목차
1. 개요
2. B+ 트리의 노드(= 페이지)
2.1. 오버플로 노드 (BTREE_OVERFLOW_NODE)
2.2. PAGE_OVERFLOW 페이지
3. 노드 분할
3.1. 노드 분할이 발생하는 경우
3.1.1. 새로운 키가 입력되는 경우
3.1.2. 기존 키의 크기가 증가하는 경우
3.1.3. 기존 레코드에 테이블 레코드의 OID가 추가되는 경우
3.1.4. 기존 레코드에 MVCC 아이디가 추가되는 경우
3.2. 사용자가 키를 입력하는 패턴에 따라 달라지는 노드 분할 #1
3.2.1. 시나리오 #1 - 1부터 27까지 오름차순으로 증가하는 패턴으로 키를 입력하는 경우
3.2.2. 시나리오 #2 - 1부터 27까지 불규칙 패턴으로 키를 입력하는 경우
3.2.3. 비교 결과
4. 똑똑하게 노드 분할하기
4.1. 사용자가 키를 입력하는 패턴에 따라 달라지는 노드 분할 #2
4.1.1. 오름차순으로 증가하는 패턴으로 키를 입력하는 경우
4.1.2. 내림차순으로 감소하는 패턴으로 키를 입력하는 경우
4.1.3. 불규칙 패턴으로 키를 입력하는 경우
5. 루트 노드 → 브랜치 노드 → 리프 노드 순서의 노드 분할
6. 참고
개요
큐브리드는 B+ 트리 인덱스를 사용하고 있습니다. B+ 트리 인덱스는 새로운 키가 입력되거나 기존 레코드가 변경될 때, B+ 트리를 유지하기 위해서 노드의 분할 또는 병합이 발생할 수 있습니다. 노드는 B+ 트리를 구성하는 가장 작은 단위로, 하나의 노드는 데이터베이스에서 하나의 페이지에 해당합니다. 이 글에서는 노드가 되는 페이지에 대해서 살펴보고, 노드 분할이 발생하는 경우와 그 과정에 대해서 알아보겠습니다.
예시의 모든 질의는 11.3.0.1089-bd31bd5 버전에서 실행했습니다.
B+ 트리의 노드(= 페이지)
데이터베이스의 모든 데이터는 페이지에 저장되며, 모든 페이지는 슬롯 페이지 구조(Slotted Page Structure)로 되어 있습니다. 슬롯 페이지 구조에 대해 더 알고 싶다면 "CUBRID 슬랏 페이지(slotted page) 구조 살펴보기" 글을 참고해주세요. 모든 페이지는 페이지 헤더(SPAGE_HEADER)를 포함하고 있습니다. 페이지는 페이지 헤더의 페이지 타입(PAGE_TYPE)을 통해 어떤 테이터를 저장하고 있는지를 구분할 수 있습니다. 페이지 타입에 따라 추가로 필요한 헤더를 가질 수 있습니다. B+ 트리의 노드는 페이지 타입이 PAGE_BTREE인 페이지입니다. PAGE_BTREE 페이지는 페이지 헤더와 페이지 타입에 필요한 노드 헤더(BTREE_NODE_HEADER) 또는 오버플로 헤더(BTREE_OVERFLOW_HEADER)를 가지고 있습니다.
일반적으로 B+ 트리는 노드를 3 계층으로 구분합니다. 가장 상위 노드를 루트(Root) 노드, 가장 하위 노드를 리프(Leaf) 노드, 루트와 리프 사이에 있는 노드를 브랜치(Branch) 노드라고 합니다. 노드가 어느 계층의 노드인지는 노드 헤더가 가지고 있는 노드 레벨 (node_level)로 확인할 수 있습니다. 리프 노드의 노드 레벨은 항상 1이며, 루트 노드의 노드 레벨은 B+ 트리의 높이입니다. B+ 트리의 높이가 3인 경우, 브랜치 노드의 노드 레벨은 2가 되고, 루트 노드의 노드 레벨은 3이 됩니다.
노드 레벨에 따라서 노드 타입을 구분하고 있습니다. 노드 타입은 리프가 아닌 노드(BTREE_NON_LEAF_NODE), 리프 노드(BTREE_LEAF_NODE), 오버플로 노드(BTREE_OVERFLOW_NODE) 등 3가지가 있습니다. 노드 레벨이 1인 경우 노드의 노드 타입은 BTREE_LEAF_NODE(리프 노드)가 되며, 노드 레벨이 1보다 큰 경우 BTREE_NON_LEAF_NODE(리프가 아닌 노드)가 됩니다. B+ 트리의 높이가 1인 경우에는 인덱스를 구성하는 페이지가 1개이고, 루트 노드의 노드 레벨이 1이기 때문에 루트 노드의 노드 타입이 BTREE_LEAF_NODE(리프 노드)가 됩니다. 오버플로 노드에 대해서는 좀 더 아래에서 알아보겠습니다.
|
1
2
3
4
5
6
7
8
|
/* src/storage/btree.h */
typedef enum
{
BTREE_LEAF_NODE = 0,
BTREE_NON_LEAF_NODE,
BTREE_OVERFLOW_NODE
} BTREE_NODE_TYPE;
|
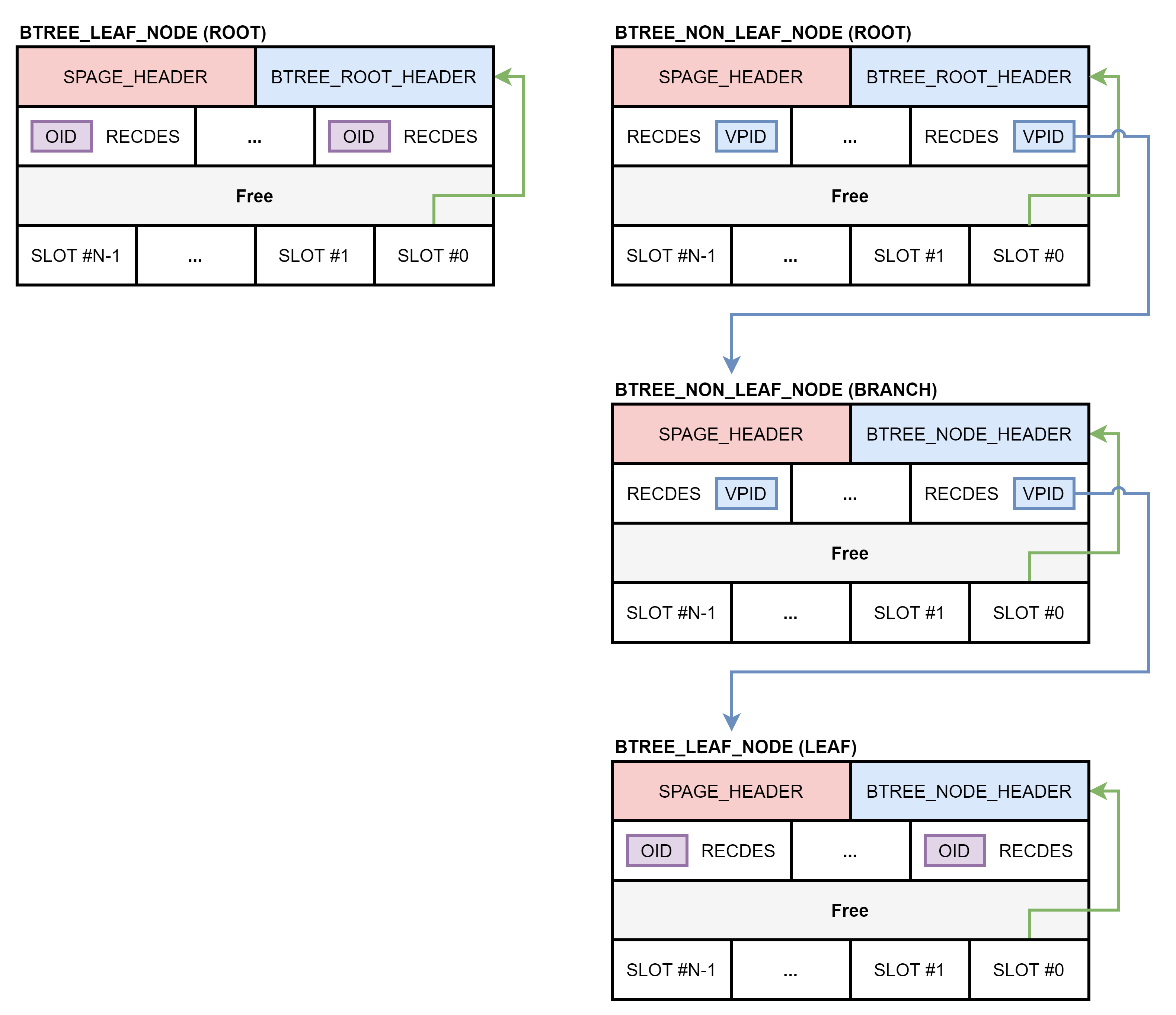
루트 노드는 루트 헤더(BTREE_ROOT_HEADER)를 가지고 있습니다. 루트 헤더는 노드 헤더를 포함하고 있고, 인덱스 전체에 대한 메타 정보를 저장하고 있습니다. 브랜치 노드와 리프 노드는 노드 헤더만 가지고 있습니다.
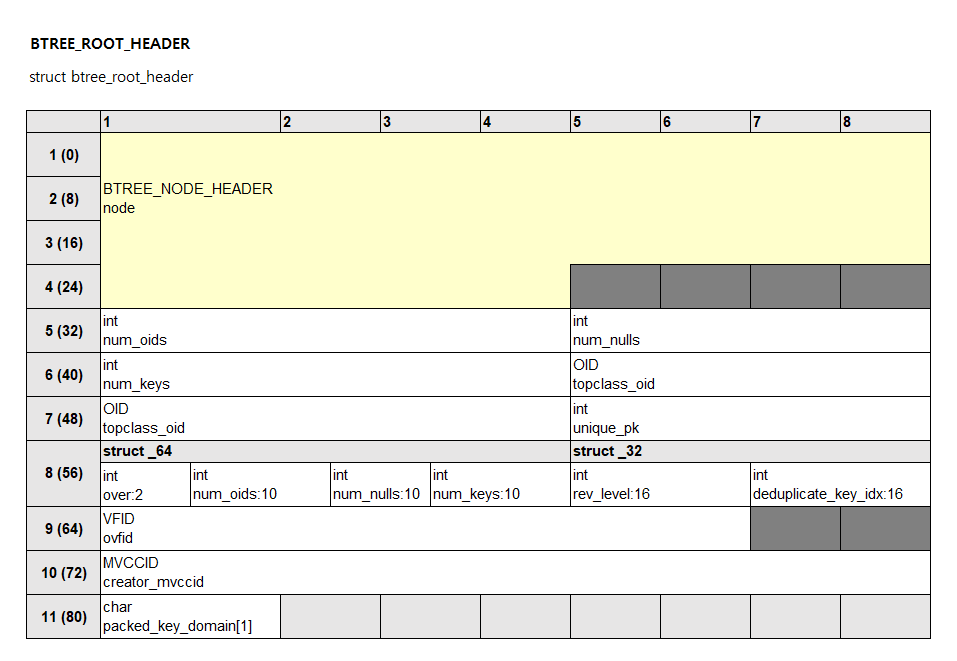
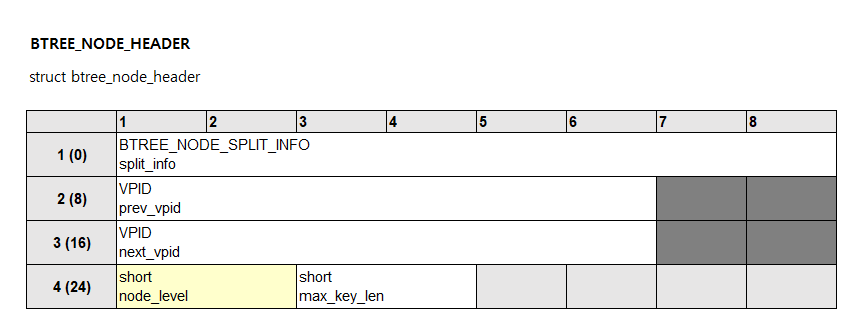
페이지의 0번 슬롯이 루트 헤더 또는 노드 헤더를 가리키고 있습니다. 루트 노드와 브랜치 노드의 레코드는 다음 계층 노드의 VPID를 저장하고 있고, VPID는 페이지에 접근할 수 있는 주소입니다. VPID는 볼륨 아이디, 페이지 아이디로 구성되어 있습니다. 리프 노드의 레코드는 테이블 레코드들의 OID를 저장하고 있고, OID는 레코드에 접근할 수 있는 주소입니다. OID는 볼륨 아이디, 페이지 아이디, 슬롯 아이디로 구성되어 있습니다.
오버플로 노드 (BTREE_OVERFLOW_NODE)
리프 노드에 동일한 키가 여러 번 입력되면 해당 키는 한 번만 저장하고 테이블 레코드들의 OID를 모아서 저장합니다. 이러한 구조는 같은 키를 가지는 테이블 레코드들을 빠르게 찾을 수 있도록 하는 장점이 있습니다. 그러나 OID 목록에서 특정 OID를 찾는 것은 어려울 수 있습니다. OID 목록의 크기는 페이지 크기의 1/8을 초과할 수 없으며, 페이지 크기의 1/8을 초과하는 OID들은 오버플로 노드에 저장됩니다.
|
1
2
3
|
/* src/storage/btree_load.h */
#define BTREE_MAX_OIDLEN_INPAGE ((int) (DB_PAGESIZE / 8))
|
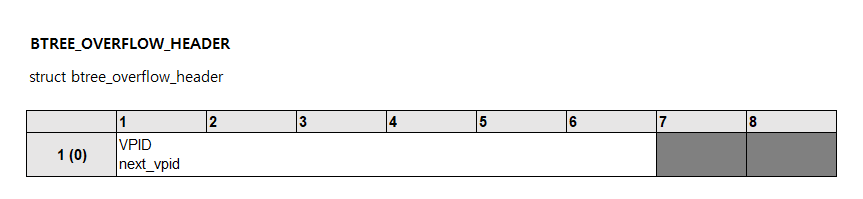
오버플로 노드에는 2개의 슬롯만 존재합니다. 0번 슬롯은 오버플로 헤더를 가리키고 있으며, 1번 슬롯은 OID 목록을 가리키고 있습니다. 하나의 오버플로 노드에 OID 목록을 모두 저장할 수 없는 경우에는 오버플로 헤더가 다음 오버플로 노드의 VPID를 저장하고 있습니다.
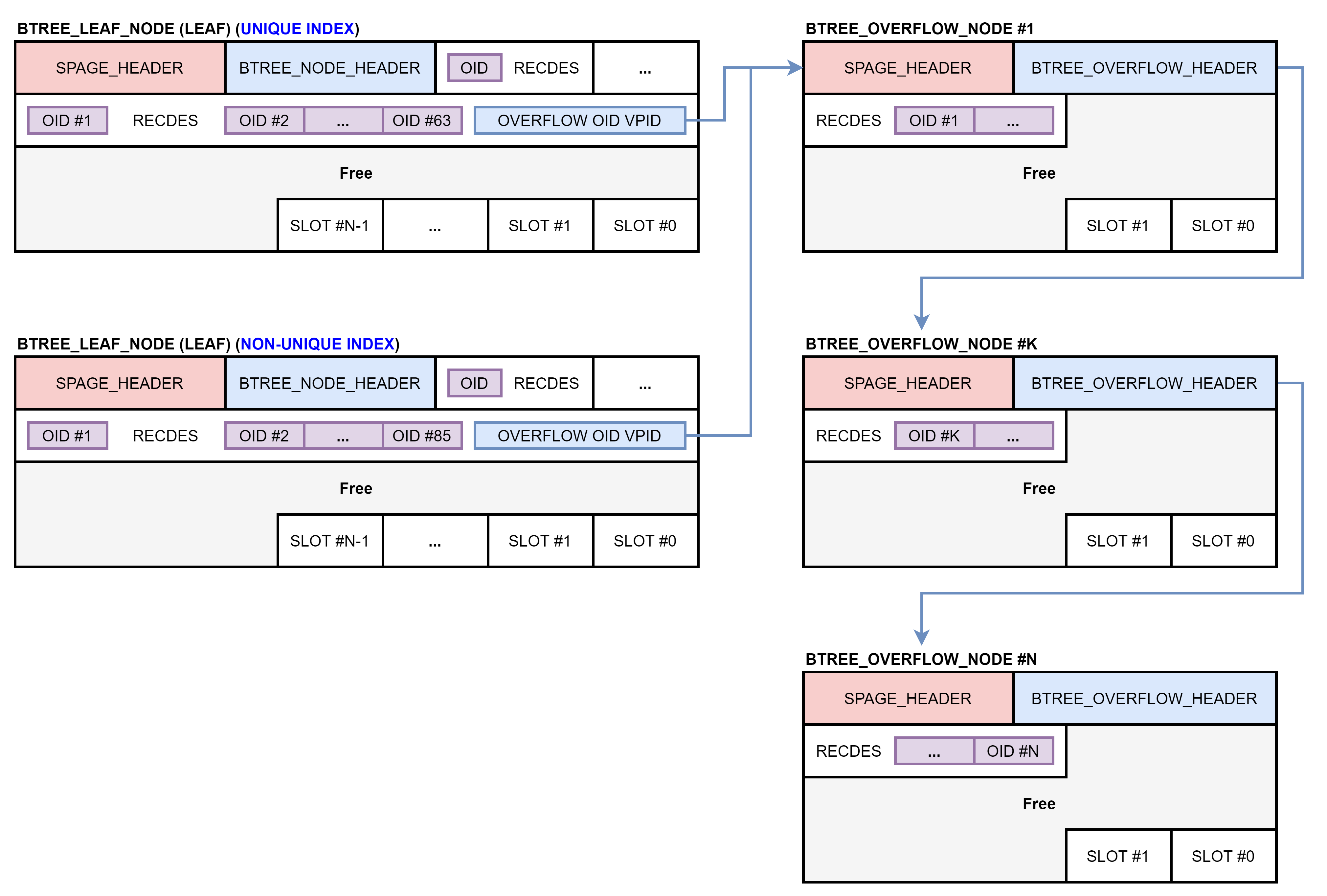
리프 노드의 레코드가 오버플로 노드에 OID 목록을 저장하고 있는 경우에는 첫 번째 OID의 슬롯 아이디에 BTREE_LEAF_RECORD_OVERFLOW_OIDS 플래그를 설정하며, 레코드 마지막에는 첫 번째 오버플로 노드의 VPID가 저장되어 있습니다.
|
1
2
3
4
5
6
7
8
9
10
|
/* src/storage/btree.c */
if (btree_leaf_is_flaged (rec, BTREE_LEAF_RECORD_OVERFLOW_OIDS))
{
btree_leaf_get_vpid_for_overflow_oids (rec, &leaf_rec->ovfl);
}
else
{
VPID_SET_NULL (&leaf_rec->ovfl);
}
|
PAGE_OVERFLOW 페이지
사용자가 입력하는 키의 크기가 너무 커서 하나의 페이지에 저장할 수 없는 경우가 있습니다. 리프 노드에 저장할 수 있는 키의 크기는 페이지 크기의 1/8을 초과할 수 없습니다. 페이지 크기의 1/8을 초과하는 키는 리프 노드에 저장되지 않고, 하나 이상의 PAGE_OVERFLOW 페이지에 나누어 저장됩니다.
|
1
2
3
|
/* src/storage/btree_load.h */
#define BTREE_MAX_KEYLEN_INPAGE ((int) (DB_PAGESIZE / 8))
|
PAGE_OVERFLOW 페이지는 페이지 타입이 PAGE_OVERFLOW인 페이지입니다. 이 페이지는 페이지 헤더가 없으며, 슬롯 페이지 구조도 아닙니다. 첫 번째 PAGE_OVERFLOW 페이지는 OVERFLOW_FIRST_PART를 저장하고 있고, 두 번째 PAGE_OVERFLOW 페이지부터는 OVERFLOW_REST_PART를 저장하고 있습니다. 전체 키의 길이는 OVERFLOW_FIRST_PART에만 저장되어 있습니다.
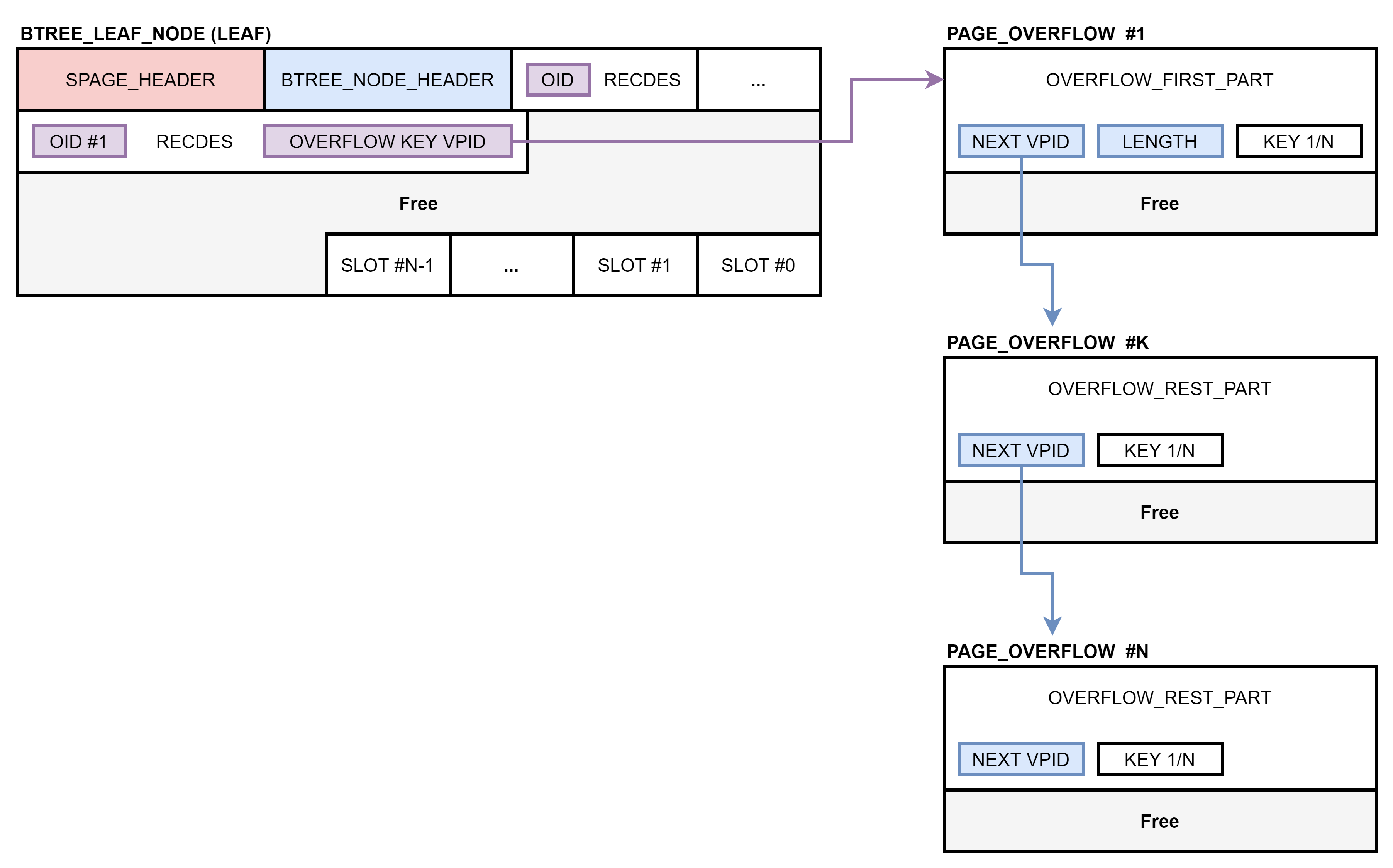
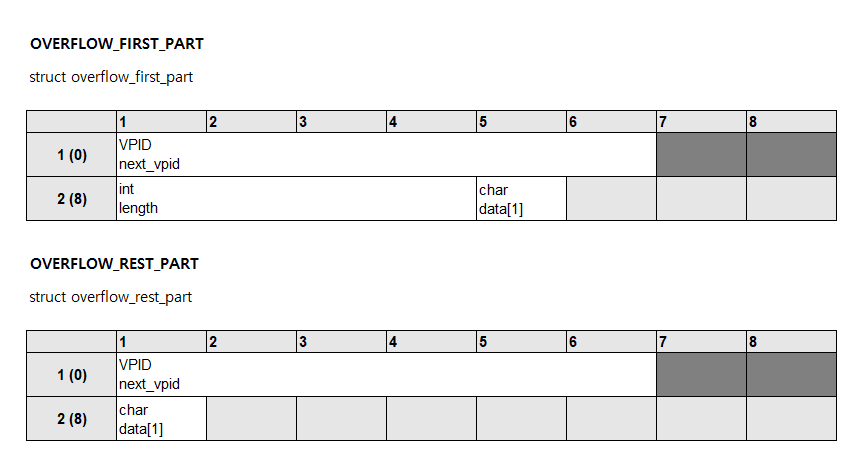
리프 노드의 레코드가 PAGE_OVERFLOW 페이지에 키를 저장하고 있는 경우에는 첫 번째 OID의 슬롯 아이디에 BTREE_LEAF_RECORD_OVERFLOW_KEY 플래그를 설정하며, 레코드 마지막에는 첫 번째 PAGE_OVERFLOW 페이지의 VPID가 저장되어 있습니다.
|
1
2
3
4
5
6
|
/* src/storage/btree.c */
if (btree_leaf_is_flaged (rec, BTREE_LEAF_RECORD_OVERFLOW_KEY))
{
key_type = BTREE_OVERFLOW_KEY;
}
|
PAGE_OVERFLOW 페이지는 인덱스 페이지가 아니라 데이터 페이지입니다. PAGE_BTREE 페이지는 인덱스 페이지로 개수를 세고 있지만, PAGE_OVERFLOW 페이지는 데이터 페이지로 개수를 세고 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
/* src/storage/page_buffer.c - pgbuf_scan_bcb_table () */
switch (page_type)
{
case PAGE_BTREE:
show_status_snapshot->num_index_pages++;
break;
case PAGE_OVERFLOW:
case PAGE_HEAP:
show_status_snapshot->num_data_pages++;
break;
...
}
|
노드 분할
노드 분할이 발생하는 경우
새로운 키를 저장하기 위한 공간이 부족하거나 기존 레코드의 크기가 증가하는 경우에는 노드 분할이 발생할 수 있습니다. 이를 좀 더 자세히 살펴보면 다음과 같은 경우가 있습니다:
1. 새로운 키가 입력되는 경우
2. 기존 키의 크기가 증가하는 경우
3. 기존 레코드에 테이블 레코드의 OID가 추가되는 경우
4. 기존 레코드에 MVCC 아이디가 추가되는 경우
1. 새로운 키가 입력되는 경우
새로운 키의 입력은 충분한 여유 공간을 필요로 합니다. 해당 페이지에 여유 공간이 부족하면 노드 분할이 발생할 수 있습니다. 노드 분할이 발생하기 전까지 1978개의 키를 입력했습니다. 이 상태에서 새로운 키를 입력하면 노드 분할이 발생한 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
drop table if exists t1;
create table t1 (c1 int, index i1 (c1));
insert into t1 with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 1978
)
select n from cte;
/* csql> ;line-output on */
show index capacity of t1.i1;
insert into t1 values (1979);
/* csql> ;line-output on */
show index capacity of t1.i1;
/*
<00001> Table_name : 'dba.t1'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 1983 (1980 -> 1983)
Total_value : 1983 (1980 -> 1983)
...
Num_leaf_page : 3 (2 -> 3)
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 4 (3 -> 4)
Height : 2
...
*/
|
2. 기존 키의 크기가 증가하는 경우
기존 키의 크기가 증가하면 레코드의 크기도 증가하게 됩니다. 해당 페이지에 여유 공간이 부족하면 노드 분할이 발생할 수 있습니다. 가변 길이 문자열 타입(VARCHAR)에서는 기존 키의 크기를 변경할 수 있습니다. 노드 분할이 발생하기 전까지 1581개의 키를 입력했습니. 이 상태에서 기존에 입력했던 키의 크기를 크게 변경하면 노드 분할이 발생한 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
drop table if exists t1;
create table t1 (c1 varchar, index i1 (c1));
insert into t1 with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 1581
)
select lpad (n, 4, '0') from cte;
/* csql> ;line-output on */
show index capacity of t1.i1;
update t1 set c1 = lpad (c1, 20 /* 4 -> 20 */, '9') where c1 = 1581;
/* csql> ;line-output on */
show index capacity of t1.i1;
/*
<00001> Table_name : 'dba.t1'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 1585 (1583 -> 1585)
Total_value : 1585 (1583 -> 1585)
...
Num_leaf_page : 3 (2 -> 3)
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 4 (3 -> 4)
Height : 2
...
*/
|
3. 기존 레코드에 테이블 레코드의 OID가 추가되는 경우
같은 키가 입력되면 중복된 키를 저장하지 않고, 기존 키 뒤에 테이블 레코드의 OID를 추가합니다. 추가된 OID의 크기만큼 레코드의 크기도 증가하게 됩니다. 해당 페이지에 여유 공간이 부족하면 노드 분할이 발생할 수 있습니다. 노드 분할이 발생하기 전까지 1977개의 키를 입력했습니다. 이 상태에서 기존에 입력했던 키와 같은 키를 몇 번 더 입력하면 노드 분할이 발생한 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
drop table if exists t1;
create table t1 (c1 int, index i1 (c1));
insert into t1 with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 1977
)
select n from cte;
select count (*) from t1 where c1 = 1977;
/* <00001> count(*): 1 */
/* csql> ;line-output on */
show index capacity of t1.i1;
insert into t1 values (1977);
insert into t1 values (1977);
insert into t1 values (1977);
select count (*) from t1 where c1 = 1977;
/* <00001> count(*): 4 */
/* csql> ;line-output on */
show index capacity of t1.i1;
/*
<00001> Table_name : 'dba.t1'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 1981 (1979 -> 1981)
Total_value : 1984 (1979 -> 1984)
...
Num_leaf_page : 3 (2 -> 3)
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 4 (3 -> 4)
Height : 2
...
*/
|
4. 기존 레코드에 MVCC 아이디가 추가되는 경우
레코드를 변경할 때 MVCC 아이디가 추가되도록 하려면 클라이언트/서버 모드에서 AUTO COMMIT을 비활성화하고 질의를 실행해야 합니다. 이 상태에서 질의를 실행하면 트랜잭션을 시작합니다. 트랜잭션 중에는 키를 삭제해도 물리적으로 삭제하지 않고, DELETE MVCC 아이디를 추가합니다. 추가되는 DELETE MVCC 아이디의 크기만큼 레코드의 크기도 증가하게 됩니다. 해당 페이지에 여유 공간이 부족하면 노드 분할이 발생할 수 있습니다. 노드 분할이 발생하기 전까지 1318개의 키를 입력했습니다. 이 상태에서 AUTO COMMIT을 비활성화하고 몇 개의 기존 키를 삭제하면 노드 분할이 발생한 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
/**
* client-server mode
* $ cubrid server start <db_name>
* $ csql -u dba <db_name>
*/
drop table if exists t1;
create table t1 (c1 int, index i1 (c1));
insert into t1 with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 1318
)
select n from cte;
/* csql> ;line-output on */
show index capacity of t1.i1;
/* csql> ;autocommit off */
delete from t1 where c1 = 1318;
delete from t1 where c1 = 1317;
delete from t1 where c1 = 1316;
delete from t1 where c1 = 1315;
delete from t1 where c1 = 1314;
delete from t1 where c1 = 1313;
/* csql> ;line-output on */
show index capacity of t1.i1;
/*
<00001> Table_name : 'dba.t1'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 1322 (1320 -> 1322)
Total_value : 1322 (1320 -> 1322)
...
Num_leaf_page : 3 (2 -> 3)
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 4 (3 -> 4)
Height : 2
...
*/
|
사용자가 키를 입력하는 패턴에 따라 달라지는 노드 분할 #1
B+ 트리의 키가 항상 정렬되어 있기 때문에 사용자가 어떤 패턴으로 키를 입력하더라도 B+ 트리의 상태는 항상 동일하다고 착각할 수 있습니다. University of San Francisco의 B+ Tree Visualization을 사용하여 아래 2개의 시나리오 결과를 비교해 보았습니다.
1. 시나리오 #1 - 1부터 27까지 오름차순으로 증가하는 패턴으로 키를 입력하는 경우
2. 시나리오 #2 - 1부터 27까지 불규칙 패턴으로 키를 입력하는 경우
Max. Degree는 7로 설정했습니다. 페이지에 7번째 키가 입력될 때 노드의 레코드가 반으로 분할됩니다.
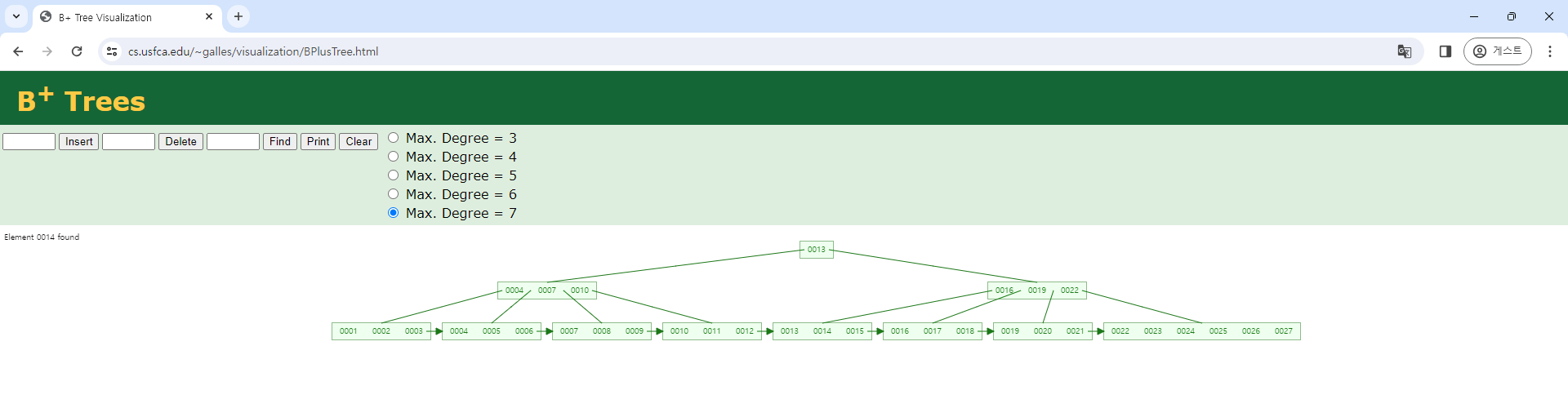
시나리오 #1 - 1부터 27까지 오름차순으로 증가하는 패턴으로 키를 입력하는 경우
1→2→3→4→5→6→7→8→9→10→11→12→13→14→15→16→17→18→19→20→21→22→23→24→25→26→27 순서로 키를 입력했습니다.
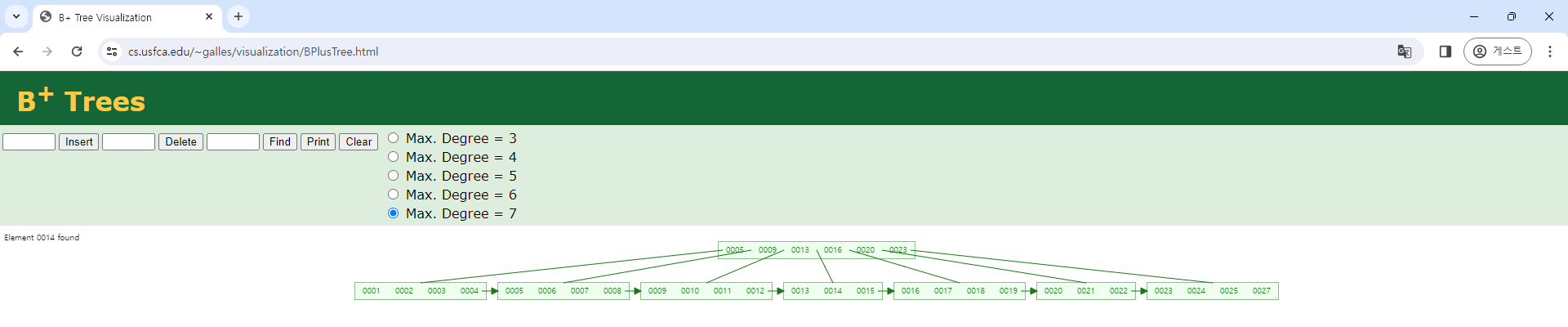
시나리오 #2 - 1부터 27까지 불규칙 패턴으로 키를 입력하는 경우
14→13→26→12→24→11→22→10→20→9→18→27→8→16→7→21→6→5→15→25→4→3→2→1→17→19→23 순서로 키를 입력했습니다.
비교 결과
B+ 트리의 높이가 시나리오 #1은 3이고, 시나리오 #2는 2입니다. B+ 트리의 높이가 높아지면 키를 탐색할 때 더 많은 노드에 접근해야 하므로 성능 저하가 발생 수 있습니다. 사용하는 페이지 수도 시나리오 #1은 11개이고, 시나리오 #2는 8개입니다. 시나리오 #1에서는 가장 오른쪽 리프 노드를 제외하고는 키를 4개 이상 저장하고 있는 리프 노드가 없습니다. 오름차순으로 증가하는 패턴으로 키를 입력하기 때문에 새로운 키는 가장 오른쪽 리프 노드에만 입력되고, 나머지 리프 노드에서는 저장 공간이 낭비됩니다. 시나리오 #1과 시나리오 #2는 키를 입력하는 패턴만 다르고, 나머지는 동일합니다. 사용자가 불규칙 패턴으로 키를 입력할 때는 성능 저하와 저장 공간의 낭비가 발생하지 않았습니다. 그러나 사용자가 항상 같은 패턴으로 키를 입력하는 것을 기대하는 것은 불가능합니다. 사용자는 서비스하고 있는 데이터의 성격에 따라 오름차순, 내림차순 또는 불규칙한 패턴으로 키를 삽입합니다.
똑똑하게 노드 분할하기
B+ 트리에서는 키가 정렬된 위치에 입력되기 때문에 키가 입력되는 슬롯 아이디의 변화를 통계적으로 분석하면 사용자가 키를 입력하는 패턴을 파악할 수 있습니다. 예를 들어, 오름차순 인덱스라고 가정할 때, 리프 노드의 가장 마지막 슬롯에 새로운 키가 입력되면 오름차순으로 증가하는 패턴으로 키가 입력되고 있다고 예측할 수 있습니다. 반대로 리프 노드의 노드 헤더 바로 다음 슬롯에 새로운 키가 입력되면 내림차순으로 감소하는 패턴으로 키가 입력되고 있다고 것으로 예측할 수 있습니다.
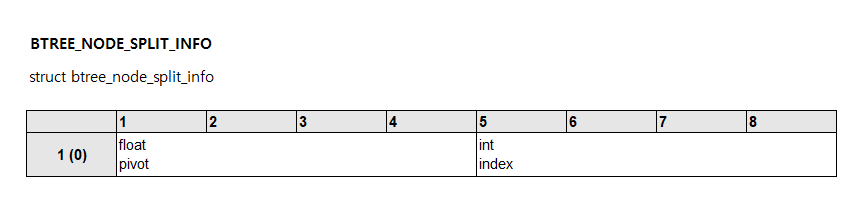
노드 헤더는 노드 분할 정보(BTREE_NODE_SPLIT_INFO)를 포함하고 있습니다. 이 정보는 페이지에 입력되는 슬롯 아이디에 대한 누적 이동 평균(pivot)을 계산해서 저장합니다. 새로운 키가 입력될 때마다 btree_split_next_pivot 함수에서 새로운 누적 이동 평균을 계산하고, 노드 분할이 필요한 경우에는 btree_find_split_point 함수에서 현재의 누적 이동 평균을 확인해서 노드의 레코드를 분할합니다.
|
1
2
3
4
5
6
|
#0 btree_split_next_pivot (...) at src/storage/btree.c:12603
#1 0x00007ff421cd3e96 in btree_key_insert_new_key (...) at src/storage/btree.c:27717
#2 0x00007ff421cd335e in btree_key_insert_new_object (...) at src/storage/btree.c:27484
#3 0x00007ff421cc7d9c in btree_search_key_and_apply_functions (...) at src/storage/btree.c:22802
#4 0x00007ff421ccfb63 in btree_insert_internal (...) at src/storage/btree.c:26345
#5 0x00007ff421ccf635 in btree_insert (...) at src/storage/btree.c:26199
|
누적 이동 평균은 다음과 같은 수식으로 계산됩니다. 여기서 CAi는 i+1번째 키가 입력되기 전에 노드 분할 정보에 저장된 누적 이동 평균을 나타냅니다. 또한, Xi+1은 i+1번째 키에 대한 이동 평균을 나타냅니다. 이는 i+1번째 키가 입력된 슬롯 아이디를 i+1번째 키가 입력된 후의 전체 키 개수로 나누어 계산됩니다.

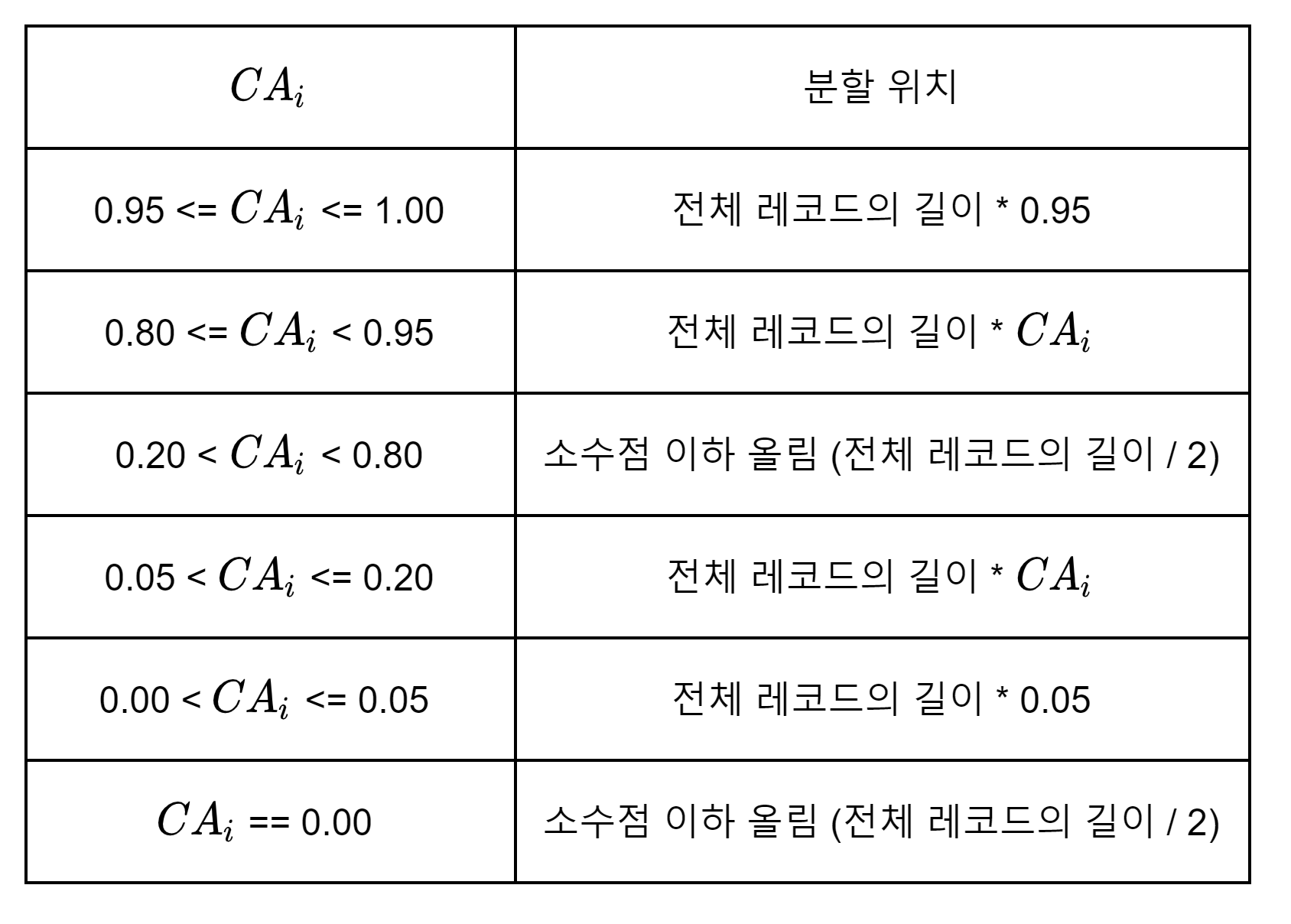
노드 분할이 발생할 때 레코드를 분할할 위치는 btree_split_find_pivot 함수에서 결정됩니다. 이 함수는 누적 이동 평균을 직접적으로 반영하지 않습니다. 누적 이동 평균이 0.2f(BTREE_SPLIT_LOWER_BOUND)와 0.8f(BTREE_SPLIT_UPPER_BOUND) 사이에 있는 경우에는 레코드를 반으로 분할하고, 벗어나는 경우에만 누적 이동 평균을 직접적으로 반영하여 레코드를 분할할 위치를 결정합니다. 만약 누적 이동 평균이 0.05f(BTREE_SPLIT_MIN_PIVOT)보다 작으면 0.05f를 사용하고, 0.95f(BTREE_SPLIT_MAX_PIVOT)보다 크면 0.95f를 사용하여 레코드를 분할할 위치를 결정합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#0 btree_split_find_pivot (...) at src/storage/btree.c:12575
#1 0x00007ff421cafaee in btree_find_split_point (...) at src/storage/btree.c:12289
#2 0x00007ff421cb3cbd in btree_split_root (...) at src/storage/btree.c:13889
#3 0x00007ff421cd1934 in btree_split_node_and_advance (...) at src/storage/btree.c:27003
#4 0x00007ff421cc7b93 in btree_search_key_and_apply_functions (...) at src/storage/btree.c:22753
#5 0x00007ff421ccfb63 in btree_insert_internal (...) at src/storage/btree.c:26345
#6 0x00007ff421ccf635 in btree_insert (...) at src/storage/btree.c:26199
#0 btree_split_find_pivot (...) at src/storage/btree.c:12575
#1 0x00007ff421cafaee in btree_find_split_point (...) at src/storage/btree.c:12289
#2 0x00007ff421cb1a1e in btree_split_node (...) at src/storage/btree.c:13051
#3 0x00007ff421cd28f9 in btree_split_node_and_advance (...) at src/storage/btree.c:27290
#4 0x00007ff421cc7b93 in btree_search_key_and_apply_functions (...) at src/storage/btree.c:22753
#5 0x00007ff421ccfb63 in btree_insert_internal (...) at src/storage/btree.c:26345
#6 0x00007ff421ccf635 in btree_insert (...) at src/storage/btree.c:26199
|
사용자가 키를 입력하는 패턴에 따라 달라지는 노드 분할 #2
1. 오름차순으로 증가하는 패턴으로 키를 입력하는 경우
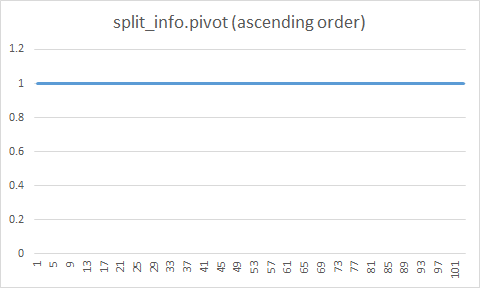
새로운 키는 항상 페이지의 마지막 슬롯에 입력되기 때문에 노드 분할 정보에서 누적 이동 평균은 0.95f(BTREE_SPLIT_MAX_PIVOT)보다 큰 값을 유지합니다. 따라서 노드 분할이 발생할 때 누적 이동 평균이 0.95f보다 크기 때문에 분할되는 왼쪽 페이지에는 전체 레코드 길이의 95%가 이동하고, 오른쪽 페이지에는 나머지 5%가 이동합니다. SHOW INDEX CAPACITY에서 Total_free_space_non_ovf를 보면 공간 낭비가 없는 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
set system parameters 'cte_max_recursions=100000';
drop table if exists t_asc;
create table t_asc (c1 int, index i1 (c1));
insert into t_asc with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 100000
)
select n from cte;
/* csql> ;line-output on */
show index capacity of t_asc.i1;
/*
<00001> Table_name : 'dba.t_asc'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 100206
Total_value : 100206
...
Num_leaf_page : 104
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 105
Height : 2
...
Total_space : '1.6M'
Total_used_space_non_ovf : '1.5M'
Total_free_space_non_ovf : '101.9K'
...
*/
|
2. 내림차순으로 감소하는 패턴으로 키를 입력하는 경우
새로운 키는 항상 페이지의 1번 슬롯에 입력되기 때문에 노드 분할 정보에서 누적 이동 평균은 0.05f(BTREE_SPLIT_MIN_PIVOT)보다 작은 값을 유지합니다. 노드 분할이 발생할 때 누적 이동 평균이 0.05f보다 작기 때문에 분할되는 왼쪽 페이지에는 전체 레코드 길이의 5%가 이동하고, 오른쪽 페이지에는 나머지 95%가 이동합니다. SHOW INDEX CAPACITY에서 Total_free_space_non_ovf를 보면 공간 낭비가 없는 것을 확인할 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
set system parameters 'cte_max_recursions=100000';
drop table if exists t_desc;
create table t_desc (c1 int, index i1 (c1));
insert into t_desc with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 100000
)
select n from cte order by n desc;
/* csql> ;line-output on */
show index capacity of t_desc.i1;
/*
<00001> Table_name : 'dba.t_desc'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 100206
Total_value : 100206
...
Num_leaf_page : 104
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 105
Height : 2
...
Total_space : '1.6M'
Total_used_space_non_ovf : '1.5M'
Total_free_space_non_ovf : '101.9K'
...
*/
|

3. 불규칙 패턴으로 키를 입력하는 경우
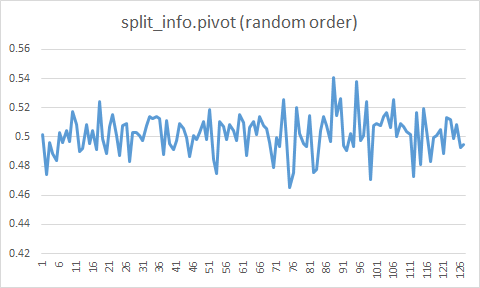
키가 입력될 때마다 키가 입력되는 슬롯 아이디에 대한 누적 이동 평균이 갱신됩니다. 그래프를 보면 0.5f에서 크게 벗어나지 않고 있습니다. 노드 분할이 발생할 때 누적 이동 평균이 0.2f(BTREE_SPLIT_LOWER_BOUND)와 0.8f(BTREE_SPLIT_UPPER_BOUND) 사이에 있기 때문에 분할되는 왼쪽 페이지와 오른쪽 페이지에 각각 전체 레코드 길이의 50%를 이동합니다. SHOW INDEX CAPACITY 결과를 확인하면 오름차순 및 내림차순 패턴과 비교했을 때 Total_free_space_non_ovf가 큰 편입니다. 하지만 불규칙 패턴에서는 분할되는 왼쪽과 오른쪽 페이지 양쪽에 새로운 키가 입력될 가능성이 있으므로, 잦은 노드 분할을 방지하기 위해 적당한 여유 공간을 유지하는 것이 좋습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
set system parameters 'cte_max_recursions=100000';
drop table if exists t_random;
create table t_random (c1 int, index i1 (c1));
insert into t_random with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 100000
)
select n from cte order by random ();
/* csql> ;line-output on */
show index capacity of t_random.i1;
/*
<00001> Table_name : 'dba.t_random'
Index_name : 'i1'
Btid : '(0|4160|4161)'
Num_distinct_key : 100254
Total_value : 100254
...
Num_leaf_page : 128
Num_non_leaf_page : 1
Num_ovf_page : 0
Num_total_page : 129
Height : 2
...
Total_space : '2.0M'
Total_used_space_non_ovf : '1.5M'
Total_free_space_non_ovf : '482.4K'
...
*/
|
루트 노드 → 브랜치 노드 → 리프 노드 순서의 노드 분할
노드 분할은 루트 노드 → 브랜치 노드 → 리프 노드 순서로 발생합니다. 키는 리프 노드에 입력되기 때문에 처음에는 리프 노드에서 노드 분할이 발생할 것으로 생각할 수 있습니다. 그러나 실제로는 루트 노드부터 시작하여 새로운 키를 입력할 수 있는 여유 공간이 있는지 확인합니다. 루트 노드에 공간이 부족하다면 키가 입력되지 전에 루트 노드에서부터 노드 분할이 발생합니다. 나중에 리프 노드에서 분할이 발생했을 때 분할된 페이지를 구분하기 위한 분할 키를 루트 노드와 브랜치 노드에 저장해야 하기 때문에 미리 여유 공간이 확보하는 것입니다.
아래는 B+ 트리의 높이가 1에서 2가로 증가하는 과정입니다. B+ 트리의 높이 1일 때는 리프 노드가 1개만 존재합니다. 리프 노드에 새로운 키를 저장할 수 있는 공간이 부족할 때 노드 분할이 발생합니다. 루트 노드의 분할은 새로운 키가 입력되기 전에 발생하며, 노드 분할이 완료된 후에 정렬된 위치에 새로운 키가 입력됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
drop table if exists t1;
create table t1 (c1 int auto_increment, index i1 (c1));
insert into t1 with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < 1012
)
select null from cte;
insert into t1 values (null); /* 1013 */
|
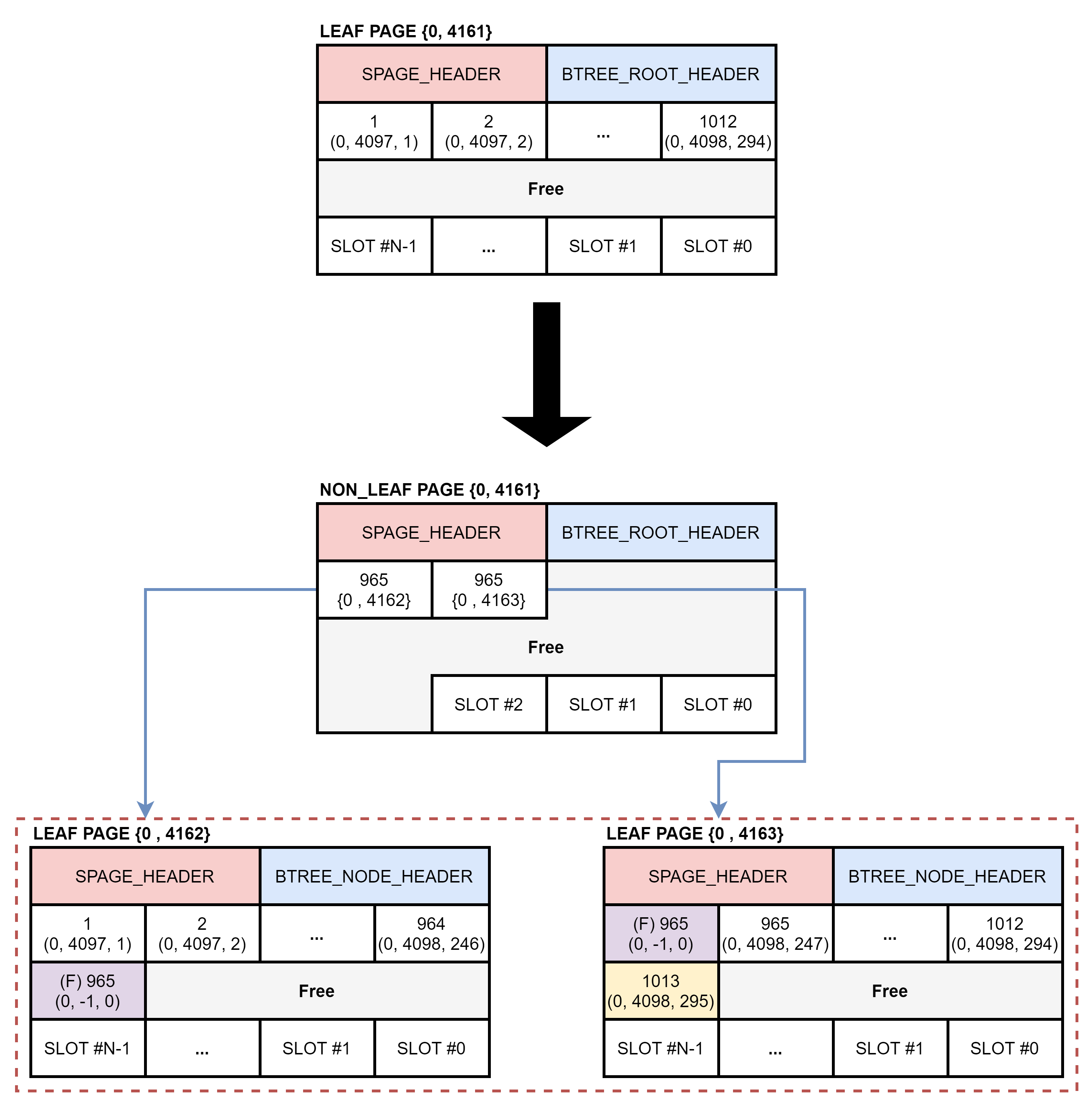
아래는 B+ 트리의 높이가 2에서 3으로 증가하는 과정입니다. 리프 노드에 새로운 키를 저장할 공간이 부족해서 노드 분할이 발생한 것이 아니라 루트 노드에 여유 공간이 부족해서 노드 분할이 발생했습니다. 루트 노드의 노드 분할이 완료된 후에는 정렬된 위치의 리프 노드에 새로운 키가 입력된 것을 확인할 수 있습니다. 이 때 리프 노드의 공간은 충분하기 때문에 노드 분할이 발생하지 않았습니다. 루트 노드가 분할하면서 B+ 트리의 높이가 2에서 3으로 증가할 때 새로운 브랜치 노드 2개가 추가됩니다. 루트 노드와 리프 노드의 VPID는 변경되지 않고, 새로운 브랜치 노드에 리프 노드의 레코드를 이동합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
/**
* standalone mode
* $ csql -u dba <db_name> -S
*/
set system parameters 'cte_max_recursions=1000000';
insert into t1 with recursive cte (n) as (
select 1
union all
select n + 1 from cte where n < (976629 - 1013)
)
select null from cte;
insert into t1 values (null); /* 976630 */
|
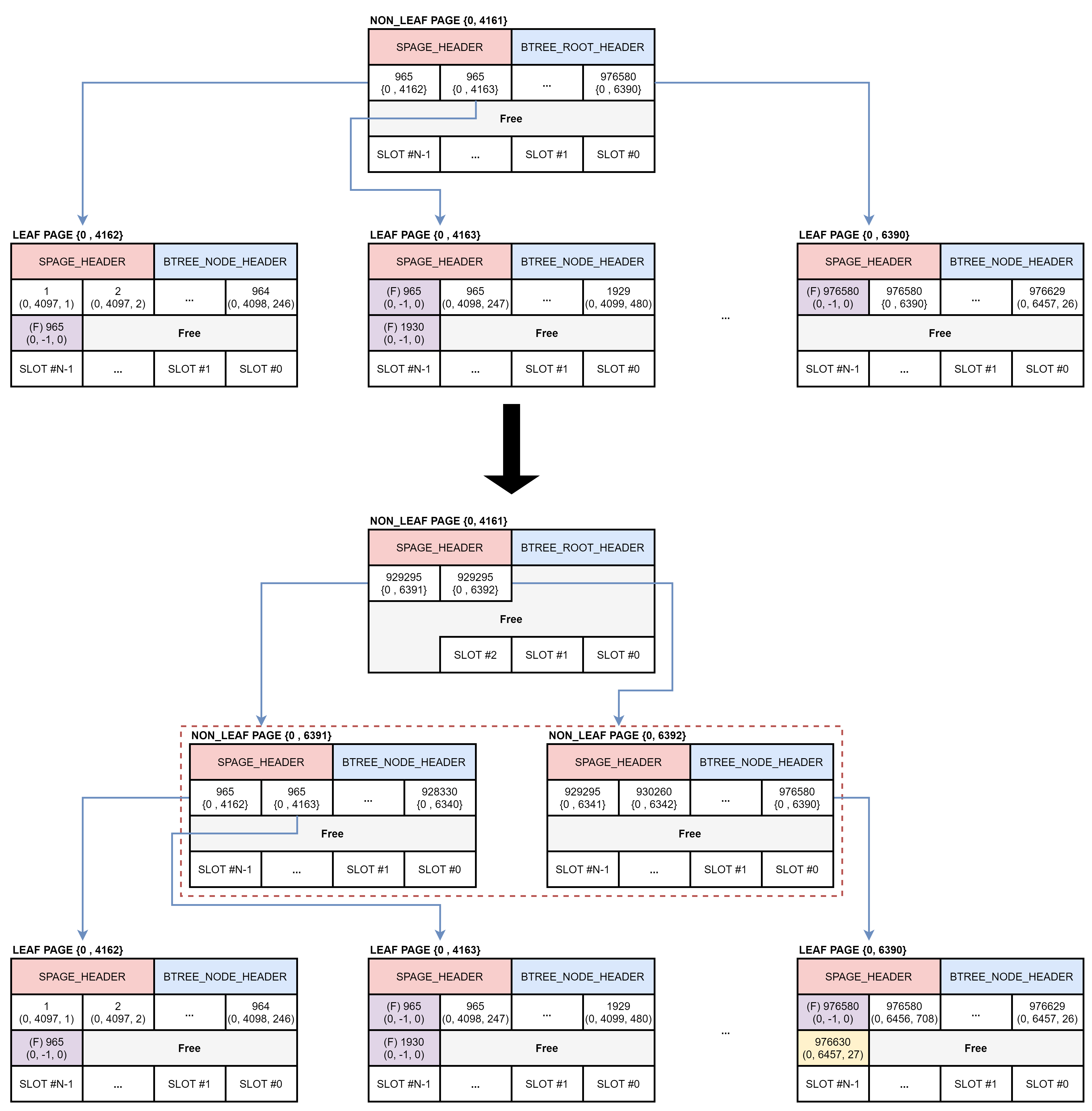
참고
1. [CUBRID Blog] CUBRID 슬랏 페이지(slotted page) 구조 살펴보기
2. [NAVER D2] CUBRID Internals - 키와 인덱스의 관계
3. [University of San Francisco] B+ Tree Visualization
4. [Wikimedia] Moving average - Cumulative average