1. 설명
그룹에서 NULL 이 아닌 값들을 연결하여 결과 문자열을 VARCHAR 타입으로 반환한다.
2. 사용방법
GROUP_CONCAT([DISTINCT] expression [ORDER BY {column | unsigned_int} [ASC | DESC]] [SEPARATOR str_val]) |
expression -- 수치 또는 문자열을 반환하는 칼럼 또는 연산식
str_val -- 구분자로 쓰일 문자열
DISTINCT -- 결과에서 중복되는 값을 제거한다.
ORDERBY -- 결과 값의 순서를 지정한다.
SEPARATOR -- 결과 값 사이에 구분할 구분자를 지정한다. 생략하면 기본값인 쉼표(,)를 구분자로 사용한다.
Return type: STRING
3. 연결한 문자열이 1024 바이트 초과할 때 주의사항
group_concat_max_len 의 설정을 따른다. 기본값은 1024 바이트이며, 최소값은 4바이트, 최대값은 33,554,432바이트이다.
이 함수는 string_max_size_bytes 파라미터의 영향을 받는데, group_concat_max_len의 값이 string_max_size_bytes의 값보다 크고 GROUP_CONCAT 함수의 결과가 string_max_size_bytes의 크기 제한을 넘으면 오류가 반환된다.
string_max_size_bytes의 기본 값은 1,048,576 바이트(1M)이고, 최대값은 33,554,432 바이트(32M)이다.
즉, 기본설정 상태에서 group_concat_max_len는 1,048,576 바이트(1M)까지 설정 할 수 있고,
1M 이상일 경우에는 string_max_size_bytes 값도 함께 변경하여야 한다.
그룹 결과의 값 사이에 사용되는 기본 구분자는 쉼표(,)이며, 구분자를 명시적으로 표현하려면 SEPARATOR 절과 그 뒤에 구분자로 사용할 문자열을 추가한다.
구분자를 제거하려면 SEPARATOR 절 뒤에 빈 문자열(empty string)을 입력한다.
4. 인자로 사용되지 않는 컬럼으로 정렬하는 방법
ORDER BY를 이용한 정렬은 오직 인자로 사용되는 표현식(또는 칼럼)에 의해서만 가능
즉, group 처리하는 컬럼값으로만 정렬되고, 그 이외의 컬럼으로는 정렬이 불가 함
인라인뷰를 사용하여 우회하는 방법으로는 아래와 같은 방법이 있다.
select group_concat( col1 )
from (
select col1, col2, col3
from grp_test
order by col2
)
group by col3
예제( 인덱스 컬럼의 순서로 정렬하고, 컬럼명으로 group_concat 처리 )
SELECT
class_name, index_name, GROUP_CONCAT(key_col ), is_primary_key, is_foreign_key
FROM ( SELECT B.class_name, B.index_name,B.key_order, B.key_attr_name AS key_col, A.is_primary_key, A.is_foreign_key
FROM db_index_key B, db_index A
WHERE A.index_name = B.index_name
ORDER BY B.class_name, B.index_name, B.key_order
)
GROUP BY class_name, index_name
ORDER BY class_name, index_name ;
5. 사용 예제
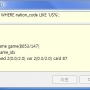
SELECT GROUP_CONCAT(s_name) FROM code; //SEPARATOR 구문 생략 시에는 ","로 구분
group_concat(s_name)
======================
'X,W,M,B,S,G'
SELECT GROUP_CONCAT(s_name ORDER BY s_name SEPARATOR ':') FROM code; //SEPARATOR 값을 ":"로 지정, 정렬순서 지정
group_concat(s_name order by s_name separator ':')
======================
'B:G:M:S:W:X'
SELECT GROUP_CONCAT(s_name ORDER BY s_name SEPARATOR '') FROM code; //SEPARATOR 값을 ""로 지정, 정렬순서 지정
group_concat(s_name order by s_name separator '')
======================
'BGMSWX'