
NEWS
-
Read More
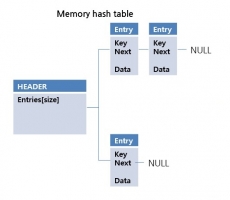
[CUBRID inside] HASH SCAN Method
- HASH SCAN Hash Scan은 hash join을 하기 위한 스캔 방법입니다. view 혹은 계층형 질의에서 Hash Scan이 적용되고 있습니다. view와 같은 부질의가 inner로써 조인될 경우 인덱스 스캔을 사용할 수 없는데, 이 경우 많은 데이터를 반복 조회 하게 되면서 성능 저하가 발생됩니다. 이때 Hash Scan이 사용됩니다. 위 그림은 인덱스가 없는 상황에서의 Nested Loop join과 Hash Scan의 차이를 보여줍니다. NL join의 경우 OUTER의 Row수만큼 INNER의 전체 데이터를 스캔합니다. 이에 반해 Hash Scan은 해시 자료구조 빌드 시 INNER 데이터를 한번 스캔하고, 조회시 OUTER를 한번 스캔합니다. 그렇기 때문에 상대적으로 매우 빠르게 원하는 데이터를 조회할 수 있습니다. 여기서는 Hash Scan의 내부 구조를 프로그램 개발 진행 과정의 흐름으로 작성하였습니다. - IN-MEMORY HASH SCAN CUBRID의 Hash Scan은 데이터양에 따라서 in-memory, hybrid, file hash의 자료 구조를 사용하고 있습니다. 먼저 in-memory 구조부터 살펴보겠습니다. memory의 장점은 random access시 성능 저하가 없다는 점입니다. 하지만 단점은 메모리 크기가 한정되어 있다는 것입니다. 단점 때문에 모든... -
Read More
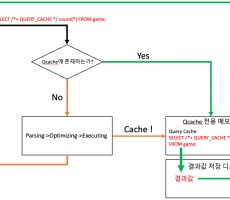
[CUBRID] QUERY CACHE에 대해
QUERY CACHE에 대해 큐브리드 11.0 버전이 출시되면서 QUERY CACHE 힌트를 지원하게 되었습니다. 이 글에서는 QUERY CACHE에 대해 알아보는 시간을 가져보겠습니다. 1. QUERY CACHE란? Query Cache는 SELECT 쿼리문을 이용하여 조회한 값을 저장하고 있다가, 같은 쿼리 문을 요청하였을 때 미리 캐싱된 값을 반환하는 DBMS 기능입니다. 자주 변경되지 않는 테이블이 있고 동일한 쿼리를 많이 받는 환경에서 매우 유용하게 사용될 수 있습니다. QUERY_CACHE 힌트를 사용한 쿼리는 전용 메모리 영역에 캐시되고 그 결과도 별도의 디스크 공간에 캐시됩니다. 쿼리 캐시 특징 1. QUERY_CACHE 힌트는 SELECT 쿼리에만 적용됩니다. 2. 테이블에 변화(INSERT,UPDATE,DELETE)가 일어나게 되면 해당테이블과 관련된 Query Cache내의 정보들은 초기화 됩니다. 3. DB를 내리면 Query Cache는 초기화 됩니다. 4. max_query_cache_entries와 query_cache_size_in_pages 설정 값을 통해 캐시될 크기를 조절할 수 있습니다. (default 값은 모두 0 입니다.) max_query_cache_entries는 최대 캐시할 수 있는 질의 개수에 대한 설정 값으로 1이상으로 설정되면 설정된 수 만큼의 질의가 캐시됩니... -
Read More
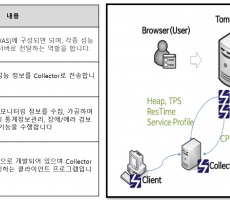
Scouter를 통한 CUBRID 모니터링
Scouter를 통한 CUBRID 모니터링 Scouter 확장을 통해 CUBRID에 항목을 모니터링할 수 있습니다. CUBRID 11.0 버전을 기준으로 개발되었으며, CUBRID 10.2.1 버전부터는 전체 기능을 사용할 수 있습니다. Scouter(Server, Client)는 2.15.0 버전부터 기능 사용이 가능하며, 추후에도 Scouter Github에 참여하여 버그 수정 및 기능이 추가됩니다. 현재(2022-01-10) 2.15.0 버전이 최신 버전이며, Multi Agent 지원 및 버그 수정 내용이 PR 되어 있는 상태입니다. 1. Scouter 란? Scouter는 Open Source APM(Application Performance Management) 이며, 어플리케이션 및 OS 자원등에 대한 모니터링 기능을 제공합니다. Scouter 기본 구성 Scouter 제공 정보 - WAS 기본 정보 각 요청의 응답속도 / 프로파일링 정보, 서버 요청 수 / 응답 수, 처리 중인 요청 수, 응답속도의 평균, JVM 메모리 사용량 / GC 시간 , CPU 사용량 - 프로파일링 정보 서버 간 요청의 흐름, 각 SQL 쿼리의 수행 시간 / 통계, API 호출 수행 시간, request header 정보, 메소드 호출 시 수행 시간 대표적인 Agent 목록 - Tomcat Agent (Java Agent) : JVM 과 Tomcat WAS 성능 수집 - Host Agent (OS Agen... -
Read More
이노베이션 아카데미와 CUBRID의 산학협력
이노베이션 아카데미 (42서울) 42SEOUL(42서울)은 아키텍트급 소프트웨어 인재를 양성하는 것을 목적으로 하는 교육 과정이며, 프랑스에서 시작된 에꼴42의 교육 방식 및 인프라를 수입하여 운영하는 형태를 띈다. 에꼴42(Ecole 42)는 프랑스의 대형 통신사 CEO이기도 한 자비에 니엘(Xavier Niel)이라는 억만장자가 프랑스에서 2013년에 설립했다. 설립 당시에도 자기주도 학습 및 동료 평가를 내세운 무료 소프트웨어 교육 기관이라는 점으로 주목받았다. 현재는 브라질, 미국, 일본 등 세계 여러 곳에도 42 캠퍼스가 있다. 2019년에 대한민국 서울에도 42 서울 캠퍼스가 들어왔다. 42의 특징 중 하나로, 자기주도적 학습을 지향하기에 교재나 교수가 따로 없고 모든 것은 스스로 인터넷 또는 각종 도서 등을 통하거나 동료들과의 협업 및 교류를 통해 학습을 하게끔 유도한다. 교육생들 스스로 방법을 찾아 나아가라는 의도이며, 정해진 교재 및 교수가 없기 때문에 필연적으로 많은 삽질과 불분명한 요구사항을 맞닥뜨리게 된다. 심지어 문제를 풀어야 하는데, 뭘 배우고 공부해야 하는지 조차도 제대로 알려주지 않는다. 이는 소프트웨어 현장을 그대로 모방하여 실전 경... -
Read More
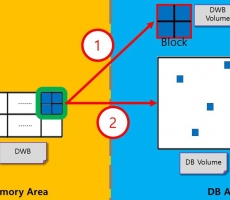
CUBRID Internal: 큐브리드 데이터의 디스크 저장 (Double Write Buffer)
들어가며 데이터베이스의 데이터는 디스크로부터 메모리에 할당되어서 읽힌 다음 수정을 하기도 하고, 새로이 생성되어 메모리에 할당되는 데이터가 있다. 이러한 데이터는 결과적으로는 디스크에 저장되어야 영구적으로 저장됨을 보장할 수 있다. 이 글에서는 큐브리드에서 데이터를 디스크에 저장하는 방법 중 하나를 소개하여서 큐브리드 제품에 대한 이해를 돕고자 한다. 현재 글을 쓰는 시점의 버전은 11.2이다. Double Write Buffer Double Write Buffer의 정의, 목적, 매커니즘을 거쳐 모듈에 대해 전반적인 설명을 하고자 한다. Double Write Buffer 란? 큐브리드는 기본적으로 Double Write Buffer를 통해서 디스크에 데이터를 저장한다. Double Write Buffer는 메모리와 디스크 양쪽에 구성되어 있는 버퍼영역이다. 기본적으로 2M의 크기로 설정되어 있으며, cubrid.conf 파일 내에서 그 크기를 32M까지 조절 할 수 있다. Note 큐브리드에서는 Double Write Buffer를 사용해서 DB페이지를 디스크에 저장하는 방법과 DB 페이지를 바로 디스크에 저장하는 방법이 있다. 이번 글에서는 Double Write Buffer를 사용해서 저장하는 방법만 언급하도록 하겠다. Double Write... -
Read More

[CUBRID INSIDE] 부질의와 QUERY REWRITER (view merging, subquery unnest)
- 부질의란? 질의가 질의안에서 다시 작성되는 것을 부질의라고 합니다. 이러한 부질의 덕분에 우리는 더 쉽게 하나의 질의로 원하는 데이터를 추출할 수 있습니다. 예를 들면 작년 평균 연봉보다 높은 직원을 추출해야 한다면 아래와 같이 부질의를 사용할 수 있습니다. 평균연봉을 구해서 다시 질의를 하지 않고 위와 같이 하나의 질의로 작성이 가능합니다. 너무 당연한 질의의 사용 방법이지만 사용이 불가했다면 많이 불편했겠죠. 이러한 부질의는 특별한 성질을 가지는 데 어느 부분에 작성되느냐에 따라서 가지는 성질이 달라집니다. - scalar subquery : SELECT 절의 부질의. 한 개의 데이터만 조회 가능. - inline view : FROM 절의 부질의. 여러 개의 데이터 조회 가능. - subquery : WHERE 절의 부질의. 연산자에 따라 scalar subquery 혹은 inline view의 성질. 부질의 사용은 질의를 더 다양하게 작성할 수 있도록 하지만 반대로 질의 성능에 악영향을 줄 수 있습니다. - 부질의 실행 순서와 성능 저하 원인 부질의는 주질의보다 항상 먼저 수행되어 임시 결과를 저장해놓습니다. 그리고 주질의가 수행되면서 부질의의 임시 저장된 데이터를 조회하여 원하는 결과... -
Read More
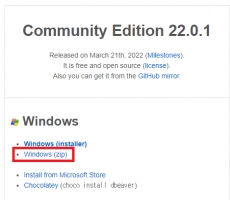
DBeaver Database Tool 큐브리드 사용하기 2
1. 들어가며 https://www.cubrid.com/index.php?mid=blog&page=2&document_srl=3827667 본문을 읽기 전에 위 링크의 글을 읽어보시는 것을 추천 드립니다. 2. CUBRID 사용 시 유의 사항 현재 DBeaver에서 CUBRID를 완벽하게 지원하고 있지 않기 때문에 사용할 수 없거나 누락된 기능이 존재합니다. 몇 가지 예시는 다음과 같습니다. Trigger, Sequence 정보 확인 불가 FK의 ON DELETE / ON UPDATE 옵션 수정 불가 column 생성 기능 사용시, Data Type, auto_increment, collation등 몇가지 기능 누락 및 사용 불가 뷰 테이블 생성, 수정 불가 JavaSP 확인 불가 Query Execute Plan 확인 불가 따라서 위에 기록된 기능을 사용해야 할 경우 Query를 직접 작성하여 사용하는 것이 권장됩니다. 2. DBeaver 설치 방법 위 글에서는 DBeaver를 installer를 통해 설치하는 것을 설명하고 있습니다. DBeaver는 Eclipse RCP 프로그램이기 때문에 installer를 사용하지 않고 설치할 수 있는 방법이 두가지가 더 있습니다. - zip을 활용한 portable 버전 설치 - Eclipse 내부의 plugin 방식을 통한 설치 * zip을 활용한 portable 버전 설치 이 글에서는 윈도우 기준으로 설명하고 ... -
Read More
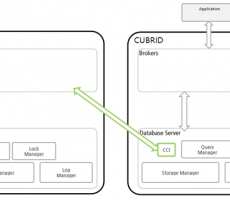
CUBRID DBLink
CUBRID DBLink 란 데이터베이스에서 정보를 주고받다 보면 종종 다른 타 데이터베이스의 정보 조회가 필요한 경우가 있다. 이렇게 타 데이터베이스의 정보를 조회할 수 있는 방법이 필요 하게 되었으며, CUBRID DBLink를 이용하면 타 데이터베이스의 정보를 사용할 수 있다. CUBRID DBLink는 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘한다. 단 타 데이터베이스를 여러 게 설정이 가능 하나, 정보를 조회할 때는 한개의 타 데이터베이스의 정보만 조회가 가능하다. 1. CUBRID DBLink 구성도 CUBRID DBLink는 동일기종 간에 DBLink 와 이기종 간의 DBLink를 지원한다. - 동일기종 간의 DBLink 구성도 동일기종의 타 데이터베이스의 정보를 조회하기 위한 구성도를 보면 Database Server에서 CCI를 이용하여 동일기종의 Brokers에 접속하여 타 데이터베이스의 정보를 조회할 수 있다. - 이기종 간의 DBLink 구성도 이기종의 타 데이터베이스의 정보를 조회하기 위한 구성도를 보면 GATEWAY를 통해서 이기종 타 데이터베이스의 정보를 조회할 수 ... -
Read More
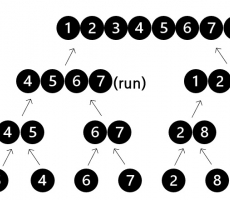
[CUBRID INSIDE] External Sort
External Sort DBMS는 다양한 상황에서 데이터를 정렬합니다. 사용자 요청으로 ORDER BY 절을 통해 정렬하기도 하고, UNION 절이나 DISTINCT 키워드가 사용되었을 때 중복데이터를 제거하기 위해 데이터를 정렬합니다. 그리고 sort merge join과 인덱스 생성시에도 데이터를 정렬합니다. 이렇듯 DBMS에서 정렬은 여러 상황에서 많이 사용되고 있습니다. CUBRID는 어떻게 데이터를 정렬하고 있을까요? external_sort.c 파일을 분석한 내용을 공유합니다. Merge Sort external sort의 기본이 되는 merge sort부터 살펴보겠습니다. merge sort는 데이터를 분할하고 합병을 반복하면서 정렬하는 알고리즘입니다. 정렬이 필요한 데이터를 분할하는데 분할된 조각을 run이라고 합니다. 분할이 완료되면 두 개의 run을 합병합니다. 위 그림은 분할 이후 합병하는 과정을 나타낸 것입니다. 합병을 진행하면 정렬된 새로운 run이 생성됩니다. 합병을 계속 진행하여 한 개의 run이 남을 때까지 반복하면 데이터 정렬이 완료됩니다. 그렇다면 두 run의 합병은 어떻게 진행이 될까요? depth 2의 두 run이 합병되는 과정을 살펴보겠습니다. 위 그림처럼 정렬이 진행됩니다. 두 run이 정렬되... -
Read More
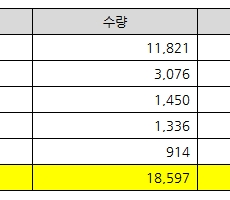
공공부문 DBMS 정보자원 현황
행정안전부/한국지능정보사회진흥원(NIA)에서는 매년 '범정부EA기반 공공부문 정보자원 현황 통계보고서'를 발간합니다. 2022년도 통계보고서는 금년 7월 초에 공개가 되었으며, 최근에 전자신문에서 통계보고서를 기반으로 한 스페셜리포트 기사(공공SW 외산 쏠림 해법은?)를 게재하였습니다. 전자신문 기사에서 공공SW 외산 쏠림 해법으로 2가지를 제시했습니다. 오픈소스 소프트웨어를 활용하여 외산 종속을 탈피하거나 공공부문 SaaS 국산화를 추진하자는 것입니다. 사실 국내 SW 산업은 정보보호, 관제 등 일부 분야를 제외하고 OS, DBMS, WEB/WAS, 백업 등 대부분의 영역에서 외산 편중이 높은 상황입니다. 이제부터 DBMS에 한정해서 조금 더 살펴보겠습니다. 아래 데이터는 2021년 기준이며, Oracle이 63.6%로 여전히 1위 자리를 지키고 있으며, 이어서 Microsoft (SQL Server), 큐브리드, 티맥스데이터(Tibero)가 순위를 차지하고 있습니다. [출처 : 2022년도 범정부EA기반 공공부문 정보자원 현황 통계보고서, 55쪽] 비록 Oracle와 Microsoft의 수량 점유율이 약 80%로 쏠림 현상이 강하게 나타나고 있으나, 큐브리드와 티맥스데이터의 수량을 합치면 15%가 ...