






CUBRID 2008 R2.2업그레이드방안(Linux)
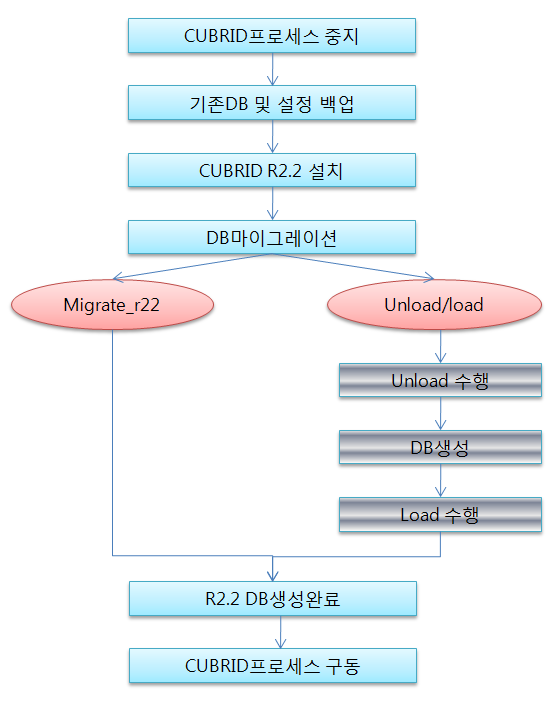
조회 수 3693 추천 수 0 2010.07.30 03:48:41CUBRID R2.2(이하 R2.2) 이전버전(CUBRID R1.x이상)에 대한 업그레이드 절차는 아래 그림과 같은 작업 순서로 진행을 하여야 한다.
DB 마이그레이션의 DB 크기 및 시스템성능(특히, I/O)에 따라 수행시간이 오래 걸릴 수 있다.
Linux환경에서 CUBRID관련 명령어를 수행할 경우 CUBRID제품이 설치되어 있는 계정을 사용한다.
CUBRID 설치 환경 확인
CUBRID버전 정보
아래 예와 같이 명령어를 수행하여 CUBRID 제품버전이 R1.4이하 임을 확인한다.
-bash-3.2$ cubrid_rel
CUBRID 2008 R1.4 (8.1.0.1150)
설치할 CUBRID Bit수 결정
OS의 bit수를 확인 하여 다운 받을 R2.2 버전의 bit수를 결정해야 한다.
OS의 bit수가 32bit일 경우 R2.2설치도 32bit버전을 설치하여야 한다. 아래는 OS의 bit수를 확인 하는 방법이다.
-bash-3.2$ getconf LONG_BIT
64
CUBRID관련 프로세스 중지
아래 명령어를 이용하여 모든 프로세스를 종료 시킨다.
-bash-3.2$ cubrid service stop
@ cubrid broker stop
++ cubrid broker stop: success
@ cubrid manager server stop
++ cubrid manager server stop: success
@ cubrid master stop
++ cubrid master stop: success
백업
데이터베이스 백업
R2.2버전은 기존의 DB의 이미지 및 백업 이미지를 사용 할 수 없다.
따라서, 기존 DB백업 이 필요하며 백업의 방법에는 언로드, backupdb, copydb등의 CUBRID유틸을 통해 수행 할 수 있다.
만약, 데이터량이 많고 중요 데이터(예: 회원정보, 회계관련정보)가 있는 경우 안정성을 위하여 언로드를 통해 백업을 하는 것을 권장한다.
또한 언로드를 수행한 결과를 이후 R2.2로 DB 업그레이드를 수행하게 되므로 언로드를 수행한 경로를 숙지한다.
언로드를 수행하기 위해서는 DB의 크기를 감안하여 충분한 여유공간이 필요하며, 아래는 수행하는 예이다.
언로드관련 참고 자료는 메뉴얼 > 관리자 안내서 > 데이터베이스 마이그레이션 을 참조
-bash-3.2$ cd $DB_VOL
## $DB_VOL은 언로드를 받을 수 있는 충분한 공간이 있는 곳으로 가정한다.
-bash-3.2$ mkdir UNLOAD
-bash-3.2$ cd UNLOAD
-bash-3.2$ cubrid unloaddb –S –v demodb
-bash-3.2$ cubrid unloaddb demodb
위에서 언급한 수행방법 이외에 DB구성파일들을 파일로 백업하는 방법이 있다.
DB구성 파일 확인 방법은 $CUBRID_DATABASES/databases.txt 파일을 확인하면 된다.
-bash-3.2$ cat $CUBRID_DATABASES/databases.txt
demodb /DB/VOL/demodb localhost /DB/LOG/demodb
DB이름, 볼륨경로, 호스트네임, DB log경로 순으로 나열되어 있으며, 아래와 같이 DB경로의 파일과 DB log경로의 파일을 복사하면 된다.
-bash-3.2$ cp –R /DB/VOL/demodb $DB_VOL_BACKUP
-bash-3.2$ cp –R /DB/LOG/demodb $DB_LOG_BACKUP
## $DB_VOL_BACKUP, $DB_LOG_BACKUP의 경로는 파일을 복사할 수 있는 충분한 공간이 있는 곳으로 가정한다.
환경설정 백업
기존의 설정 및 구성파일을 백업하지 않을 경우 default 설치 시 초기화 될 수 있으므로 아래와 같이 간단하게 백업을 수행한다.
-bash-3.2$ mv CUBRID CUBRID_OLD
CUBRID R2.2 설치 및 구성
설치 전 환경 및 구성파일 백업
기존의 설정 및 구성파일을 백업하지 않을 경우 default 설치 시 초기화 될 수 있으므로 아래와 같이 간단하게 백업을 수행한다.
-bash-3.2$ mv CUBRID CUBRID_OLD
설치
큐브리드 매뉴얼의 UBRID시작 è 설치와 실행 è Linux에서의 설치와 실행을 참조하여 설치를 진행한다.
단, 아래 예와 같이 환경설정만 적용하고 서비스 구동을 시키지 않도록 하자.
이전에 설치를 해보았다면 매뉴얼 참조 없이 손쉽게 설치를 진행 할 수 있다.
-bash-3.2$ . /home/cubrid/.cubrid.sh
-bash-3.2$ cubrid service start è 수행하지 않는다.
설치확인
위에서 제품버전확인과 같이 동일 명령을 수행하여 버전정보를 확인한다.
-bash-3.2$ cubrid_rel
CUBRID 2008 R2.2 (8.2.2.0261) (Apr 28 2010 21:09:02)
설치완료 후 기존의 환경 설정 및 구성파일 복구
초기설치 경로에 설치를 완료하였다면 계정 $HOME/CUBRID 폴더가 생성되었을 것이다.
이전 버전의 경로는 $HOME/CUBRID_OLD이며 환경설정 파일과 데이터베이스 정보파일 복사를 수행하여 R2,2버전에 적용시켜야 한다.
아래는 해당파일들을 복사하는 예이다.
-bash-3.2$ cd $CUBRID
-bash-3.2$ mv conf conf_ORG
-bash-3.2$ cp -R $HOME/CUBRID_OLD/conf .
## 환경설정파일 복사
-bash-3.2$ cd $CUBRID_DATABASES
-bash-3.2$ cp $HOME/CUBRID_OLD/databases/databases.txt .
## 데이터베이스 정보파일 복사
R2.2버전에서 추가되거나 변경된 파라미터가 존재할 수 있으므로 매뉴얼을 참조하여 설정을 변경하여야 한다.
뿐만 아니라, 성능개선의 여지가 있을 수 있으므로 매뉴얼 > 성능튜닝 부분을 참조하여 파라미터 조정하는 것이 바람직하다.
한 예로, index_scan_oid_buffer_pages 파라미터 값이 작을수록 성능에 유리 하므로 정수형에서 실수형으로 변경 되었으므로, 최소값인 0.05로 설정해야 한다.
DB migration 수행
기존에 사용되고 있는 버전의 이미지의 경우 R2.2에서 인식이 안되므로 migration도구를 이용하여 이미지를 R2.2로 변경하여야 한다.
데이터량이 많을 경우 migration도구를 사용하지 않고 unload/load 명령을 통하여 재구성하는 것을 권장한다.
위와 같은 경우 문서내의 데이터베이스 백업에서 설명한 것과 같이 unload를 수행하였다면 load를 수행하여 DB를 migration하여야 한다.
Migration 도구를 이용하는 방법
기존의 DB경로가 백업한 CUBRID_OLD 폴더 내에 존재한다면 동일한 경로를 생성한 후 DB를 복사하여 R2.2에서 인식이 가능하도록 설정을 해야 한다.
아래와 같이 migration도구를 이용하여 R2.2버전 이미지로 변환한다.
-bash-3.2$ ./migrate_r22 demodb
CUBRID Migration: 8.2.0 to 8.2.2
start to fix volume header
start to fix system classes
db_serial class was fixed.
db_class class was fixed.
db_partition class was fixed.
migration success
load 명령을 이용하는 방법
이전에 DB로부터 unload를 수행해야만이 load를 수행할 수 있다. 또한 load를 수행하기 위한 공간인 DB가 필요하다.
보다 자세한 사항은 메뉴얼 > 관리자 안내서 > 데이터베이스 마이그레이션 을 참조
load를 수행하기 위한 DB를 생성하기 위해서는 기존에 사용된 DB의 사용된 공간 확인이 필요하며 이 보다 큰 공간의 DB를 생성해야 한다.
R2.2로 업그레이드 이후 이전 DB의 사용공간 확인이 어려우므로 unload를 수행한 경로에 object파일의 크기와 *.lo파일들(멀티미디어데이터)의 크기를 이용하여 산정하면 된다.
우선 load를 수행하기 위해 createdb명령을 이용하여 DB를 생성 및 addvoldb명령을 통해서 충분히 가용한 공간을 생성한다.
아래는 DB생성 예이다.
-bash-3.2$ mkdir $DB_VOL
-bash-3.2$ mkdir $DB_LOG
## $DB_VOL은 DB를 생성할 수 있는 충분한 공간이 있는 곳으로 가정한다.
## $DB_LOG은 생성할 DB의 로그경로를 가정한다.
-bash-3.2$ cubrid created –f $DB_VOL –L $DB_LOG CUBRID2_2
## DB생성
-bash-3.2$ cubrid addvoldb –p data –S CUBRIDR2_2 500000
-bash-3.2$ cubrid addvoldb –p index –S CUBRIDR2_2 250000
-bash-3.2$ cubrid addvoldb –p temp –S CUBRIDR2_2 250000
## 생성된 DB에 대하여 data, index, temp영역을 생성
보다 자세한 사항은 관리자 안내서 > 데이터베이스 관리 > 데이터베이스 생성 및 볼륨 추가 을 참조
기존의 DB이름과 동일한 DB를 생성 시 환경백업을 통해 databases.txt에 이미 기존의 DB명이 존재하므로 생성할 수 없다.
이런 경우 $CUBRID_DATABASES/databases.txt 파일을 편집하여 동일한 DB명이 있는 라인을 삭제 해야 한다.
DB생성이 완료 되었다면 아래와 같은 순서로 load를 수행하여 DB를 구성한다.
-bash-3.2$ cubrid loaddb -u dba -s demodb_schema CUBRID2_2
## 스키마 로드
-bash-3.2$ cubrid loaddb -u dba -d demodb_objects –c 10000 –v CUBRID2_2
## 데이터
-bash-3.2$ cubrid loaddb -u dba -i demodb_indexes –v CUBRID2_2
## 인덱스
-bash-3.2$ cubrid loaddb -u dba -i demodb_trigger –v CUBRID2_2
## 트리거
위 예는 기존에 unload받은 파일들이 스키마, 데이터, 인덱스, 트리거가 있다고 가정한 것 이므로 파일 중 존재하지 않는 파일은 수행할 필요가 없다.
cubrid_service명령을 통해 프로세스를 구동 시키다.
-bash-3.2$ cubrid service start
@ cubrid master start
++ cubrid master is running.
@ cubrid broker start
++ cubrid broker is running.
@ cubrid manager server start
++ cubrid manager server is running.
Migration을 한 DB에 대하여 아래와 같이 구동을 시킨다.
-bash-3.2$ cubrid server start demodb
@ cubrid server start: demodb
This may take a long time depending on the amount of recovery works to do.
CUBRID 2008 R2.2
++ cubrid server start: success