
CUBRID는 open source DBMS입니다. 소스 코드가 공개되어 있어 언제든지 확인하고 기여할 수 있습니다. 많은 사람이 CUBRID의 contributor가 되길 바라봅니다.
Query Process란?
Query Process는 DBMS의 입력값인 SQL을 낮은 수준의 명령으로 변환하고 그것을 실행하는 전체 작업을 말합니다.
SQL에서 가장 먼저 진행되어야 하는 것은 TEXT로 작성된 SQL을 parse tree 구조로 만드는 것입니다. 이 작업은 PARSER에서 진행되는데, CUBRID는 PT_NODE 구조체를 반복적으로 사용하여 SQL을 parse tree로 변환합니다. 이 단계에서 syntax check가 진행되고 오타나 잘못된 예약어 등을 체크합니다. 그리고 SEMANTIC CHECK를 진행하는데, 여기서 작성된 테이블명이나 칼럼명 등이 존재하는 것인지 체크합니다.
다음으로 OPTIMIZER가 parse tree를 최적화하고 PLAN을 생성합니다. parse tree를 최적화하는 것을 QUERY REWRITE 혹은 TRANSFORMATION이라고 합니다. 좋은 성능을 위해 SQL을 다시 작성한다고 생각하면 됩니다. 동일한 데이터를 조회하는 SQL은 다양한 형태로 작성될 수 있습니다. 그렇기 때문에 가장 효과적인 방안으로 변환을 하는 것입니다. 여러 재작성 방법이 있는데 조회조건을 sub-query 안으로 넣어주는 predicate push등이 이에 해당합니다. 다음은 PLAN을 생성하는 것입니다. PLAN에는 어떻게 DATA를 조회할 것인가에 대한 정보가 있습니다. SQL은 어떤 데이터를 조회할 것인지에 대해서만 명시되어 있기 때문에 실제 데이터를 조회하기 위해서 이 단계가 필요합니다(이 단계 때문에 개발자가 어떻게 DATA를 조회할지에 대한 정보를 알지 못해도 됩니다). 여기서 어떻게 조회하는가에 대한 정보는 JOIN 테이블의 SCAN 순서, JOIN METHOD, SCAN METHOD등의 정보를 말합니다. 해당 정보가 PLAN 저장됩니다.
XASL generator에서 PLAN과 parse tree의 정보를 종합하여 실행계획 정보를 생성하는데 이것은 EXECUTOR에서 바로 실행이 가능한 형태입니다. CUBRID는 이것을 eXtensional Access Specification Language(XASL) 형태로 저장합니다. XASL에는 어떻게, 어떤 데이터를 조회할지 명시되어 있습니다.
마지막으로 EXECUTOR에서 XASL을 해석하여 heap_next(), index_scan_next()등의 operation을 실행합니다. 이것들은 데이터를 조회하거나 저장하는 낮은 레벨의 명령입니다. 이로써 Query Process가 완료되었고 DBMS 사용자는 원하는 데이터를 얻게 되었습니다. 지금까지 내용을 요약하면 아래 그림과 같습니다.
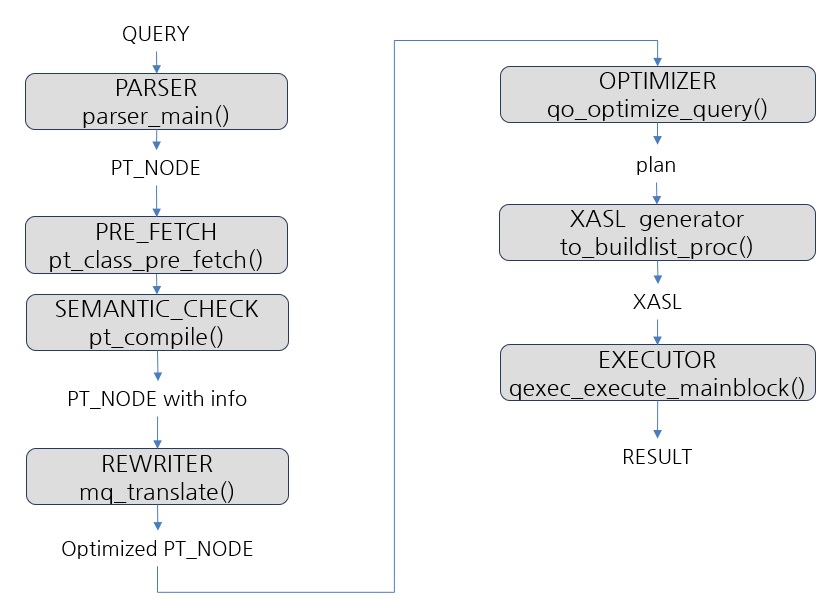
CUBRID의 query Process를 간략하게 나타낸 것이며, 각 회색 박스 안에 두 번째 줄에 적힌 함수가 각 단계의 시작지점이므로 참고하기 바랍니다. Query Process의 작업을 요약하면 아래와 같습니다.
PARSER
parser는 text인 SQL을 parsing 하여 parse tree를 생성합니다. 오픈소스 'BISON'을 사용하며, PT_NODE 구조체를 반복 사용하여 tree를 구성합니다. 아래는 간단한 SQL에 대해 parser가 parse tree를 생성한 예시입니다.
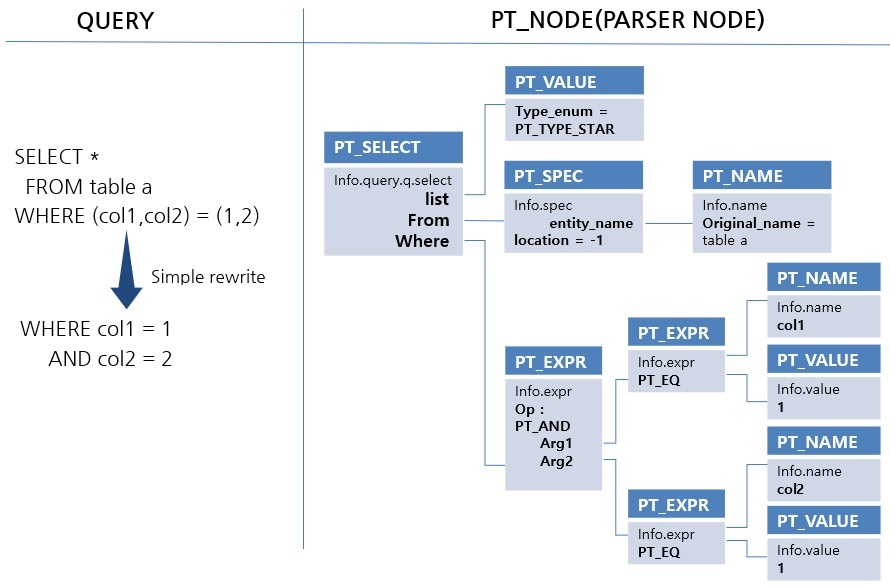
위 그림에서 하나의 BOX는 PT_NODE 구조체를 나타냅니다. 파란색 부분은 PT_NODE.node_type 이고, 하늘색 부분은 PT_NODE.info 공용체를 나타낸 것입니다. PT_NODE 구조체는 node_type에 따라 공용체인 info의 선택되는 변수가 달라집니다. 예를 들면 'PT_SELECT'는 info.query를 사용하고, 'PT_EXPR'은 info.expr을 사용합니다. 다양한 parse tree의 구조를 확인하기 위해서는 parser_main() 함수 실행 이후 결과에 대해서 PT_NODE 구조체를 확인해 봐야 하는데, text 기반인 gdb보다는 DDD(display data debuger)를 사용하는 것을 추천합니다.
parsing은 BISON을 통해 진행됩니다. BISON의 동작 원리에 대한 이해는 아래 링크를 통해 확인하기 바랍니다.
https://www.gnu.org/software/bison/manual/html_node/index.html
parse tree를 생성하는 과정에 자연스럽게 syntax check가 진행되며, 간단한 rewrite도 진행됩니다. 위 예시는 조회조건의 변경이 있었습니다. 새로운 sql 구문의 추가나 변경 시에 parser의 수정이 있어야 하는데 csql_lexer.l, csql_grammar.y 파일의 수정이 필요합니다. csql_grammar.y에서 grammar의 action 부분에는 PT_NODE를 생성하는 로직이 포함되어 있으니 관련 있는 키워드를 통해 로직을 확인하는 것이 중요합니다.
생성된 parse tree를 체크하기 위해 tree를 탐색해야 하는데 parse_walk_tree() 함수가 이를 수행합니다. pre-order와 post-order 함수를 인자에 추가 할 수 있어 tree를 탐색하며 적절한 동작을 할 수 있습니다. 또한 node_type에 따라 어느 info의 공용체가 사용되는가에 대해서는 parse_walk_tree()에서 적용되는 apply 함수를 확인하면 되는데, pt_init_apply_f() 함수에서 어떠한 apply 함수가 적용되는지 확인할 수 있습니다. 예를 들면 'PT_SELECT'의 경우 pt_init_apply_f() 함수에서 확인하면 pt_apply_select()를 사용하는 것을 알 수 있는데 해당 함수에서 info의 어느 변수를 사용하는지 확인이 가능합니다.
PRE FETCH
타 DBMS와 차이를 보이는 것은 'PRE FETCH' 단계가 있는 것입니다. 이 단계를 SEMANTIC CHECK의 한 부분으로 생각해도 되겠습니다.
CUBRID는 CAS와 CUBRID server가 분리된 3-tier 구조이기 때문에 TABLE의 스키마 정보 등 meta-data에 대한 client(CAS)와 server(CUB_SERVER)의 동기화가 필요합니다. SQL에 포함된 테이블 정보에 대해서 CAS가 cub_server에 요청하여 데이터를 받고 CAS의 work space공간에서 해당 데이터를 cache하여 사용합니다.
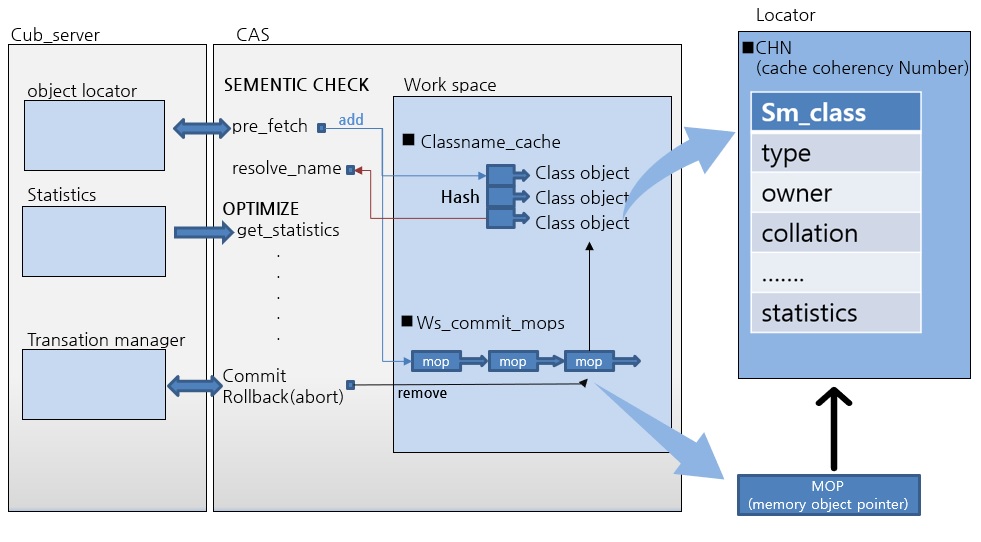
위 그림은 cub_server와 CAS 간에 meta-data를 주고받는 흐름을 나타낸 것입니다.
PRE FETCH는 CUBRID가 3-tier로 구성되어 있기 때문에 필요한 단계입니다. 분산 처리 측면에서 의미가 있는 단계입니다.
SEMANTIC CHECK
SEMANTIC CHECK 단계에서는 크게 3가지 작업을 진행합니다.
첫 번째는 테이블명등의 정보를 체크하고 관련 정보를 추가하는 것입니다. 이렇게 테이블명 혹은 칼럼명과 같이 schema정보에서 참조하는 정보는 pt_node의 node_type이 PT_NAME으로 생성됩니다. 즉 node_type이 PT_NAME인 node에 대해서 체크하고 정보를 추가하는 작업이 필요합니다. pt_resolve_names() 함수에 관련 작업을 진행합니다.
두 번째는 type을 체크하는 작업입니다. 스키마의 등록된 type과 이에 대칭되는 상수 혹은 다른 칼럼의 type이 호환 가능한지 확인하고 필요에 따라 CAST 함수를 추가해줍니다. type check에는 문자열의 charset과 collation도 포함됩니다. pt_semantic_type() 함수에서 관련 작업을 진행합니다.
세 번째는 constant fold입니다. 상수만으로 구성된 함수나 연산 등을 EXECUTOR 단계에 가기 전에 미리 처리합니다. 예를 들면 'select 1+2 from dual'에서 1+2의 연산을 미리 계산하여 3으로 변환합니다. CUBRID에서는 CAS에서 따로 수행되기 때문에 DB SERVER의 부하를 줄여주는 역할을 합니다. pt_fold_constants_post() 함수에 관련된 주요 소스 코드가 있습니다.
그 외에도 많은 체크나 변환이 포함되어 있습니다만 주요 내용을 요약하면 SEMANTIC CHECK는 스키마와 같은 meta data를 parse tree에 추가하고 그 과정에서 문제시 semantic error를 발생하는 단계입니다.
REWRITER (QUERY TRANSFORMATION)
REWRITER 단계에서는 SQL을 재작성합니다. parse tree에서 특정 패턴을 인식하고 그 구조를 변경하는 작업입니다. 주로 SQL의 성능 향상을 위한 작업입니다만, 이후 단계의 작업을 위해 변환하는 항목도 있습니다. 많은 변환 패턴이 있지만 몇 가지만 소개하겠습니다.
여기서 CNF변환과 view의 변환은 이후 작업 진행을 위해 진행되는 재작성입니다. 조회 조건을 CNF로 변환하는 것은 인덱스 스캔의 대상을 효과적으로 찾기 위함입니다. CNF는 논리곱 표준형으로 'AND'로 묶인 조회조건입니다. 아래 예시를 보면 CNF와 DNF의 차이를 확인할 수 있습니다.
CUBRID는 모든 조회 조건을 CNF로 변환하려는 시도를 하며, CNF로 변환되거나 작성된 조회조건만 인덱스 스캔의 대상이 됩니다. 이론상 모든 DNF는 CNF 변환이 가능하지만 조회조건의 개수가 늘어날 수 있는데 CUBRID는 한 개의 조회조건의 변환된 결과가 100개를 초과하면 해당 조회조건을 변환하지 않습니다.
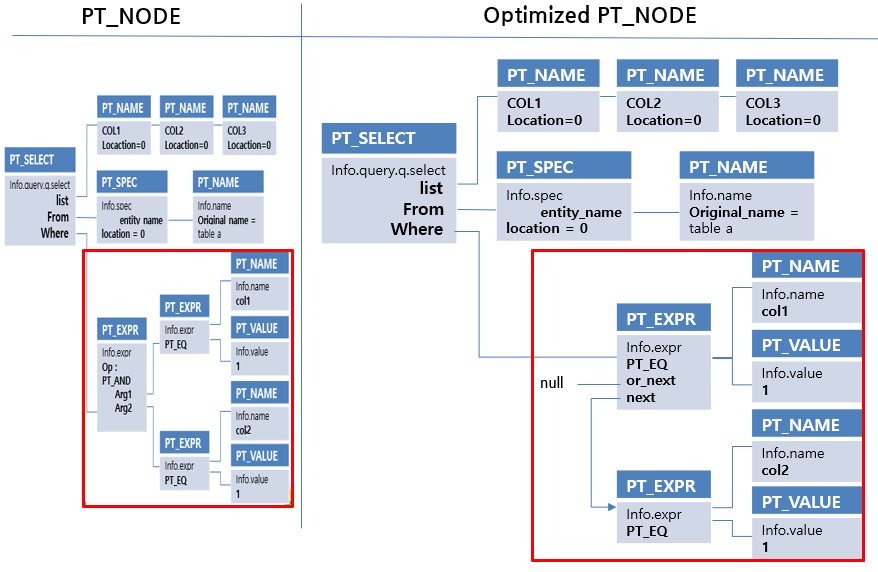
위 그림에서 빨간색 박스 부분을 보면 predicate가 CNF 변환이 적용된 것을 볼 수 있습니다. 위 그림의 predicate는 'col1=1 and col2=1' 으로 그 자체로 CNF이므로 predicate의 자체는 변경되지 않았지만, 'AND','OR'와 같은 logical operation의 변경이 있었습니다. parser에서는 logical operation을 하나의 PT_NODE로 표현했지만, 변환된 이후에는 next(AND)와 or_next(OR) 포인터를 사용하는 구조로 변경되었습니다. 이러한 구조로 변경되었기 때문에 이후 predicate 검색은 아래와 같이 수행됩니다. 'PT_AND'와 'PT_OR' operation을 가지는 predicate는 cnf 변환이 안 된 것입니다.
이 이외에도 다양한 재작성이 진행됩니다. qo_optimize_queries() 함수에 대부분의 재작성 소스 코드가 작성되어있습니다. 해당 함수의 진행 이전과 이후의 tree를 비교하여 어떠한 재작성이 진행되었는지 확인 할 수 있습니다. 또한 plan 정보에서 재작성된 SQL을 text 형태로 확인 할 수 있습니다.
OPTIMIZER
OPTIMIZER는 어떻게 DATA를 검색하는 것이 최적인지 예측하고 그 정보를 PLAN에 저장합니다. 관련 정보는 크게 3가지입니다. 첫째는 한 테이블에 대한 access method입니다. index scan, heap scan 등이 이에 해당합니다. 두 번째는 테이블의 join 순서입니다. 그리고 세 번째는 join method입니다. Nested loop join이나 sort merge join이 이에 해당합니다. 이러한 정보를 얻기 위해서 모든 가능한 plan의 cost를 측정하고 가장 낮은 cost를 갖는 PLAN을 결정합니다. 이를 위해 parse tree를 query graph 형태로 저장하게 되는데 아래에 매칭되는 주요 용어를 간단하게 정리하였습니다.
cost의 계산은 칼럼의 1 / Number of Distinct Value(NDV) 을 선택도(selectivity)로 사용합니다. 모든 데이터가 고르게 분포되어 있다고 가정하고 데이터 조회 이전에 몇 개의 행이 조회될지 예측하는 것입니다. 상대적으로 적은 행을 가지는 테이블을 먼저 조회하는 것이 유리할 가능성이 높습니다. 먼저 term(predicate)에 대해서 cost를 계산 및 인덱스 스캔이 가능 여부 등을 체크합니다. 관련 함수는 qo_analyze_term()입니다. term에 대한 분석이 완료되면 node(table)들을 순회하며 생성될 수 있는 모든 경우의 plan의 cost를 비교하고 그중 가장 최적의 plan을 결정합니다. planner_permutate()에서 그 작업을 진행합니다.
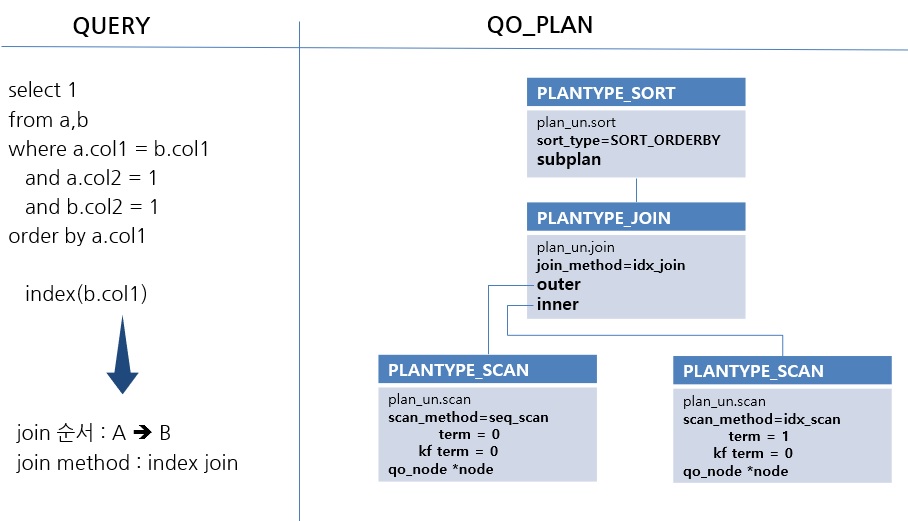
위 그림은 join 순서가 A->B이고, index join method가 선택되었을 때 plan 객체를 나타낸 것입니다. 한 박스는 QO_PLAN 객체이고 파란색 부분이 plan_type, 그 밑의 부분이 공용체인 plan_un 정보입니다. parser의 PT_NODE와 비슷하게 plan_type에 따라 공용체 plan_un의 정보가 달라지는 구조입니다.
PLANTYPE_SCAN에는 각 테이블의 scan_method와 인덱스 관련 term이 저장됩니다. term(조회조건)은 인덱스 스캔 가능 여부에 따라 key range, key filter, data filter로 나눌 수 있습니다. 이것이 각각 term, kf term, sarg term에 저장됩니다. PLANTYPE_JOIN에는 outer와 inner 테이블 정보 및 join method 정보가 포함되어 있습니다. 그리고 마지막으로 PLANTYPE_SORT에 order by 절 관련된 내용이 생성됩니다.
XASL GENERATOR
XASL은 eXtensional Access Specification Language의 약자입니다. CUBRID는 EXECUTOR에서 이 XASL을 해석하여 원하는 데이터를 얻습니다. 접근 사양이라는 것은 어떻게 그리고 어떤 데이터를 접근할 것인가에 대한 정보이고, 이것은 OPTIMIZER에서 생성된 PLAN과 parse tree에 저장되어 있습니다. 이 두 가지 정보를 종합하여 XASL 형태로 저장합니다. XASL generator를 OPTIMIZER 단계의 부분으로 생각해도 무리는 없을 것 같습니다.
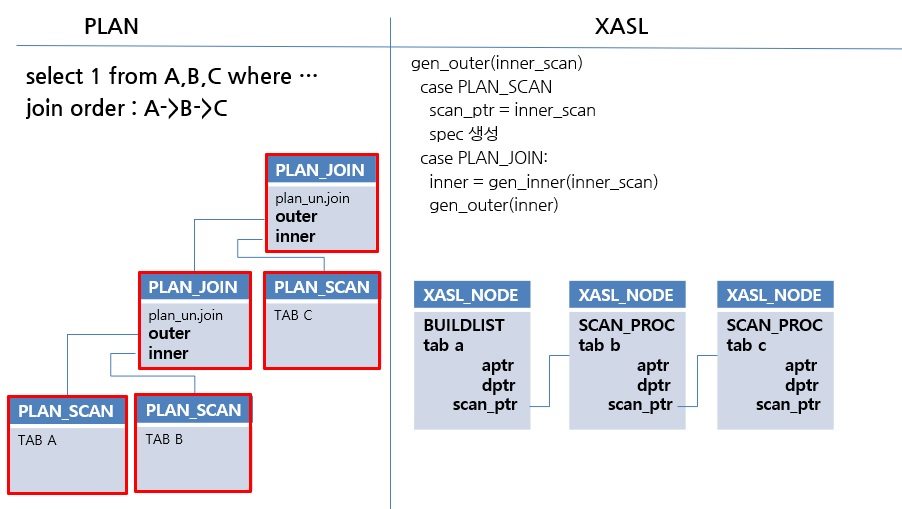
위 그림은 JOIN 순서가 A->B->C일 때 생성된 PLAN을 가지고 XASL_NODE가 생성되는 모습을 나타낸 것입니다. 한 개의 XASL_NODE는 한 개의 access spec을 가지고 이는 한 개의 테이블 조회에 대한 정보를 담는다고 생각하는 것이 이해가 쉬울 것 같습니다. 물론 partition table 같은 경우 한 개의 XASL_NODE 여러 개의 access spec을 가질 수 있습니다. 일반적으로 SQL에서 table이 존재할 수 있는 위치는 FROM절 입니다. 이것은 join 형태로 작성될 수도 있고, sub query로 작성될 수 있습니다. 위 그림에서는 join으로 연결되어 있으며 이것이 scan_ptr로 연결된 것을 확인 할 수 있습니다. 이러한 XASL_NODE를 연결하는 주요 포인터는 아래와 같습니다.
correlated sub query는 외부에 참조하는 칼럼이 있는 것이며, uncorrelated sub query는 외부 참조 칼럼이 없는 것을 뜻합니다.
SELECT 1
FROM TBL1 A
,(SELECT * FROM TBL2 WHERE COL1 = A.COL1) B
,(SELECT * FROM TBL3 WHERE COL1 = 3) C
위에서 B는 correlated sub query이고, C는 uncorrelated sub query입니다. sub query를 구분한 이유는 correlated sub query의 경우 참조되는 데이터가 먼저 조회돼야 하므로 scan의 순서가 정해집니다. 반면에 correlated sub query는 그런 순서의 제약이 없어 가장 먼저 scan을 진행 할 수 있습니다. 위 그림은 join만 존재 하기 때문에 scan_ptr만 사용되었는데, sub query가 사용되면 그 성격에 따라 aptr과 dptr로 XASL node가 연결됩니다. 대부분의 SQL이 3가지 pointer로 XASL_NODE를 연결하는 것으로 표현이 가능합니다.
EXECUTOR
XASL을 해석하여 data를 조회하거나, 저장, 변경하는 단계입니다. Volcano model (Iterator Model)로 구현되어 있는데, 이는 데이터를 조회하는 데 있어 연관된 join, sub query, predicate의 평가를 진행하여 하나의 행을 확정하고 다음 행의 조회를 이어서 수행하는 구조입니다. qexec_execute_mainblock()함수가 이 단계의 시작 지점입니다.
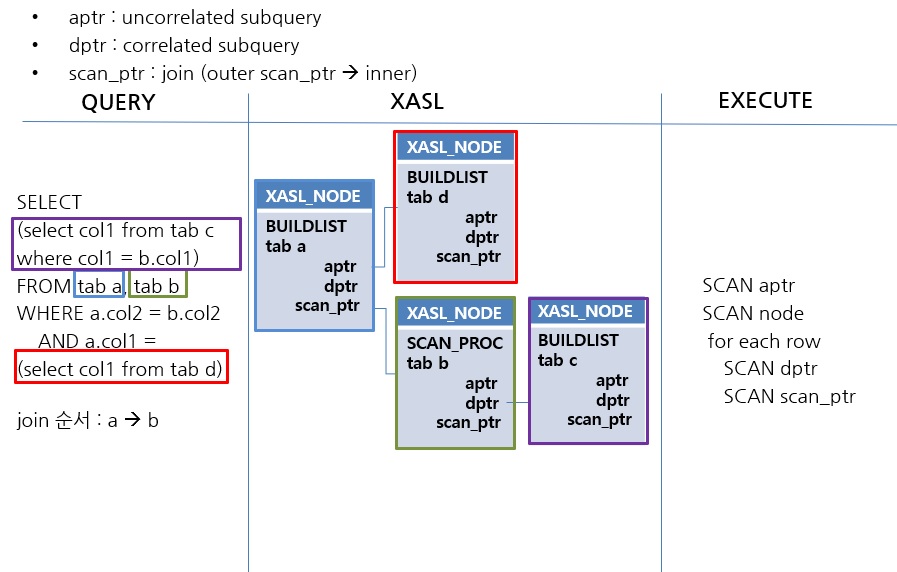
위 그림은 SQL에서 XASL이 생성되고 이를 실행하는 순서를 나타낸 것입니다. 아래와 같은 순서로 scan이 진행됩니다.
1) join의 순서가 첫 번째인 tab a의 XASL node가 시작 node가 된다.
2) tab a node의 aptr인 빨간색 박스의 node가 먼저 scan 되어 결과를 temp file에 저장한다.
3) tab a node에 대한 scan이 진행되고 1row 조회한다.
4) join 관계인 tab b node에 대해서 위 단계에서 1row 조회된 데이터를 사용하여 scan을 진행한다.
5) 이전 조회 결과set을 사용하여 dptr인 tab c node를 scan한다.
6) 지금까지 조회된 1row의 대한 결과를 temp file에 저장한다.
7) (3)단계로 이동하여 새로운 1row를 조회하고 전체 row가 조회될 때까지 반복한다.
aptr과 dptr과 같은 sub-query pointer는 독립적인 XASL_NODE입니다. 그래서 시작지점과 동일한 qexec_execute_mainblock() 함수를 호출합니다. 이에 반해 join은 main block과 연결되어 여러 테이블의 스캔을 같이 수행하여 하나의 행을 생성합니다. 호출되는 함수는 qexec_execute_scan()입니다. 하나의 행이 결정되어 저장되는 것은 qexec_end_one_iteration() 함수에서 진행됩니다.
지금까지 CUBRID의 Query Process에 대해서 개괄적으로 설명하였습니다. 다음에는 조금 더 자세히 각 단계의 상세 내용에 관해서 이야기해보겠습니다.
 ANTLR, StringTemplate를 사용해서 PL/SQL을 CUBRID Java SP로 변...
ANTLR, StringTemplate를 사용해서 PL/SQL을 CUBRID Java SP로 변...









