CUBRID에서는 pivot()을 지원하지는 않지만 object 개념의 set 을 이용하여 간략하게 pivot()을 구현할 수 있다.
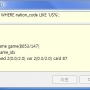
아래에서 CUBRID 에서 제공하는 시스템 카다로그 테이블중 테이블 정보(db_class), 필드정보(db_attribute)를 이용하여 각 테이블 별로 필드명을 출력하도록 만들어 보았다.
select class_name, list(select attr_name from db_attribute a where a.class_name = c.class_name) from db_class c
와 같이 질의를 하면 아래와 같은 결과를 볼수있다.
'glo' {'header_size', 'holder_obj', 'unit_size'}
'glo_holder' {'glo', 'lock', 'name'}
'glo_name' {'holder_ptr', 'pathname'}
'db_serial' {'att_name', 'class_name', 'current_val', 'cyclic', 'increment_val', 'max_val', 'min_val', 'name', 'owner', 'started'}
'db_stored_procedure_args' {'arg_name', 'data_type', 'index_of', 'mode', 'sp_name'}
'db_stored_procedure' {'arg_count', 'lang', 'owner', 'return_type', 'sp_name', 'sp_type', 'target'}
'db_partition' {'class_name', 'partition_class_name', 'partition_expr', 'partition_name', 'partition_type', 'partition_values'}
...
첫번째가 테이블명(class_name)이고, 두번째가 테이블의 필드명들을 pivot 형태로 만든 것이다.
pivot 된 결과는 {}로 감싸져있고 각 데이터들은 , 로 구분되어있으니, 이점을 감안하여 사용하면 된다.
아래에서 CUBRID 에서 제공하는 시스템 카다로그 테이블중 테이블 정보(db_class), 필드정보(db_attribute)를 이용하여 각 테이블 별로 필드명을 출력하도록 만들어 보았다.
select class_name, list(select attr_name from db_attribute a where a.class_name = c.class_name) from db_class c
와 같이 질의를 하면 아래와 같은 결과를 볼수있다.
'glo' {'header_size', 'holder_obj', 'unit_size'}
'glo_holder' {'glo', 'lock', 'name'}
'glo_name' {'holder_ptr', 'pathname'}
'db_serial' {'att_name', 'class_name', 'current_val', 'cyclic', 'increment_val', 'max_val', 'min_val', 'name', 'owner', 'started'}
'db_stored_procedure_args' {'arg_name', 'data_type', 'index_of', 'mode', 'sp_name'}
'db_stored_procedure' {'arg_count', 'lang', 'owner', 'return_type', 'sp_name', 'sp_type', 'target'}
'db_partition' {'class_name', 'partition_class_name', 'partition_expr', 'partition_name', 'partition_type', 'partition_values'}
...
첫번째가 테이블명(class_name)이고, 두번째가 테이블의 필드명들을 pivot 형태로 만든 것이다.
pivot 된 결과는 {}로 감싸져있고 각 데이터들은 , 로 구분되어있으니, 이점을 감안하여 사용하면 된다.