
대상 : CUBRID2008 R1.x 이상
본 문서에서는 데이터베이스 생성방법에 대하여 작성하였습니다. CUBRID에서 데이터베이스 생성시 참고하시면 됩니다.
용량 산정
생성할 데이터베이스의 크기를 산정합니다. 일반적으로 각 테이블의 예상되는 레코드수 * 레코드 크기를 더한 값으로 데이터의 크기를 가늠합니다. 그런 다음 인덱스의 크기를 산정하는데 간단히 데이터 크기의 30% 정도를 인덱스 크기로 산정할 수 있습니다.
또한 CUBRID 에서는 질의 처리를 위한 temp volume 이 필요한데 이 크기는 질의의 복잡도에 따라 달라지며, 역시 데이터의 크기에 따라 달라집니다. 일반적으로 인덱스와 마찬가지로 데이터의 30% 수준으로 생성을 한후 실 운영중 모니터링을 통하여 추가로 필요한 크기를 알아내어 추가할 수 있습니다.
데이터베이스의 크기는 산정한 용량에 약 1.5~2배를 하면 실 데이터베이스의 크기를 얻어낼 수 있읍니다. 이 크기를 이용하여 데이터베이스를 생성하시면 됩니다.
CUBRID에서는 데이터 저장 공간은 data volume, 인덱스 저장 공간을 index volume 라고 부르고 있습니다.
여기서는 산정된 데이터의 양이 약 2G로 가정하여, 데이터베이스의 data volume은 4G, index volume은 1.2G, temp volume은 1.2G의 크기를 가지는 것으로 가정합니다.
생성 위치 결정
데이터베이스는 디스크 I/O가 굉장히 많으므로 디스크 구성을 잘하여 주어야 하며, 디스크 구성 관련 부분은 별도의 문서를 참고하시기 바랍니다.
다른 응용과는 별도의 파티션에 생성할 것을 권장하며, 사용가능한 파티션이 많다면 데이터베이스를 구성하는 각 볼륨(화일)을 적절히 분산해 주는 것이 좋습니다. 기본적으로는 CUBRID 엔진과는 별도의 위치에 생성하며, 데이터베이스 로그도 가능하다면 별도의 파티션에 분리하여 주는 것이 좋습니다.
여기서는 사용가능한 파티션이 /data, /data1 두개가 있다고 가정하여 각 파티션에 데이터베이스를 분리 생성하도록 합니다. /data 아래에 data volume 등 기본 데이터베이스 설치 위치로 하고, /data1 을 데이터베이스 로그가 위치하도록 가정합니다.
데이터베이스 생성
이제 데이터베이스를 생성합니다. 데이터베이스 생성은 CUBRID Manager client 를 이용하여 생성하는 방법을 보여드리겠습니다. 마지막 부분에 명령어를 이용하는 방법도 추가하였으니 참고하시기 바랍니다.
CUBRID Manager client 를 실행합니다. 시작메뉴-CUBRID-CUBRID Manager client 를 실행하거나, LINUX 의 경우 CUBRID 가 설치된 디렉토리 아래 cubridmanager/cubridmanager 를 실행하면 됩니다. LINUX 의 경우 console 이거나 X-manager 등이 있어야 합니다.
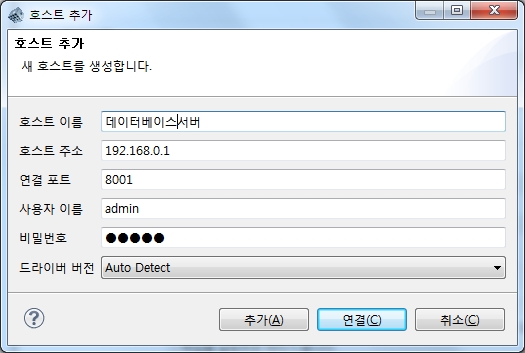
실행후 동일 서버의 경우 좌측 상단의  를 직접 클릭하시고, 다른 서버로 접근하는 경우 좌측 상단의 "호스트 추가..."
를 직접 클릭하시고, 다른 서버로 접근하는 경우 좌측 상단의 "호스트 추가..."  를 클릭하여 아래 항목을 입력합니다.
를 클릭하여 아래 항목을 입력합니다.
* 호스트이름 : 식별가능한 서버의 이름을 입력하면 됩니다.
* 호스트주소 : 서버이름이나 IP 주소를 입력합니다.
* 연결포트 : 8001을 기본적으로 사용합니다.
* 사용자이름 : 사용자 이름을 입력합니다. 초기 접근시 admin 으로 접근해야 하며, admin 은 모든 관리 권한을 가지고 있습니다.
* 비밀번호 : 사용자의 비밀번호이며, 초기 admin 의 비밀번호는 admin 입니다.
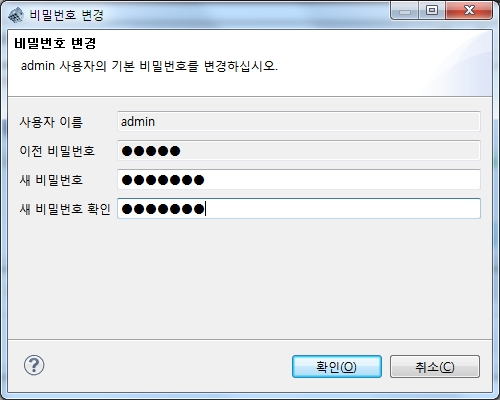
최초 접속인 경우 admin 의 비밀번호를 변경해야 합니다. 적절한 암호로 변경하시고, "다시 로그인하시겠습니까?" 에 "예"를 클릭하면 로그인이 됩니다.

로그인 후 보여지는 화면에서 상단의  아이콘을 클릭하여 데이터베이스 생성 마법사로 들어갑니다. 만약 해당 아이콘이 클릭되지 않으면 좌측에 로그인한 서버를 선택(
아이콘을 클릭하여 데이터베이스 생성 마법사로 들어갑니다. 만약 해당 아이콘이 클릭되지 않으면 좌측에 로그인한 서버를 선택(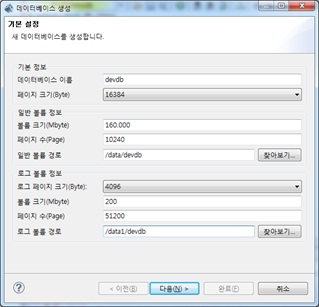 클릭)한 후 다시 클릭해보면 됩니다.
클릭)한 후 다시 클릭해보면 됩니다.
보여지는 화면에서 아래의 정보를 입력합니다.
* 기본 정보
- 데이터베이스 이름 : 응용에서 사용할 데이터베이스 이름을 입력합니다. devdb 로 가정합니다.
- 페이지 크기 : 16384 를 선택합니다. 페이지는 CUBRID 의 I/O 단위입니다. HA 환경등 내부 성능 테스트 결과 가장 무난한 것으로 알려져 있습니다.
* 일반 볼륨 정보 : 스키마 정보 및 시스템 카다로그(간단이해:스키마 정보가 저장된 테이블) 정보 등이 저장되는 곳입니다.
- 볼륨 크기 : 100M 정도면 무난합니다. 기본 값을 그대로 두어도 됩니다.
- 페이지수 : Mbyte 를 페이지수로 보여주는 것입니다. 수정할 필요 없습니다.
- 일반 볼륨 경로 : 데이터베이스의 위치를 지정합니다. 앞서 설정한 /data 아래 데이터베이스 이름을 포함하여 지정합니다. 즉, /data/devdb 를 입력합니다. 우측의 "찾아보기"는 동일서버일 경우만 가능하며 별도의 데이터베이스 서버로 접속한 경우에는 사용할 수 없습니다.
* 로그 볼륨 정보 : 데이터베이스의 로그가 저장되는 곳입니다. 입력/수정/삭제에 대한 모든 로그가 저장됩니다. 사람이 볼수있는 내용은 아닙니다.
- 로그 페이지 크기 : 16384 를 선택합니다. HA 환경등 내부 성능 테스트 결과 가장 무난한 것으로 알려져 있습니다.
- 볼륨 크기 : 200(M)을 입력합니다. HA 환경등 내부 성능 테스트 결과 가장 무난한 것으로 알려져 있습니다.
- 페이지수 : Mbyte 를 페이지수로 보여주는 것입니다. 수정할 필요 없습니다.
- 로그 볼륨 경로 : 데이터베이스 로그의 위치를 지정합니다. 앞서 설정한 /data1 아래 데이터베이스 이름을 포함하여 지정합니다. 즉, /data1/devdb 를 입력합니다.
입력후 "다음"을 클릭합니다.

아래 화면에서 data volume과 index volume, temp volume 를 추가합니다. 이중 data volume은 4G로 만들어야 하는데 32bit 로 설치가 된 경우 최대 2G까지밖에 만들 수가 없으므로 이 경우에는 2G 짜리 2개를 만들면 됩니다.
* 볼륨 경로 : 앞서 지정한 데이터베이스 위치와 동일하게 합니다. 즉, /data/devdb 를 입력합니다.
* 볼륨 형식 : 추가할 볼륨의 형식을 선택합니다. data volume 일 경우 data 를, index volume의 경우 index 를 선택합니다.
* 볼륨 크기 : 앞서 산정한 각 볼륨 별 크기를 입력합니다. 여기서는 32 bit 가 설치된 것을 가정하여 2000(M, 즉 2G)를 입력합니다.
* 페이지수 : 앞서와 마찬가지로 자동계산되는 것이니 그대로 놔두면 됩니다.
위와 같이 입력후 우측 중간의 "볼륨추가"를 클릭하면 아래의 "추가 볼륨 리스트"에 생성할 볼륨 리스트가 추가되어 집니다. 이와 같이 필요한 볼륨(지금 예의 경우 data volume 2개, index volume 1개, temp volume 1개)을 리스트에 넣은 후 "다음"을 클릭합니다.


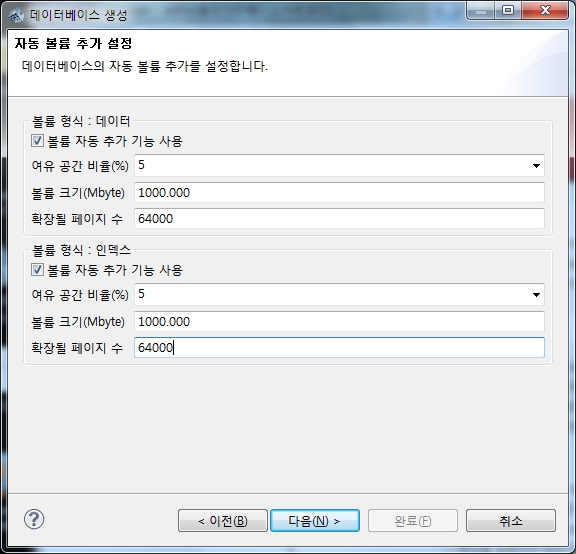
다음으로 각 data, index volume이 다 사용될 경우 자동으로 추가하기 위한 설정을 합니다. "볼륨 자동 추가 기능 사용" 을 체크하고, 볼륨 크기는 앞서 지정한 볼륨 크기와 동일한 것이 좋습니다. 다만 그 크기가 너무 커서 볼륨 추가에 시간이 걸린다면 적절한 크기로 줄여주는 것이 좋습니다. 볼륨 자동 추가는 데이터베이스 서버가 판단하여 처리하게 되므로 업무시간중에 추가될 수 있으며 그럴 경우 I/O 증가로 서비스 지연이 발생할 수 있기 때문입니다. 따라서 자동 추가는 설정하되 관리자가 주기적으로 확인하여 사용자가 적은 시간에 적당한 크기의 볼륨을 추가하는 것이 좋습니다.
다음은 데이터베이스 dba 암호를 지정합니다. dba 는 데이터베이스 관리자로써 데이터베이스에 대한 모든 권한을 가지고 있으므로 반드시 암호를 지정해야 합니다.

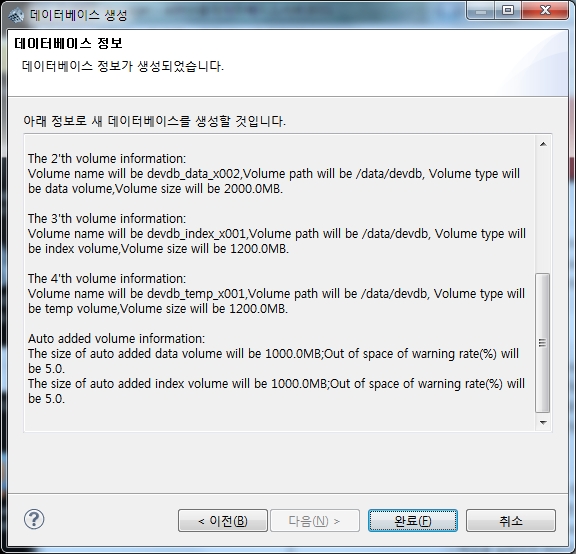
마지막으로 사용자가 설정한 내용을 보여줍니다. 확인후 이상이 없으면 "완료"를 클릭하면 데이터베이스가 생성됩니다.
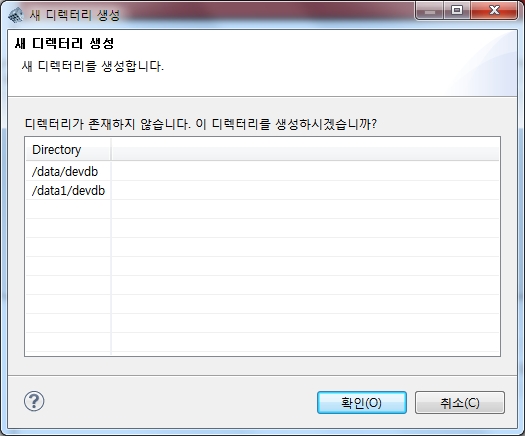
만약 데이터베이스가 위치할 디렉토리가 존재하지 않으면 생성여부를 물어옵니다. "확인"을 클릭하여 디렉토리가 생성되도록 합니다.

데이터베이스 생성이 완료되면 데이터베이스 서버가 자동으로 구동됩니다.

백업 계획 생성
데이터베이스 백업은 운영중 장애로 인하여 데이터베이스가 손상되거나, 관리등의 실수로 인하여 데이터가 변경/삭제되었을 때 이의 복구를 위하여 굉장히 중요한 기능합니다. 따라서 적절한 백업 계획을 생성하여 데이터베이스가 주기적으로 백업되도록 합니다.
백업 및 복구에 관련된 내용은 별도의 문서를 참고하시기 바랍니다.