PlSqlParser.g4
PL/SQL 코드를 파싱할 때 소문자로 되어 있으면 에러가 발생합니다.
이 문제를 해결하기 위해서 ANTLR는 파싱하기 전에 PL/SQL 코드를 대문자로 변환하라고 합니다.
CaseChangingCharStream 클래스를 다운로드 받아서 파싱하기 전에 사용하면, 이 문제를 우회할 수 있습니다.
메인 함수를 보면 PlSqlLexerd 클래스에 PL/SQL 코드를 전달하기 전에 CaseChangingCharStream 클래스를 사용하고 있습니다.
- 다운로드 : https://github.com/antlr/antlr4/tree/master/doc/resources
- 다운로드 파일 :
* CaseChangingCharStream.java

4. PL/SQL 문법 파일에서 파서 클래스들을 만들어내는 방법
다운로드 받은 문법 파일들을 ANTLR 프로젝트에 추가하고 'Run AS > Generate ANTLR Recognizer'를 실행하면 PL/SQL을 파싱하기 위한 파서 클래스들이 만들어집니다.
이 클래스 파일들이 Default Package 상태로 있으면 별도의 파서 클래스를 개발할 때 Import 해서 사용할 수 없습니다.
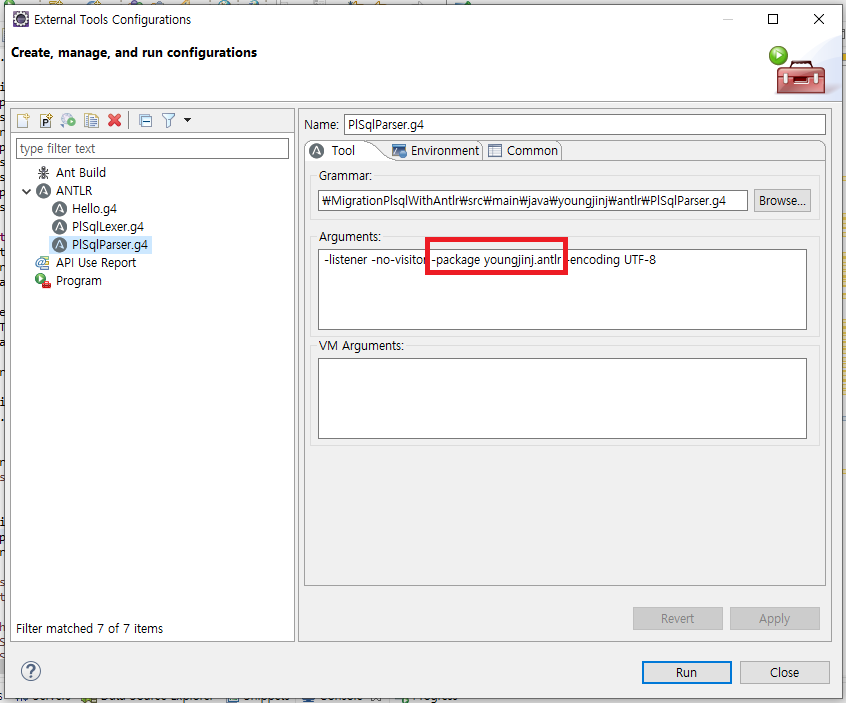
Generate ANTLR Recognizer 옵션에 패키지 설정을 추가하면, 'Run AS > Generate ANTLR Recognizer'를 실행했을 때 패키지 구조로 *.java 파일들을 만듭니다.
'Run As > External Tools Configurations... > ANTLR > Arguments'에 '-package <패키지명>'을 추가하면 됩니다.
패키지 설정은 문법 파일 2개(PlSqlLexer.g4, PlSqlParser.g4) 모두 해야 합니다.
'Run AS > Generate ANTLR Recognizer'를 실행하면 패키지로 묶이더라도 파서 클래스들은 'target > generated-sources > antlr4' 디렉터리에 만들어집니다.
Eclipse에서 이 파일들을 소스로 인지하게 하려면 'Java Build Path > Source'에 'target > generated-sources > antlr4' 디렉터리를 추가해야 합니다.


5. 만들어진 파서 클래스들로 PL/SQL 파싱
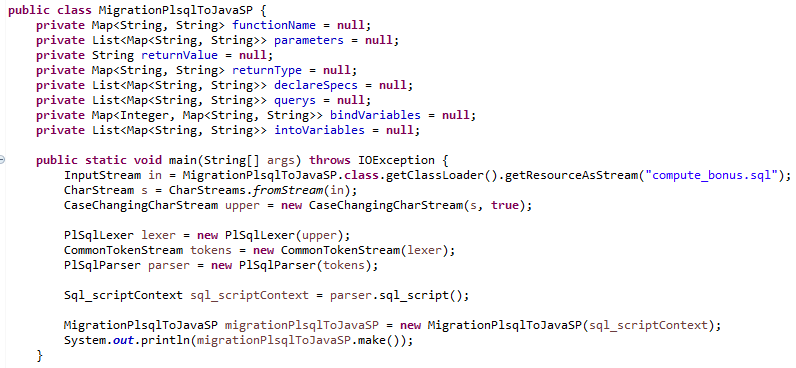
MigrationPlsqlToJavaSP 클래스는 compute_bonus.sql 파일에 있는 PL/SQL 코드를 읽어서 Java SP로 변환합니다.
PlSqlLexer와 PlSqlParser 클래스는 PL/SQL 문법 파일들을 사용해서 ANTLR가 만든 파서 클래스 파일들입니다.
PL/SQL 파싱은 'parser.sql_script();' 코드에서 시작합니다.
파싱한 결과로 반환하는 Sql_scriptContext 클래스의 자식 클래스를 따라가면서 Java SP를 만드는데 필요한 데이터들을 뽑아내고, 가공할 수 있습니다.
마지막으로 MigrationPlsqlToJavaSP 클래스에서 호출하는 make() 메소드는 StringTemplate을 사용해서 Java SP 클래스 파일을 만듭니다.
6. 미리 개발한 PL/SQL을 Java SP로 변환하는 클래스를 테스트
compute_bonus.sql 파일에 있는 PL/SQL을 Oracle에서 실행한 결과입니다.
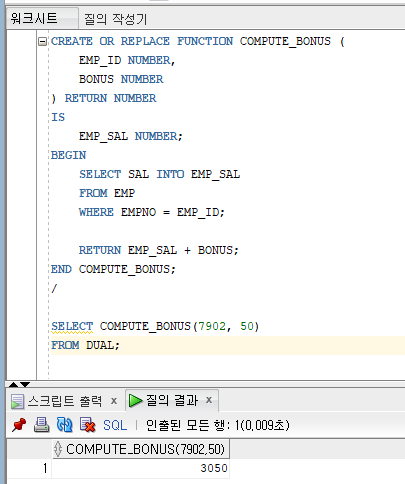
compute_bonus.sql 파일을 파싱한 결과를 따라가면서 Java SP를 만드는데 필요한 데이터를 뽑아내고, 가공합니다.

파싱해서 뽑아낼 데이터를 Java SP로 만들기 위해 템플릿 문법을 제공하는 StringTempate를 사용하고 있습니다.
공식 홈페이지에서는 StringTemplate에 대해서 아래와 같이 소개하고 있습니다.
"StringTemplate은 소스 코드, 웹 페이지, 이메일 또는 기타 형식화 된 텍스트 출력을 생성하기위한 Java 템플릿 엔진 (C #, Objective-C, JavaScript, Scala 용 포트 포함)입니다. (https://www.stringtemplate.org/ - What is StringTemplate?)"

아래는 Java SP로 변환됝 Java 코드입니다.

Oracle에 있는 예제 테이블은 그대로 CUBRID로 이관해서 테스트를 진행했습니다.

Oracle에서 PL/SQL을 실행했을 때와 동일한 결과를 출력합니다.
마무리...
아직은 PL/SQL 함수에서 SELECT 쿼리가 실행되는 것만 변환할 수 있습니다.
PL/SQL 코드에서 쿼리가 실행될 수도 있고, 단순 연산만 해서 결과값을 반환하는 경우도 있습니다.
ANTLR 문법을 보면 이런 부분들을 다 파싱할 수 있지만 Java 코드로 변환하기가 까다로운 부분들이 있어서 아직 진행하지 못했습니다.
시간이 되면 Java SP로 변환하는 부분도 다듬고, 파싱하기만 하고 변환하지 못하는 부분도 추가해서 PL/SQL을 Java SP로 쉽게 변환해주는 도구를 만들어보고 싶습니다.
ANLTR는 PL/SQL 외에도 다양한 프로그래밍 언어의 문법을 지원하기 때문에 잘 사용하면 좋은 도구가 될 것 같습니다.
참고
1. ANTLR
- 공식 홈페이지 : https://www.antlr.org/
- 문서 : https://github.com/antlr/antlr4/blob/master/doc/index.md
- 문법 파일
* https://github.com/antlr/grammars-v4
* https://github.com/antlr/grammars-v4/wiki
- ANTLR IDE
* https://www.antlr.org/tools.html
* https://github.com/jknack/antlr4ide
2. StringTemplate
- 공식 홈페이지 : https://www.stringtemplate.org/
 [CUBRID inside] Query Process란?
[CUBRID inside] Query Process란?
 CUBRID를 이용한 스니핑 방지 - 패킷암호화
CUBRID를 이용한 스니핑 방지 - 패킷암호화