
select count(wr_id) as cnt from board_write where wr_category like '%10'
select count(wr_id) as cnt from board_write where wr_category like '%1010'
:
:
:
select count(wr_id) as cnt from board_write where wr_category like '%10010'
위와같은 쿼리 100개정도를 한페이지에서 포문으로 돌려 실행시 mysql 에서는 로딩속도가 2초정도 걸렸는데
큐브리드에서는 10초정도 걸립니다. 스키마는 다음과 같습니다.
CREATE TABLE "board_write"(
"wr_id" numeric(20,0) DEFAULT 0 NOT NULL,
"bo_id" numeric(10,0) DEFAULT 0 NOT NULL,
"wr_num" numeric(20,0) NOT NULL,
"wr_reply" character varying(40) NOT NULL,
"wr_parent" numeric(10,0) DEFAULT 0 NOT NULL,
"wr_option" character varying(200) NOT NULL,
"wr_subject" character varying(510) NOT NULL,
"wr_preview" character varying(1000),
"wr_link1" character varying(510),
"wr_link2" character varying(510),
"wr_link1_hit" integer DEFAULT 0 NOT NULL,
"wr_link2_hit" integer DEFAULT 0 NOT NULL,
"wr_trackback" character varying(510),
"wr_hit" integer DEFAULT 0 NOT NULL,
"wr_good" integer DEFAULT 0 NOT NULL,
"wr_nogood" integer DEFAULT 0 NOT NULL,
"wr_comment" numeric(10,0) DEFAULT 0,
"mb_id" character varying(40) NOT NULL,
"wr_password" character varying(100) NOT NULL,
"wr_name" character varying(510) NOT NULL,
"wr_email" character varying(510) NOT NULL,
"wr_homepage" character varying(510),
"wr_time" timestamp NOT NULL,
"wr_last" timestamp NOT NULL,
"wr_ip" character varying(60) NOT NULL,
"wr_1" character varying(510),
"wr_2" character varying(510),
"wr_3" character varying(510),
"wr_4" character varying(510),
"wr_5" character varying(510),
"wr_6" character varying(510),
"wr_7" character varying(510),
"wr_8" character varying(510),
"wr_9" character varying(510),
"wr_10" character varying(510),
"wr_category" character varying(510)
);
CREATE INDEX "wr_num_reply_parent" ON "nb_board_write"("wr_num","wr_reply","wr_parent");
CREATE INDEX "wr_board_id" ON "nb_board_write"("bo_id","wr_id");
CREATE INDEX ON "nb_board_write"("wr_subject","wr_name","wr_time","wr_9","wr_category");
데이타 건수는 10만건 정도 됩니다.
어떻게 해야 하죠??
CUBRID 는 인터넷 응용을 위한 처리부분에 주안점을 두고 개발/개선을 하고 있으며, 일반적으로 중소규모의 업무의 사용에 무리없이 사용할 수 있습니다.
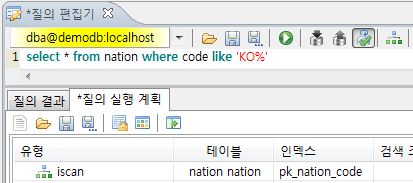
CUBRID 를 비롯하여 대부분의 데이터베이스에서 말씀하신 형태의 질의에 대하여 성능을 높이시려면 일단 wr_category 에 대한 재설계가 필요합니다. 검색에서 10으로 끝나는 wr_category를 찾고, 1010으로 끝나는 wr_category 를 찾는 다면, 1010으로 시작하는 wr_category, 10으로 시작하는 wr_category를 찾는 것이 데이터베이스에서는 성능을 높일 수 있는 방법입니다.
따라서 wr_cagetory 의 값이 10으로 끝나는 것이 아니라 10으로 시작하도록 설계를 변경한다면 질의는 다음의 두가지중 하나를 사용할 수 있으며, 이 경우 모두 인덱스를 사용하게 되므로 성능 향상을 가져 올 수 있습니다. 우절단(like '10%') 의 경우 CUBRID 내부적으로 between 질의로 변경하여 수행되므로 인덱스를 사용할 수 있게 됩니다.
select ... from ... where wr_category like '10%'
select ... from ... where wr_category between '10' and '10z' // wr_category 가 보통 숫자로만 이루어진다고 가정
추가적으로 CUBRID 에서는 count(*) 질의 수행시 unique 인덱스를 사용하게 되는 경우(조건이 unique 필드인 경우) 그렇지 않은 경우에 비하여 훨씬 나은 성능을 보여줍니다.