Charpter0. 들어가며..
주요한 시스템인 경우, 장애가 발생하더라도 실시간으로 서비스를 제공해야 함으로 CUBRID이중화 방식은 필히 적용해야 할 구성방식입니다.
그러나 LOB 를 사용하지 못하는 제약사항이 있어 이를 극복할 수 있는 방법이 있지 않을까해서 테스트한 내용입니다.
본 장에서는 Linux에서, fail-over, fail-back상황에서 테스트했지만,
더 많은 OS, 더 많은 상황에서도 동기화가 되는지 종합적인 테스트가 이루어져야 할 것입니다.
Chapter1. HA란 무엇인가
CUBRID에서는 HA기능을 기본적으로 제공하고 있다.
HA란 무엇인가??
운영중인 하나의 서버(master-node)에 이상이 발생하여도 대기중 이였던 서버(slave-node)를 활용하여 중단없는 서비스를 제공한다는 것이다.
어떠한 방식으로 동기화를 유지하고 있을까?
해답은 아래 매뉴얼에서 확인 할 수 있다.
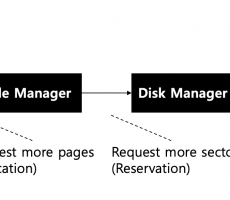
CUBRID의 HA 기능은 shared-nothing 구조이며, 액티브 서버(active server)에서 스탠바이 서버(standby server)로 데이터를 동기화하기 위해 다음 두 단계를 수행한다.
즉, 상대방 서버를 모니터링하고 있다가 트랜잭션(commit/rollback)이 발생하면, 해당 로그를 복사하여 가져와서 본 서버에 적용하는 방식인 것으 알 수 있다.
LOB(CLOB/BLOB)타입 |
CUBRID HA에서 LOB 칼럼 메타 데이터(Locator)는 복제되고, LOB 데이터는 복제되지 않는다. 따라서 LOB 타입 저장소가 로컬에 위치할 경우, 슬레이브 노드 또는 failover 이후 마스터 노드에서 해당 칼럼에 대한 작업을 허용하지 않는다. |

아래 그림은 master-node에서 BLOB생성 후 조회한 결과이다.
|
아래 그림은 slave-node에서 조회한 결과이다. 결과를 보면 bstr의 메타데이터(Locator)는 존재하지만, LOB데이터가 존재하지 않아 에러가 발생한 상황이다.
|


CUBRID-HA라는 좋은 기능을 사용하면서, LOB(CLOB/BLOB)를 사용할 수 있는 방법이 있지 않을까?
LOB의 메타 데이터 저장소를 동기화한다면, CUBRID-HA에서도 LOB를 사용할 수 있지 않을까?
동기화를 수행하기 위한 방법은 여러가지가 존재한다.
Transmit을 통한 FTP Sync
총평: 동기화와 거리가 멀다. 3.00

이런 점이 좋았어요! 직관적이며 쉽다.
이런 점이 아쉬웠어요! 속도가 느리며, 전송날짜로 파일이 생성되어 관리하기 어렵다.
- Subversion
총평: 프로젝트성 자료 공간으로 활용하기 좋다. 3.00

이런 점이 좋았어요! 문서,파일에 대한 형상 관리가 가능하다.
이런 점이 아쉬웠어요! 형상관리를 위해 불필요한 저장공간이 필요하다.
- Rsync
총평 : 백업이나 n대의 서버로 배포(백업)시 유리 5.00

이런 점이 좋았어요! 빠르고 간편하다. 무료다.
이런 점이 아쉬웠어요! 단뱡향이다.
- unison
총평 : 양방향 동기화로 적절하다. 9.00

이런 점이 좋았어요! 양방향 sync가 가능하며, 무료이다.
지원OS : Mac, Linux, Unix, Windows간의 양방향 Sync가 가능하다.
이런 점이 아쉬웠어요! Windows 상에서는 파일명에 한글이 있을시 깨진다.
(Unix/Mac/Linux간에는 문제 없음)
Chapter2. Unison설치
1. homepage : http://unison-binaries.inria.fr/
해당 페이지에 들어가면 compile된 binaryfile이 존재한다.
- 2.40.61 32 bits (2011.01.28, stable, 32 bits),
- 2.40.61 64 bits (2011.01.28, stable, 64 bits).
이 중 64bit용으로 다운로드 받는다.
2. root
root 계정으로 수행한다. 기타계정에서는 에러가 발생한다.
(타 계정으로 설치 후 수행되는지 추가 테스트가 필요하다.)
3. 다운로드
wget http://unison-binaries.inria.fr/files/2011.01.28-Esup-unison-2.40.61-linux-x86_64-text-static.tar.gz
4. 압축풀기
tar xvfz 2011.01.28-Esup-unison-2.40.61-linux-x86_64-text-static.tar.gz
5. 파일명 변경
압축을 풀면 "unison-2.40.61-linux-x86_64-text-static" 파일이 생성되는데, 너무 길어서 unison이라고 변경한다.
mv unison-2.40.61-linux-x86_64-text-static unsion
6. /bin으로 copy
path에 등록해도 되지만, /bin에 복사하여 사용하였다. 본인이 편한 방법을 사용하면 된다.
cp ./unison /bin
7. 실행
정상적으로 완료 되었다면, 아래와 같이 usage화면이 출력될 것이다.

Chapter3. 테스트..테스트
CUBRID-HA제약사항이 무엇인지... 왜 LOB를 사용하지 못하는지 파악해 보았고, unsion 설치도 완료하였다.
해당 장에서는 CUBRID-HA환경에서 LOB컬럼을 생성하고, 동기화를 수행하는 테스트를 진행
- OS : CentOS 6.5
- CUBRID Version : CUBRID 9.3.9.0002
- 이중화 구성(CUBRID-HA)
db1과 db2를 master/slave-node를 기본구성하였다.
- LOB컬럼을 생성하고 각각의 node에서 조회한다.
<<Test Data>>
CLOB컬럼을 조회한 결과, 에러가 발생한다.(왼쪽그림은 master-node,오른쪽그림은 slave-node이다.)

BLOB컬럼을 조회한 결과, 에러가 발생한다.(왼쪽그림은 master-node,오른쪽그림은 slave-node이다.)
위와 같은 결과가 출력되는 이유는 lob데이터가 slave-node에 복제되지 않기 때문이다.

그럼 이제 unison을 사용하여 양방향 동기화를 맞추어보자.
unison 동기화를 수행한다.
명령어 : root> unison /home/cubrid/DB/lob ssh://cubrid@192.168.83.134//home/cubrid/DB/lob
unison동기화 후에 LOB데이터가 있는 디렉토리를 조회해 보면, slave-node에도 동일하게 LOB데이터가 존재하는 것을 확인할 수 있다.
이제 slave-node에서 LOB데이터가 검색되는지를 확인해보자

fail-over수행 후에 데이터를 입력하고 동기화가 되는지 확인하자.
7-1. fail-over를 위해 db1의 서버를 정지한다.
7-2. db2(slave-node)에서 데이터를 입력한다.
7-3. unison동기화수행 후 db1에서 데이터를 조회한다.
7-4. db1에서 데이터를 조회한 경우, 정상적으로 출력된다.
Chapter4. 자잘한 내용들
1. ssh접속 시, 암호를 없애자
unison명령어는 unison root1 root2 [options]으로 되어 있다. 동기화하고자 하는 서버에 접속이 되어야 하는데 명령어 수행 시, 매번 상대방 계정의 암호를 입력해 주어야 되는 번거로움이 있다.
그래서 암호 없이 수행되도록 설정하자
[Server1 : hostname => db1]
- mkdir /root/.ssh
- cd /root/.ssh
- ssh-keygen -t rsa
- cat id_rsa.pub 내용을 복사
- su - cubrid
- mkdir /home/cubrid/.ssh
- cd /home/cubrid/.ssh
- vi authorized_keys 를 생성하여 server1에서 복사한 id_rsa내용을 복사해 넣는다.

※ ssh설정 때문에 안되는 경우가 있다. 이러한 경우 /etc/ssh/sshd_config에서 rsa옵션을 변경해 보자
========================
RhostsRSAAuthentication yes
RSAAuthentication yes
PasswordAuthentication yes
PermitEmptyPasswords yes
========================
ssh 재구동 : service sshd restart
2. 동기화 시 , 매번 값을 입력해야 하는가?
동기화 명령어는 아래와 같다.
그런데 위 명령어 수행 시, 파일들을 확인여부를 사용자에게 문의하고, 최종적으로 update할 것이냐고 또 물어본다. 데이터 변경 시 마다 , 파일마다 사용자가 확인하는 것은 너무 피곤하다.
그래서 -batch옵션을 추가하자. 일괄적으로 수행하는 옵션이다.
상대방 서버에서 가져올 때, cubrid계정이 접근하지 못하는 경우(예:root인 경우) 결과는 NULL로 출력된다. 그러므로 동기화파일의 권한을 조정하자.
-owner -group옵션을 추가하자.
3. crontab등록
최종적으로 동기화를 수행하기 위한 명령어는 아래와 같다.
unison /home/cubrid/DB/lob ssh://cubrid@192.168.83.134//home/cubrid/DB/lob -owner -group -batch
동기화를 위해 매번 사용자가 해당 명령어를 수행 시킬 수 는 없으므로, crontab에 등록하여 각 시스템성격에 맞게 수행할 수 있도록 설정해 주어야 한다.
% crontab -e : 편집모드
% crontab -l : 내용 출력
% service crond restart : 서버 재구동
4. 동기화 데이터가 많은 경우
데이터가 많은 경우 unison 옵션 중, -fastcheck를 추가해서 사용하자
CUBRID-HA는 시스템 운용에서 사용하기 좋은 기능이나, LOB 컬럼 또한 많은 서비스에서 사용하고 있다.
되도록 CUBRID-HA가이드를 따르는게 맞지만, LOB필히 사용해야 하는 서비스라면 unison사용을 검토하여 적용해 보자.
CUBRID-HA제약사항 중, Java Stored Procedure과 메서드 사용 문제가 있다. 각 Node들 끼지 복제가 되지 않기 때문에 제약사항임으로,
unison을 활용한다면, 이 두 가지 까지 극복할 수 있을 것이다.