
NEWS
-
Read MoreNo Image
CUBRID to Oracle DBLink
CUBRID DBLink란 데이터베이스에서 정보를 조회하다 보면 종종 외부 데이터베이스의 정보 조회가 필요한 경우가 있습니다.이렇게 외부 데이터베이스의 정보를 조회하기 위해서 CUBRID DBLink를 이용하면 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘합니다. 이 글에서는 CUBRID DBLink와 Oracle의 데이터베이스의 정보를 조회하는 방법을 가이드합니다. 적용 환경 OS 버전 : Centos7 Linux 7 CUBRID 버전 : CUBRID 11.2.1 Oracle 버전 : Oracle21.3.0.0.0 CUBRID DBLink 설정 다음은 CUBRID에서 Oracle DBLink를 위한 설정 방법입니다. 설정에 필요한 부분들은 다음과 같이 설정하였습니다. Oracle Server IP : 192.168.64.152 Oracle Server Port : 1521 Oracle SID : orcl Oracle 계정 : c##test Oracle 계정 암호 : test CUBRID Server IP : 192.168.64.153 CUBRID DB명 : demodb * Oracle 테이블 정보 create table code( s_name char(1), f_name varchar(6) ); 1. Oracle 설정 1-1) Oracle Client, ODBC Driver 설치 Oracle Instant Clien, ... -
Read MoreNo Image
CUBRID to MySQL DBLink
CUBRID DBLink 란 데이터베이스에서 정보를 조회하다 보면 종종 외부 데이터베이스의 정보 조회가 필요한 경우가 있습니다. 이렇게 외부 데이터베이스의 정보를 조회하기 위해서 CUBRID DBLink를 이용하면 CUBRID, Oracle, MySQL의 데이터베이스의 정보를 조회할 수 있도록 기능을 제공하며, 타 데이터베이스의 정보를 마치 하나의 데이터베이스에서 조회하는 것과 같은 효과를 발휘합니다. 이 글에서는 CUBRID DBLink와 MySQL의 데이터베이스의 정보를 조회하는 방법을 가이드합니다. 적용 환경 OS 버전 : CentOS Linux 7 CUBRID 버전 : CUBRID 11.2.1 MySQL 버전 : MySQL 8.0 MySQL 서버 설정 설치되어 있는 MySQL 서버에서 해야하는 설정입니다. 1. MySQL SSL 설정 SQL 8.0 이상부터 ssl이 기본으로 설정되어 있어 설정을 끄고 실행합니다. 변경 후에는 MySQL을 재시작 해야합니다. 파일 위치: /etc/my.cnf ssl=0 ssl이 잘 적용이 되었는지 확인합니다. [root@localhost ~]# show variables like '%ssl%'; +----------+| Variable_name| Value |+-------------------------------------+----------+ | have_openssl | DISABLED | | have_ssl | DISABLED | 2. MySQL ... -
Read More
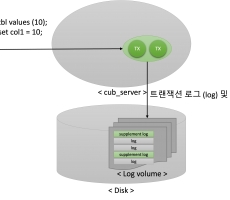
CUBRID Flashback
Introduction 큐브리드 11.2 버전이 릴리즈되면서 Flashback 기능도 함께 소개되었습니다. 아래에서는 큐브리드에서 제공하는 Flashback 에 대한 기능을 이해하기 위한 Background와 흐름, 그리고 사용방법에 대해 소개해드리겠습니다. Background Supplemental logging 사용자가 트랜잭션을 수행하면 트랜잭션 로그가 기록됩니다. 트랜잭션 로그에는 사용자가 변경하기 전의 데이터 (UNDO)와 사용자가 변경한 후의 데이터 (REDO)가 저장됩니다. Flashback에서는 별도의 전용 데이터 공간을 만들기 보다는 이미 로그 볼륨에 저장된 트랜잭션 로그를 사용합니다. 트랜잭션 로그의 UNDO와 REDO를 이용해 사용자가 수행한 SQL구문을 추측합니다. 하지만 트랜잭션 로그에는 데이터베이스의 물리적인 변경에 대한 데이터만을 가지고 있기 때문에, 논리적인 단위 (SQL 구문)으로 반환해야하는 Flashback을 위해서는 추가적인 데이터가 필요합니다. 추가적인 데이터에는 트랜잭션을 수행한 사용자 정보 등이 있으며, 해당 정보는 Supplemental log를 통해 저장됩니다. 따라서, Flashback을 수행하기 위해서는 ‘supplemental_log’ 시스템 파라미터를 1 또는 2로 설정해줘야... -
Read More
DBeaver 환경을 새로운PC에 간편하게 복원하기
현재 Java로 구현된 데이터베이스 관리 툴 중에 가장 인기가 있는 툴이 DBeaver가 아닌가 생각된다. DBeaver 툴은 CUBRID 또한 지원을 해서 SQL Query browser의 기능을 충분히 수행한다. ※ DBeaver 특징 □ Community Edition 버전을 사용하면 라이센스(Apache License)가 무료이다. □ 자바/이클립스 기반으로 개발되어서 윈도우, 리눅스, MAC에서 구동된다. □ JDBC 기반으로 해서 DB를 지원한다. (CUBRID, ORACLE, SQL Server, MySQL, Postgresql ... ) □ 개발소스가 공개되어서 버그픽스가 가능하고 새로운 기능을 개발하여 사용이 가능하다. □ 릴리즈도 거의 2주마다 되기 때문에 버그 픽스또한 매우 빠른 편이다. CURBID를 DBeaver에서 사용하는 방법은 "DBeaver Database Tool 큐브리드 사용하기" 를 참조 하면 도움이 될 것이다. 필자는 해당 툴을 사용하다가 사용하는 PC를 바꾸게 되어 기존 설정을 백업해서 복구 하고자 한다. Workspace를 따로 빼서 사용하지 않은 기본 설정으로 사용하신 분을 기준으로 백업/복구를 가이드 하고자 한다. 순서는 다음과 같다. 1. 먼저 백업하고자 하는 기존의 환경에서 탐색기 창을 연다. 2. 주소/디렉터리 위치 표기창에 %appdata%... -
Read More
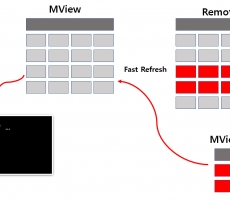
dblink를 이용한 remote-server materialized view 기능
Materialized View Materialized View(이하 MView) 이것은 말 그대로 View의 일종으로 일반 View는 논리적인 스키마인데 반해, MView는 물리적 스키마입니다. 논리적 스키마는 실제 데이터가 데이터베이스에 저장되어 있지 않고 데이터를 가져오기 위한 SQL질의만 저장되어 있다라는 것이고, 물리적 스키마 혹은 테이블이라는 것은 셀제 데이터가 데이터베이스에 저장되어 있다라는 것입니다. MView는 필요한 결과를 가져오는 질의가 빈번하게 자주 사용 될 경우, 질의 실행 시간 속도 향상을 위해 데이터베이스 테이블을 만들어 저장해 두는 것으로 실행 비용이 많이 드는 조인이나, Aggregate Function을 미리 처리하여 필요할 때 테이블을 조회 하도록 하는 것 입니다. 예를 들면 대용량의 데이터를 COUNT, SUM, MIN, MAX, AVG 처럼 자주 사용되는 Aggregate Function 실행 속도를 향상을 위해서, 질의 실행 결과을 데이터베이스 테이블로 생성해 두는 벙법입니다. 즉, 자주사용되는 View의 결과를 데이터베이스에 저장해서 질의 실행 속도를 향상시키는 개념입니다. 이번 글에서는 일반적인 MView와 더불어 현재 작업 중인 데이터베이스 로컬 서버가 아닌 원격지(remote) ... -
Read More
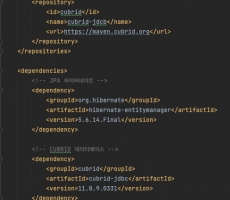
JPA와 CUBRID 연동 가이드
JPA? JPA는 자바의 ORM 기술 표준으로 인터페이스의 모음입니다. 표준 명세를 구현한 구현체들(Hibernate, EclipseLink, DataNucleus)이 있고, JPA 표준에 맞춰 만들면 사용자는 언제든 원하는 구현체를 변경하며 ORM 기술을 사용할 수 있습니다. 이번 CUBRID 연동 가이드에서는 대표적으로 많이 사용하는 Hibernate를 사용하여 작성했습니다. 버전 정보 SpringBoot: 2.7.8 Hibernate: 5.6.14.Final Java: 11 CUBRID: 11.0.10, 11.2.2 JPA와 CUBRID 연동 1) 라이브러리 설정 Maven 프로젝트에 JPA(Hibernate), CUBRID JDBC 라이브러리를 넣기 위해 pom.xml에 설정을 합니다. CUBRID JDBC를 받기 위해 repository도 같이 추가해야 합니다. 2) JPA 설정 필요한 라이브러리를 다 받은 뒤 JPA 설정 파일인 persistence.xml에 설정을 해줘야 합니다. 해당 파일은 표준 위치가 정해져 있기 때문에 /resources/META-INF/ 밑에 위치해야 합니다. DBMS 연결 시 필요한 정보와 JPA 옵션들을 설정해 줍니다. 기본적으로 driver, url, user, password를 설정하고, 방언(dialect)도 필수적으로 설정해야 합니다. DBMS가 제공하는 SQL 문법과 함수들이 조금씩 다르기 때문에 JPA가 어떤 DBMS... -
Read More
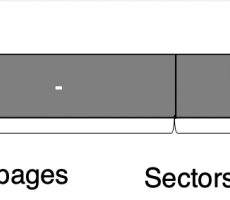
CUBRID Internal: Disk Manager #1: 볼륨 헤더(Volume Header)와 섹터 테이블(Sector Table)
이전글: CUBRID Internal: 큐브리드의 저장공간관리 (DIsk Manager, File Manager) 볼륨은 어떻게 관리될까? - 볼륨 헤더(Volume Header)와 섹터 테이블(Sector Table) - 앞선 글에서 디스크 매니저(Disk Manager)가 섹터의 예약(reservation)을 관리한다고 이야기하였다. 이번 글에서는 볼륨 내의 섹터들이 어떻게 관리되는지에 대한 구체적인 이야기와 이를 위해 볼륨이 어떻게 구성되어 있는지를 다룬다. 여기서 다루어지는 볼륨의 구조는 그대로 non-volatile memory (SSD, HDD 등)에 쓰여진다. 볼륨 구조 디스크 매니저의 가장 큰 역할은 파일생성과 확장을 위해 섹터들을 제공해주는 것이다. 이를 위해 각 볼륨은 파일들에 할당해줄 섹터들과 이를 관리하기 위한 메타(meta)데이터로 이루어져 있다. 메타데이터들이 저장된 페이지를 볼륨의 시스템 페이지(System Page)라고 하며, 볼륨에 대한 정보와 각 섹터들의 예약 여부를 담고 있다. 시스템 페이지는 다음과 같이 두가지로 분류할 수 있다. 볼륨 헤더 페이지 (Volume Header Page, 이하 헤더 페이지): 페이지 크기, 볼륨 내 섹터의 전체/최대 섹터, 볼륨 이름 등, 볼륨에 대한 정보를 지니고 있는 페이지 섹터 테이... -
Read MoreNo Image
Index의 capacity에 관한 정보 열람
Index Capacity 정보 들어가며 DBMS의 여러 기능 기능이나 구성 요소들 중에서 가장 중요한 것은 무엇일까요? Index는 '가장' 중요한은 아니더라도 적어도 '아주 아주' 중요한 요소가 아닐까 생각 합니다. Index가 없다면 데이터를 쌓아 두기만 할 수 있을 뿐 사실상 관리는 못하는 그런 시스템이 될 테니까요. 자료가 많으면 많을 수록 Index는 더 중요해 집니다. 이렇게 중요한 Index를 분석할 때에도 목적에 부합하는 여러가지 도구와 방법들이 있을 수 있습니다. 이 페이지에서는 그 중에서 Index의 Capaicty에 대한 정보를 리뷰해 보고자 합니다. 기본적인 사용 방법이나 설명은 매뉴얼을 통해 얻을 수 있으므로 여기서 설명은 생략합니다. INDEX CAPACITY 정보 얻기 우선 CUBRID에서는 Index의 Capacity 정보를 다음과 같은 두 가지 방법으로 쉽게(?) 알아 볼 수 있습니다. 1. diagdb tool ------------------------------------------------------------- BTID: {{0, 5952}, 5953}, idx0 ON dba.tbl, CAPACITY INFORMATION: Distinct Key Count: 0 Total Value Count: 0 Average Value Count Per Key: 0 Total Page Count: 2 Leaf Page Count: 1 NonLea... -
Read MoreNo Image
CSQL에서 PreparedStatement 사용하여 Query Plan 확인하기
CSQL에서 PreparedStatement 사용하여 Query Plan 확인하기 Prepare statement를 이용하여 값을 질의에 포함하지 않고 bind 했을 경우와 질의상에 값을 직접 포함하였을 경우, 일부 상황에서 값에 대한 해석이 모호해져 질의 플랜이 다르게 만들어져 질의의 성능이 달라지는 경우가 있습니다. 이를 위해 csql 에서 prepare statement 사용하는 방법을 정리하였습니다. 아래 확인 예시는 11.2 에서 해결된 부분이나, 그 이전 부분에서 질의 수행 계획이 달라졌음에 대한 이해를 위해 사용하였습니다. CSQL에서 PreparedStatement 사용 1. Prepared Statement 생성 PREPARE stmt_name FROM 'sql문'; 2. Prepared Statement 실행 EXECUTE stmt_name [USING value, value2 ...]; 3. Prepared Statement 해제 {DEALLOCATE | DROP} PREPARE stmt_name; 사용 예시(2가지) 1. csql > PREPARE pstmt FROM 'SELECT 1 + ?'; csql > EXECUTE pstmt USING 4; csql > DROP PREPARE pstmt; 2. csql > PREPARE pstmt FROM 'SELECT col1 + ? FROM tbl WHERE col2 = ?'; csql > SET @a=3, @b='abc'; csql > EXECUTE pstmt USING @a, @b; csql > DROP PREPARE pst... -
Read More
CUBRID의 개발 문화: CUBRID DBMS 프로젝트 빌드 가이드와 빌드 시스템 개선
시작하며 이전 포스팅에서 CUBRID의 개발 문화: CUBRID DBMS는 어떻게 개발되고 있을까? 라는 주제로 블로그 글을 작성했었던 기억이 납니다. 날짜를 들여다보니 2021년 4월 29일에 작성되었으니 코로나 팬데믹을 이겨내고 CUBRID에서 여러 프로젝트를 진행하느라 시간이 훌쩍 지나갔네요. 그 사이 CUBRID는 11.2 (elderberry) 버전 릴리즈를 지나 11.3 (fig) 버전 릴리즈를 앞두고 있습니다. 이번에도 마찬가지로 [CUBRID의 개발 문화]라는 말머리를 가지고 CUBRID DBMS 프로젝트 빌드에 대한 이야기를 해보려고 합니다. 이전 포스팅의 ‘CUBRID DBMS는 어떻게 개발되고 있을까?’에서 소개했던 개발 프로세스와 프로젝트 기여 가이드의 내용과 조금 주제가 달라보일 수 있는데, 프로젝트 빌드에 대한 내용이 어떻게 개발 문화로까지 이어질 수 있는지 소개해 드리려고 합니다. 빌드 준비하기 누군가 코드를 기여하려고 할 때 빌드는 가장 먼저 해야 하는 첫 발걸음이면서, 동시에 제일 첫 번째로 마주하는 어려움입니다. 먼저 개발 환경에서 프로젝트를 빌드하기 위해서 여러 도구와 라이브러리를 설치하고, 프로젝트의 빌드 방법을 알아야 합니다. 이 때 기여하려...