
1. 들어가며
https://www.cubrid.com/index.php?mid=blog&page=2&document_srl=3827667
본문을 읽기 전에 위 링크의 글을 읽어보시는 것을 추천 드립니다.
2. CUBRID 사용 시 유의 사항
현재 DBeaver에서 CUBRID를 완벽하게 지원하고 있지 않기 때문에 사용할 수 없거나 누락된 기능이 존재합니다.
몇 가지 예시는 다음과 같습니다.
- Trigger, Sequence 정보 확인 불가
- FK의 ON DELETE / ON UPDATE 옵션 수정 불가
- column 생성 기능 사용시, Data Type, auto_increment, collation등 몇가지 기능 누락 및 사용 불가
- 뷰 테이블 생성, 수정 불가
- JavaSP 확인 불가
- Query Execute Plan 확인 불가
따라서 위에 기록된 기능을 사용해야 할 경우 Query를 직접 작성하여 사용하는 것이 권장됩니다.
2. DBeaver 설치 방법
위 글에서는 DBeaver를 installer를 통해 설치하는 것을 설명하고 있습니다.
DBeaver는 Eclipse RCP 프로그램이기 때문에 installer를 사용하지 않고 설치할 수 있는 방법이 두가지가 더 있습니다.
- zip을 활용한 portable 버전 설치
- Eclipse 내부의 plugin 방식을 통한 설치
* zip을 활용한 portable 버전 설치
이 글에서는 윈도우 기준으로 설명하고 있습니다.

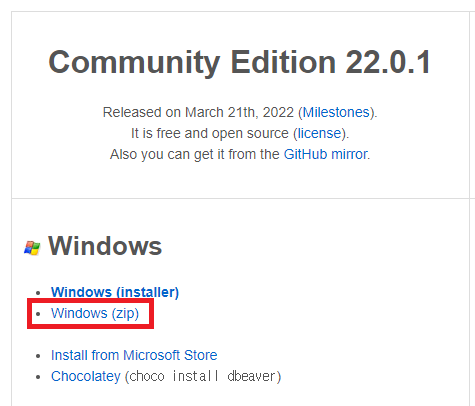
- https://dbeaver.io/download/ 에서 zip 파일을 다운로드 받습니다.
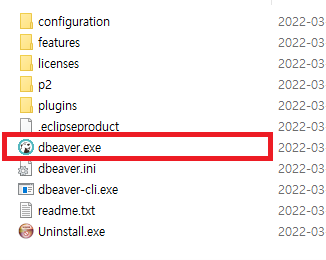
- 원하는 위치에 압축을 해제한 후 dbeaver.exe를 실행하여 사용할 수 있습니다.
* Eclipse 내부의 plugin 방식을 통한 설치
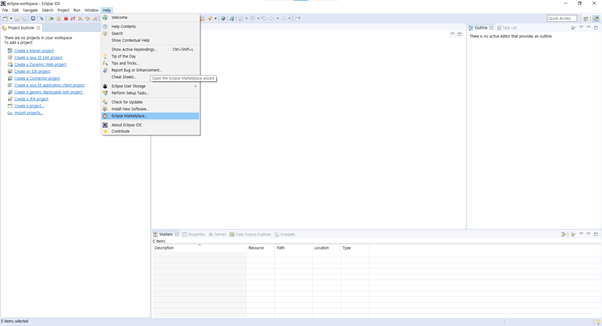
- Eclipse에서 Help -> Eclipse Marketplace를 클릭합니다.
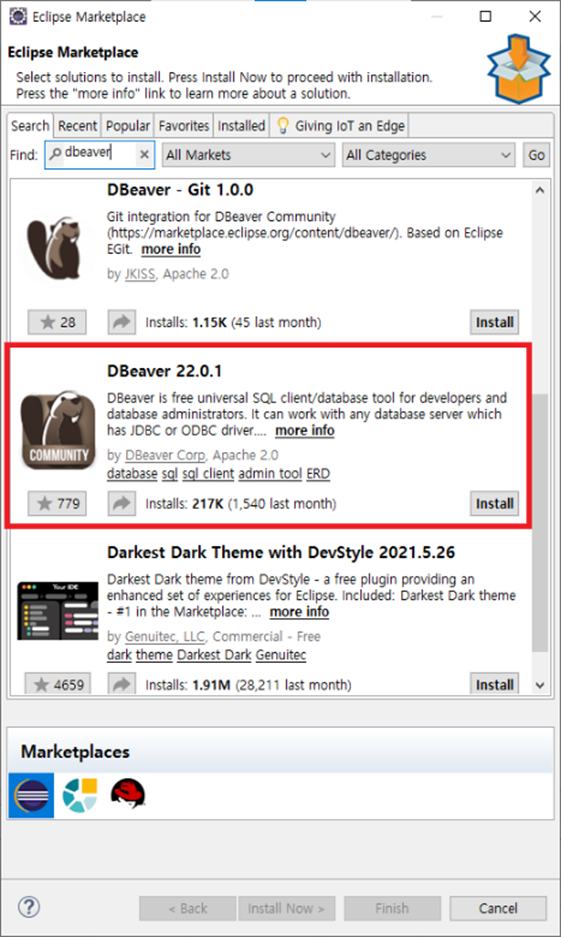
- DBeaver를 검색한 후 DBeaver를 install 합니다.
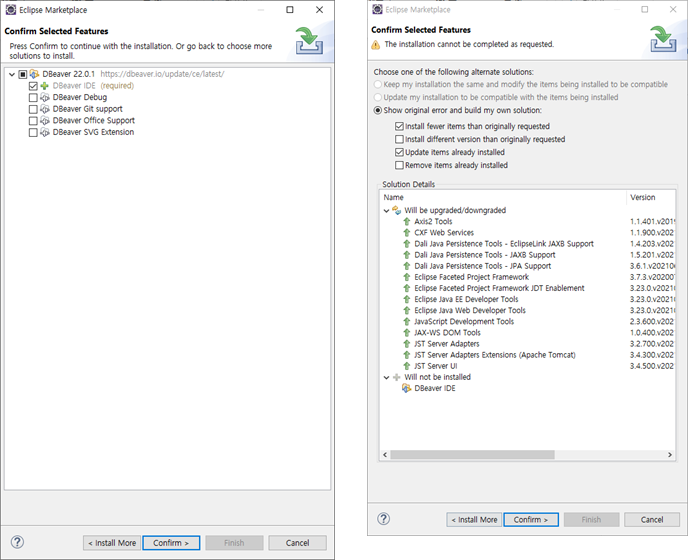
- 필요 프로그램 설치, 권한 동의 등 설치를 진행한다.
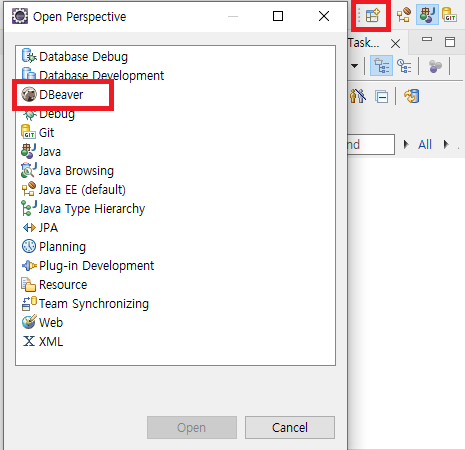
- 설치가 완료되면 Eclipse를 리부팅 후 Perspective에서 DBeaver를 선택하고 추가한다.
3. DBeaver로 CUBRID 연결
기본적인 연결 내용은 위 링크의 글과 다르지 않습니다.
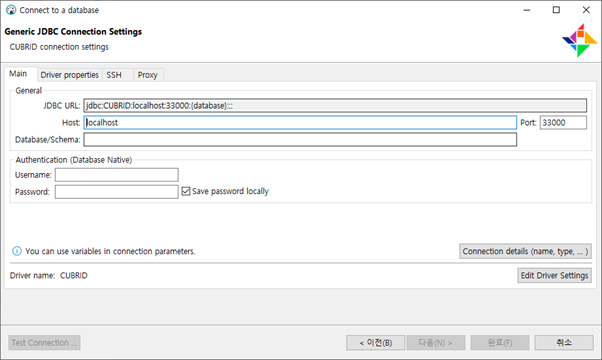
- 22.0.1 버전의 create connection 화면
Connection details
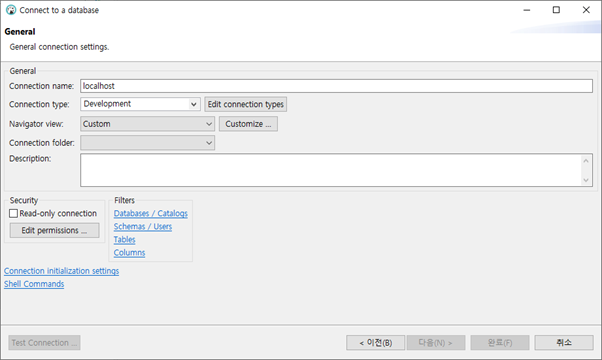
- Connection name: DBeaver 에서 연결을 생성한 후 표시할 이름을 입력합니다. 기본은 접속 IP 입니다.
- Connection type: 해당 연결의 목적을 설정합니다. 연결 생성 후 데이터베이스를 표시하는 항목에서 색깔만 입혀지며, 실질적인 기능 차이는 없습니다.
- Navigator view: 연결 생성 후 볼 수 있는 오브젝트들의 범위를 설정합니다.
- Customize를 통해서 system object, schema, table등 표시할 오브젝트를 결정할 수 있습니다.
- Description: 하단에 표시할 데이터 베이스의 설명을 설정합니다.
- Security: DBeaver를 통해 관리할 오브젝트에 대한 권한을 설정합니다. Edit permission에는 아래와 같은 항목이 있습니다.
-
Restrict data edit: 데이터를 수정하는 것을 제한합니다.
-
Restrict structure edit: 오브젝트(table, view)에 변경이 생기는 것을 제한합니다.
-
Restrict script execute: 사용자가 SQL을 작성하여 실행하는 것을 제한합니다.
-
Restrict data import: 데이터를 import를 제한합니다.
-
Edit Driver Setting -> Setting
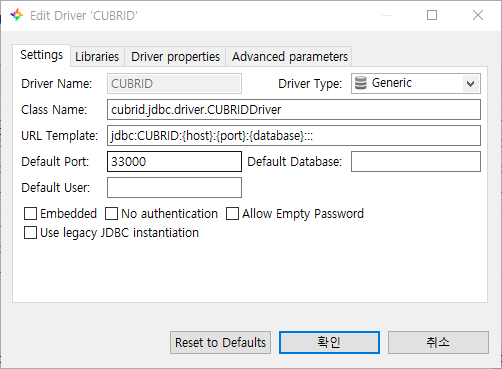
- 기존 connection setting과 동일한 내용입니다.
Libraries
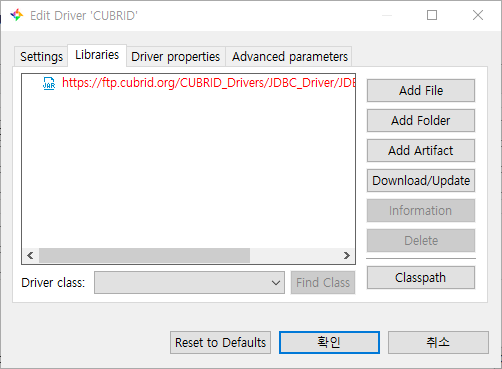
- connection을 생성할때 사용할 JDBC 드라이버를 설정할 수 있습니다.
DBeaver에서는 기본으로 10.1.0버전의 드라이버를 설정하도록 되어있습니다.
따라서 10.1.0버전을 사용하지 않는 경우 CUBRID 공식 홈페이지에서 사용하는 DB버전에 맞는 드라이버를 다운로드하여 사용합니다.
CUBRID 드라이버 다운로드: https://www.cubrid.org/downloads
Driver properties
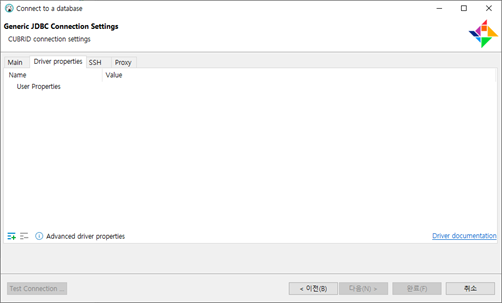
- CUBRID에 연결할 때 사용할 property를 설정할 수 있습니다. (ex: altHost, loadBalance, connectTimeout)
사용가능한 property 목록 참고: https://www.cubrid.org/manual/ko/11.0/api/jdbc.html
Advanced parameter
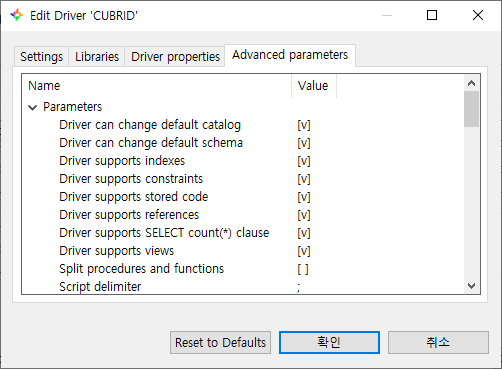
- DBeaver에서 연결시에 지원하는 기능들을 사용할 수 있습니다.
자세한 옵션 설명은 DBeaver 공식 메뉴얼 173 페이지를 참고하세요: https://dbeaver.com/doc/dbeaver.pdf
SSH
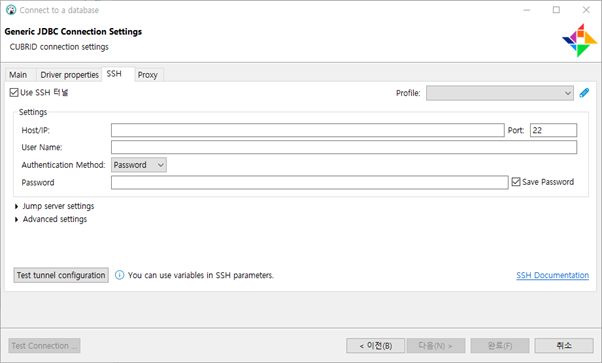
- SSH환경에서 연결이 필요할 경우 사용하는 설정입니다.
Proxy
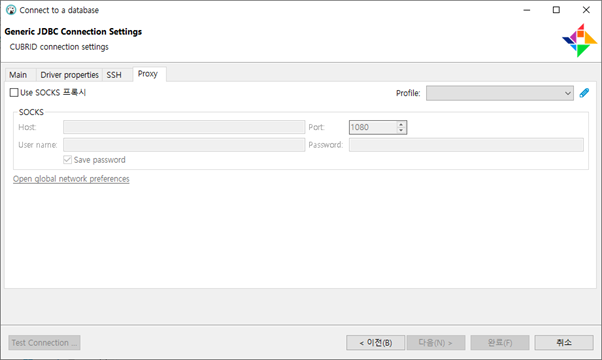
- Proxy환경에서 연결이 필요할 경우 사용하는 설정입니다.
4. DBeaver에서 Table 생성 및 수정
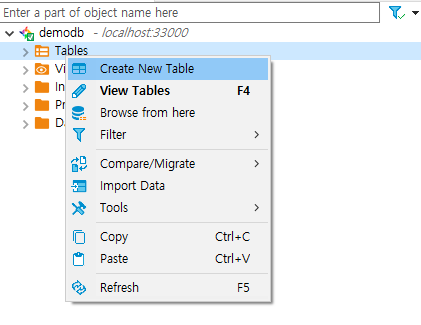
- 연결에서 Tables를 우클릭-> Create New Table을 선택합니다.
Columns
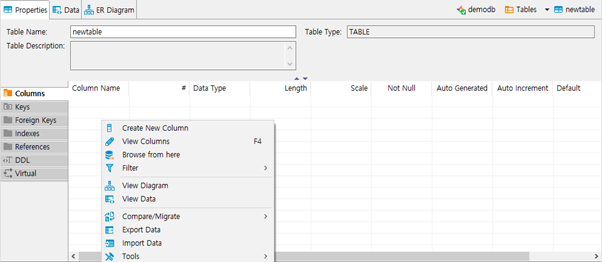
- Columns 항목에서 우클릭 -> Create New Column을 선택합니다.
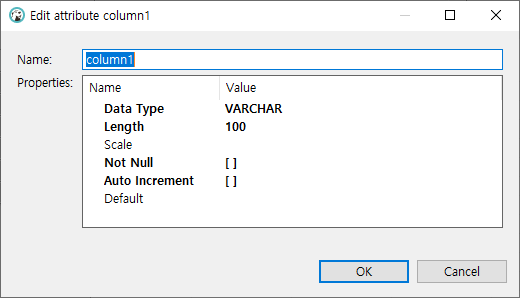
- column설정창에서 필요한 정보를 입력합니다.
- Name: 컬럼 명을 작성합니다.
- Data Type: 데이터 타입을 선택합니다. 만약 선택하려는 Data Type이 콤보박스에 없을 경우 직접 입력하여 설정할 수 있습니다.
- Length: 컬럼의 길이를 설정합니다.
- Scale: 특정 데이터 타입의 스케일을 설정합니다.
- Not Null: Not Null 제약조건을 걸 것인지 선택합니다.
- Auto Increment: Auto Increment 제약조건을 걸 것인지 선택합니다.
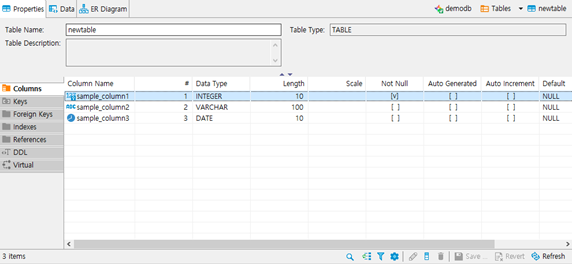
- column을 추가하면 위와 같이 등록 됩니다.
Keys
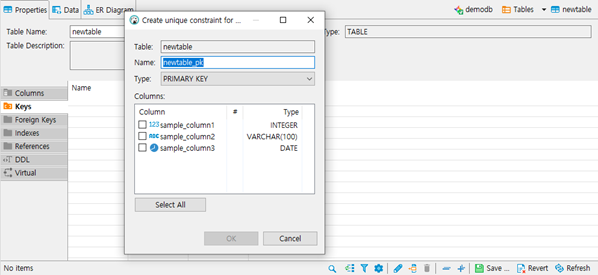
- column에 PK, UK를 설정합니다.
- Name: Key의 이름을 설정합니다.
- Type: PK, UK를 선택합니다
- Columns: Key를 설정할 컬럼을 지정합니다.
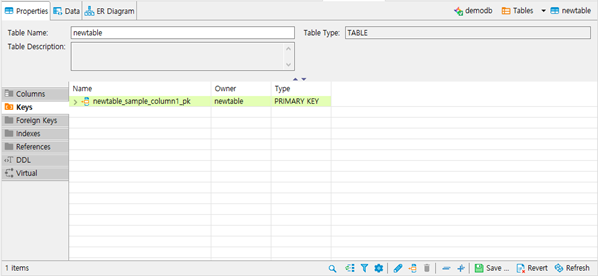
- Key를 추가하면 위와 같이 등록됩니다.
Foreign Keys
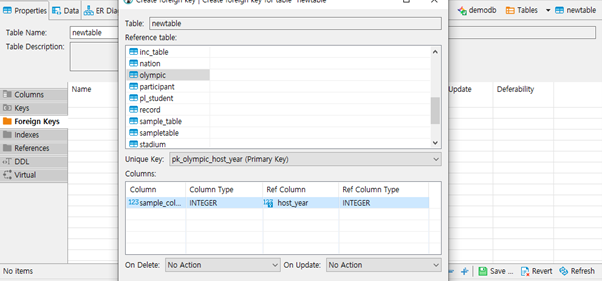
- Foreign Key를 설정합니다.
- Reference table: UK가 존재하는 테이블을 선택할 수 있습니다.
- Unique Key: 테이블의 UK를 선택합니다.
- Columns: FK를 설정할 컬럼을 지정합니다.
- ON DELETE, ON UPDATE: parent column의 변화에 대응할 방법을 선택합니다.
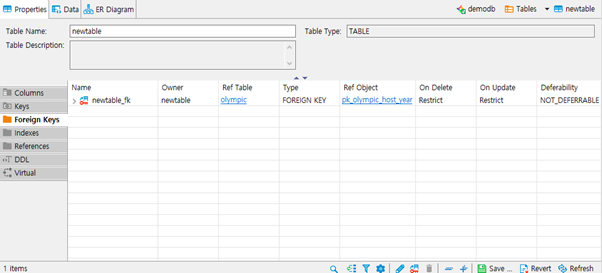
- FK를 설정하면 위와 같이 등록됩니다.
Indexes
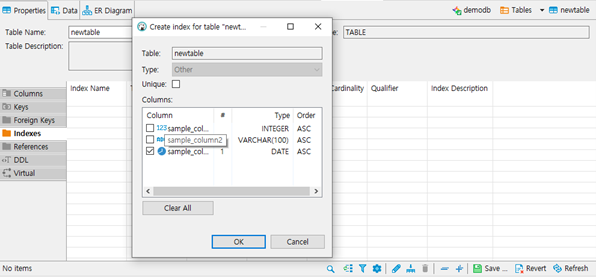
- Index를 설정합니다.
- Unique: Unique Index로 설정할 것인지 결정합니다.
- Columns: Index를 설정할 column을 지정합니다.
- Order에서 오름차순, 내림차순을 선택할 수 있습니다.
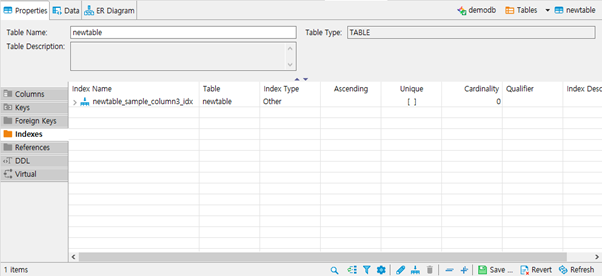
- Index를 설정하면 위와 같이 등록됩니다.
실행
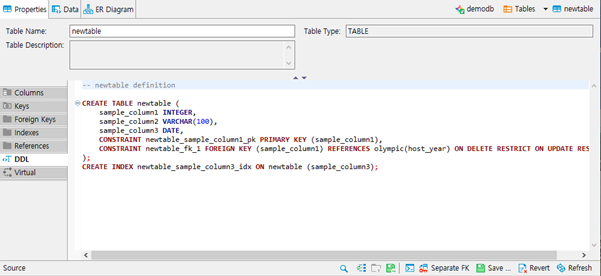
- DDL 항목에서는 테이블 생성시에 실행될 SQL문을 확인할 수 있습니다.
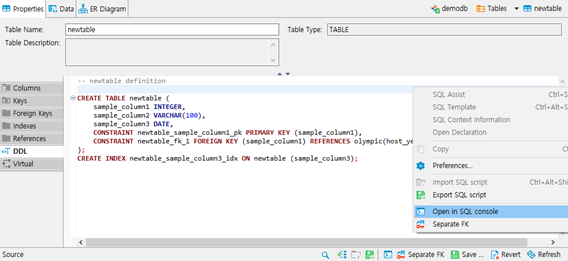
- 우클릭 -> Open in SQL console을 통해 에디터에서 query를 수정할 수 있습니다.
- 우측 하단의 save를 통해 query를 실행할 수 있습니다.
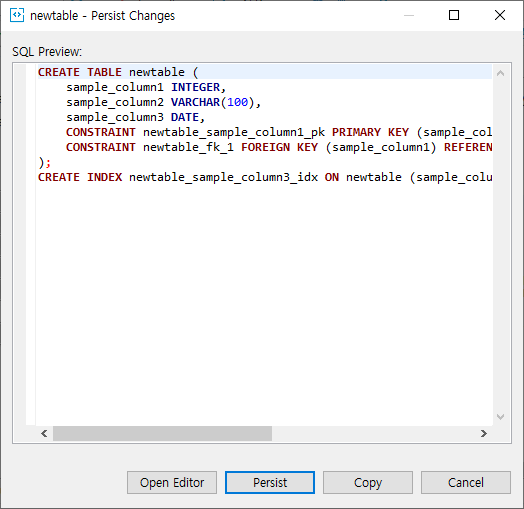
- 최종적으로 query를 실행하기 전에 마지막으로 확인할 수 있습니다. 문제가 없다면 persist를 눌러 실행시킬 수 있습니다.
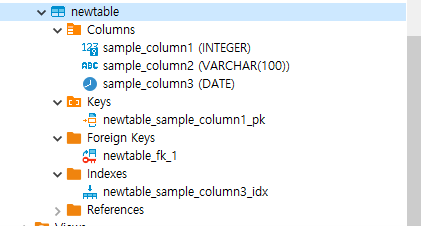
- Navigator에서 생성한 테이블 정보를 확인할 수 있습니다.
이미 생성된 테이블의 컬럼을 수정하는 법
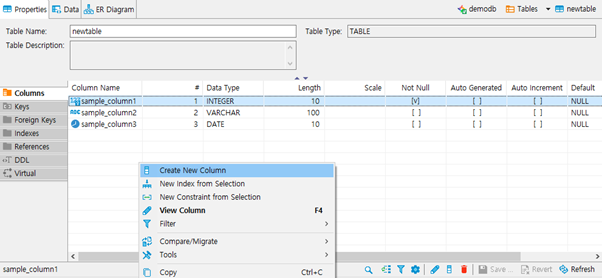
- 생성된 테이블의 columns항목을 우클릭 한 후 Create New Column을 선택하여 새로운 컬럼을 추가할 수 있습니다.
 CUBRID DBLink
CUBRID DBLink
 [CUBRID INSIDE] 부질의와 QUERY REWRITER (view merging, subque...
[CUBRID INSIDE] 부질의와 QUERY REWRITER (view merging, subque...







