
* 질문 등록 시 다음의 내용을 꼭 기입하여 주세요.
|
|
Oracle Linux 7.9 |
|
|
10.2.5.8886 |
|
|
|
|
|
* CUBRID 응용 오류, SQL 오류 또는 SQL 튜닝 관련된 문의는 반드시 다음의 내용을 추가해 주세요. 비밀글이나 비밀 댓글도 가능합니다.
* 저희가 상황을 이해하고, 재현이 가능해야 알 수 있는 문제들이 많습니다. 가능한 정보/정황들을 부탁합니다.
| 에러 내용 및 재현 방법 | 재현 가능한 Source와 SQL |
| 관련 테이블(인덱스, 키정보 포함) 정보 | CUBRID 홈 디렉토리 아래 log 디렉토리 압축 |
-------------- 아래에 질문 사항을 기입해 주세요. ------------------------------------------------------------------------
CUBRID HA — CUBRID 10.2.0 documentation
귀사에서 제공하는 위 매뉴얼을 보고 슬레이브 재구축을 테스트해보고 있습니다.
(다른 시나리오는 정상적으로 테스트 완료했습니다.)
마스터-슬레이브-레플리카 환경은 매뉴얼과 동일하게 세팅했습니다.
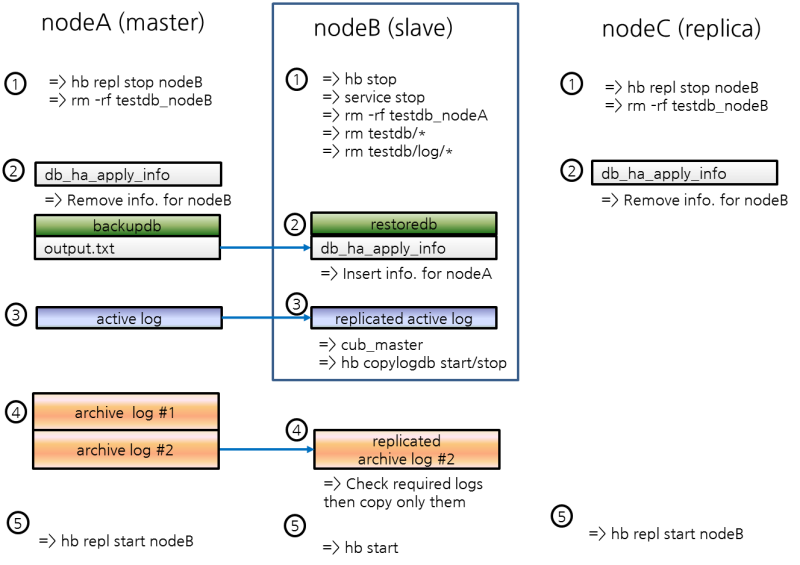
1) 첫 번째 문의사항
위 시나리오 중 5번 단계를 슬레이브 노드에서 수해아면 다음과 같은 에러가 발생합니다.
------------------------------------------------------------------------------------------------------
[cubrid@urp2 testdb_urp1]$ cubrid heartbeat start
@ cubrid heartbeat start
@ cubrid master start
++ cubrid master start: success
@ HA processes start
@ cubrid server start: testdb
This may take a long time depending on the amount of recovery works to do.
CUBRID 10.2
++ cubrid server start: success
@ copylogdb start
++ copylogdb start: success
@ applylogdb start
++ applylogdb start: success
++ HA processes start: fail
++ cubrid heartbeat start: fail
------------------------------------------------------------------------------------------------------
해당 에러가 발생했을 때의 로그 파일을 첨부합니다. (error log.zip)
2) 두 번째 문의사항
위 시나리오 중 1번 단계에서 cubrid hb repl stop 구문을 실행하면 다음과 같이 fail 메시지가 나옵니다.
------------------------------------------------------------------------------------------------------
[cubrid@urp1 ~]$ cubrid heartbeat repl stop testdb urp2
@ cubrid heartbeat replication
@ copylogdb stop
The server configured for HA is not listed in ha_node_list.
++ copylogdb stop: fail
@ applylogdb stop
The server configured for HA is not listed in ha_node_list.
++ applylogdb stop: fail
++ cubrid heartbeat replication: success
------------------------------------------------------------------------------------------------------
해당 명령어를 실행하면 copylogdb, applylogdb 프로세스가 중지되어야 하지 않나요?프로세스를 검색하면 다음과 같이 살아 있습니다.
------------------------------------------------------------------------------------------------------
[cubrid@urp1 ~]$ ps -ef | grep cub_
...
...
cubrid 21512 1 0 14:48 pts/1 00:00:02 cub_admin copylogdb -L /app/cubrid/CUBRID/databases/testdb_urp2 -m sync testdb@urp2
cubrid 21514 1 0 14:48 pts/1 00:00:05 cub_admin applylogdb -L /app/cubrid/CUBRID/databases/testdb_urp2 --max-mem-size=300 testdb@localhost
------------------------------------------------------------------------------------------------------
그래서 다음 두 개의 명령어로 중지 시켰는데 이렇게 중지 시켜도 맞을까요?
- cubrid heartbeat copylogdb stop testdb urp2
- cubrid heartbeat applylogdb stop testdb urp2
3) 세 번 째 문의사항
위 시나리오를 보면 슬레이브 노드에서 db_ha_apply_info 테이블의 레코드를 삭제하는 부분이 없습니다.
그러나 매뉴얼 상에서는 1번 단계에서 슬레이브 노드의 데이터베이스 볼륨을 삭제하고 db_ha_apply_info 정보를 삭제하는 부분이 있습니다.
데이터베이스 볼륨을 삭제했다는 것은 DB 자체가 지워진건데, 그럼 csql로 접속이 안될텐데 잘못된 부분이 아닐지요...
답변 부탁 드리겠습니다..


- 올려주신 error log 중 applylogdb의 error를 보니 db_ha_apply_info를 초기화하지 못해 오류가 발생했습니다.
구성시 db_ha_apply_info 내용을 삭제하셨나요 ?
(2) 두번째 문의 사항의 답변
- cubrid_ha.conf의 ha_node_list 부분이 제대로 설정되지 않아 오류가 발생한 것 같습니다. 확인해보세요.
- cubrid heartbeat copylogdb/applylogdb stop으로 정지시켜도 됩니다. 또한 kill pid로 하셔도 됩니다.
(3) 세번째 문의 사항의 답변
- 그림을 보시면 (1)번에 slave DB를 삭제하고 (2)번에서 master의 백업 본으로 slave에 restoredb를 통해 DB를 재구성한 후 csql를 통해 db_ha_apply_info 데이타를 삭제하게 되어 있습니다. 즉, csql는 복구된 DB에 접속하는 것입니다.