
- 부질의란?
질의가 질의안에서 다시 작성되는 것을 부질의라고 합니다. 이러한 부질의 덕분에 우리는 더 쉽게 하나의 질의로 원하는 데이터를 추출할 수 있습니다. 예를 들면 작년 평균 연봉보다 높은 직원을 추출해야 한다면 아래와 같이 부질의를 사용할 수 있습니다.

평균연봉을 구해서 다시 질의를 하지 않고 위와 같이 하나의 질의로 작성이 가능합니다. 너무 당연한 질의의 사용 방법이지만 사용이 불가했다면 많이 불편했겠죠. 이러한 부질의는 특별한 성질을 가지는 데 어느 부분에 작성되느냐에 따라서 가지는 성질이 달라집니다.

- scalar subquery : SELECT 절의 부질의. 한 개의 데이터만 조회 가능.
- inline view : FROM 절의 부질의. 여러 개의 데이터 조회 가능.
- subquery : WHERE 절의 부질의. 연산자에 따라 scalar subquery 혹은 inline view의 성질.
부질의 사용은 질의를 더 다양하게 작성할 수 있도록 하지만 반대로 질의 성능에 악영향을 줄 수 있습니다.
- 부질의 실행 순서와 성능 저하 원인
부질의는 주질의보다 항상 먼저 수행되어 임시 결과를 저장해놓습니다. 그리고 주질의가 수행되면서 부질의의 임시 저장된 데이터를 조회하여 원하는 결과를 얻습니다.
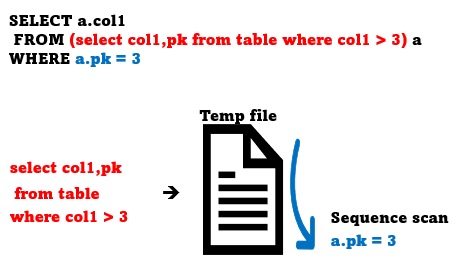
부질의부터 수행하여 결과를 임시저장소에 저장하고, 그것에서 'a.pk = 3' 조건을 체크하여 최종 결과를 추출합니다. 부질의의 결과가 많아질수록 쓸데없는 데이터를 중간에 저장하게 될 것입니다. 또한 중간에 저장한 임시데이터에서 조회하므로 인덱스를 사용하지 못합니다. 매우 비효율적인 조회 과정이 될 것입니다. 그렇다면 DBMS는 위와 같은 질의를 그대로 실행하고 있을까요? 아닙니다.
- VIEW MERGE
in-line view를 제거하고 주질의에 합병하는 것을 view merge라고 합니다.
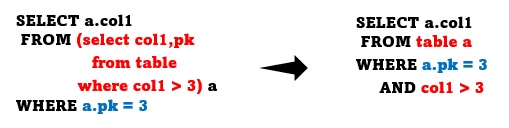
view merge가 되면서 임시 데이터를 저장할 필요가 없어졌으며, pk에 대한 인덱스 스캔을 할 수 있게 되었습니다. 사용자가 부질의를 어떻게 작성하더라도 주질의와 합병이 가능하다면 DBMS는 합병을 진행합니다. 이러한 뷰의 합병은 OPTIMIZER 단계에 가기 전에 실행순서의 제약을 제거하는 역할을 합니다. 모든 테이블을 동일한 수준에 놓고 가장 최적의 실행계획을 찾는 것입니다.
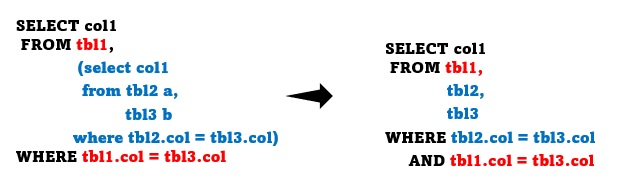
위와 같은 질의의 경우 뷰의 합병 이전에는 부질의 안의 tbl2와 tbl3의 조인이 항상 같이 진행됩니다. 예를 들면 tbl3->tbl1->tbl2과 같은 조인순서가 불가능합니다. 뷰의 합병은 결국 실행 순서의 제약사항을 제거하고 OPTIMIZER에서 최적의 실행계획을 찾도록 하는 데 목적이 있습니다.
CUBRID는 11.2버전부터 in-line view를 포함한 view merge를 지원합니다. 이전 버전에서는 view 객체에 대해서만 뷰 합병이 이루어 졌는데, 11.2버전부터 해당 기능이 확장되었습니다.
- SUBQUERY UNNEST
WHERE절의 subquery에 적용되는 재작성 기법입니다. 대표적으로 IN과 EXISTS 연산자를 대상으로 합니다.

위 질의는 어떻게 수행될까요? CUBRID에서는 IN 연산자의 경우 부질의의 결과값으로 주질의의 데이터를 추출합니다. 테이블 조인 순서로 생각한다면 tbl2 ==> tbl1 순서입니다. 그렇다면 다른 연산자일 때는 어떻게 될까요?

EXISTS 연산자일 때는 반대입니다. 조인순서로 나타낸다면 tbl1 ==> tbl2 순서입니다. 질의를 어떻게 작성하냐에 따라서 수행순서의 제약이 생기는 상황입니다. 부질의와 주질의 데이터양에 따라서 IN 연산자가 유리할 수도 있고, EXISTS가 유리할 수도 있습니다. 이러한 상황을 극복하는 것이 SUBQUERY UNNEST 기법입니다.

위와 같이 조인으로 변환되어 있다면 OPTIMIZER는 어느 테이블을 먼저 조회할지 선택할 수 있습니다. WHERE 절의 부질의를 조인으로 재작성하는 것을 SUBQUERY UNNEST라고 합니다. 한가지 특이 사항은 IN과 EXISTS 연산자는 부질의 결과의 중복데이터가 있어도 주질의 결과에 영향을 주어서는 안 됩니다. 그러한 이유로 일반 조인이 아니고 semi 조인을 진행하게 됩니다. semi 조인은 최초 데이터 발견 시 검색을 멈추고 다음 검색을 이어서 진행합니다. semi 조인은 IN과 같은 연산자와 동일한 결과를 얻기 위해 사용하는 조인 방법입니다.
CUBRID는 아직 SUBQUERY UNNEST를 지원하지 않습니다. 상황에 맞게 IN, EXISTS 연산자를 사용하는 것이 좋겠습니다.
DBMS는 질의를 재작성함으로써 질의에 내포된 수행순서의 제약사항을 제거합니다. OUTER JOIN을 INNER JOIN으로 변환하거나, 불필요한 테이블 혹은 조회 항목을 삭제하는 것 역시 동일한 목적입니다. 최대한 수행순서의 제약이 없는 상황에서 OPTIMIZER가 최적의 실행계획을 만들 수 있을 것입니다. 그리고 그것은 결국 질의의 성능을 올리고 DBMS 사용자가 원하는 데이터를 빠르게 얻을 수 있게 할 것입니다.
가끔 질의의 실행계획을 확인할 때 질의와 전혀 다르게 나타나 당황할 때가 있는데, 질의 재작성 기법을 이해하고 있다면 많은 도움이 될 것입니다. CUBRID 개발팀은 이러한 질의 재작성과 OPTIMIZER 개선작업을 진행하고 있습니다. 다음에는 OPTIMIZER가 최적의 실행계획을 찾기 위해서 어떤 일들을 하고 있는지에 관해서 이야기해보겠습니다.
 DBeaver Database Tool 큐브리드 사용하기 2
DBeaver Database Tool 큐브리드 사용하기 2







