
CUBRID 11버전에 "TDE(Transparent Data Encryption)"가 추가되었습니다!
2021년 1월 출시된 CUBRID11에 TDE가 생김으로써 보안이 한층 강화되었는데요, TDE란 무엇일까요?!
이를 통해 사용자는 애플리케이션의 변경을 거의 하지 않고 디스크에 저장되는 데이터를 암호화할 수 있습니다.
어떤 해커가 한 조직을 해킹했을 때, 훔쳐가고 싶은 것 1위는 당연히 데이터베이스 내에 있는 중요한 데이터일 것입니다.
또는 회사 내부의 악의적인 의도를 가진 직원이 데이터베이스에 로그인하고 USB와 같은 저장매체에 모든 데이터를 옮겨가는 상황이 있을 수도 있습니다.
이러한 상황들에서 데이터를 보호할 수 있는 가장 쉬운 방법은 데이터베이스를 암호화하는 것인데요, 암호화 기술 중 데이터베이스 파일 자체를 암호화하는 기술인 TDE가 좋은 선택이 되겠죠?!
암호화된 데이터베이스는 키가 없으면 접근할 수 없기 때문에, 이 키 파일을 함께 가지고 있지 않다면 도난당한 파일은 쓸모없는 더미 파일이 될테니까요.
- AES : 미국 표준 기술 연구소 (NIST)에 의해 제정된 암호화 알고리즘
- ARIA : 한국 인터넷 진흥원 (KISA)에서 채택한 표준 암호화 알고리즘
TDE에 사용되는 키는 마스터 키와 데이터 키가 있습니다.
사용자가 관리하는 마스터 키는 별도의 파일에 저장되며, 큐브리드는 이를 관리할 수 있는 도구를 제공합니다.
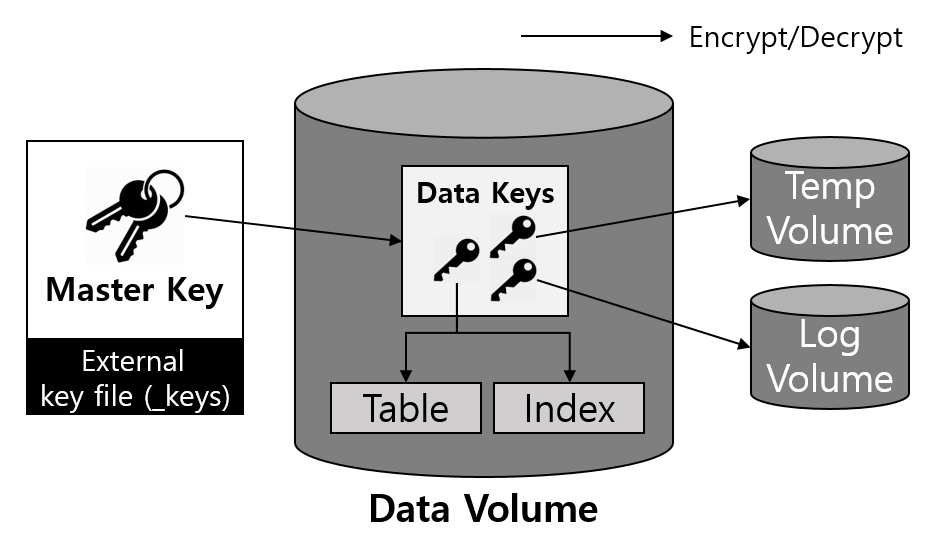
데이터 키: 실제 테이블 및 로그 등의 유저 데이터를 암호화할 때 사용되는 키로, 큐브리드 엔진이 데이터베이스 내부에서 사용하는 키
이렇게 2계층으로 키를 관리하는 이유는 키 변경 오퍼레이션을 보다 효율적으로 할 수 있기 때문인데요
만약 실제 데이터를 암호화하는 키만 존재한다면, 키를 변경할 경우에 모든 데이터를 다시 읽어 들여 복호화 및 재암호화하는 과정을 거쳐야 하기 때문에 작업 시간이 오래걸리고 그 과정동안 데이터베이스의 전체적인 성능 저하를 가져올 수 있습니다.
CUBRID의 TDE는 어떤 것들을 암/복호화 할까요?

- 암호화된 테이블의 데이터와 모든 인덱스의 데이터가 암호화됩니다.
- 암호화 테이블과 관련된 질의 수행중 생성되는 임시 데이터가 암호화됩니다.
2. 트랜잭션 로그
- 암호화 테이블과 관련된 모든 로그 정보를 암호화합니다.
- 활성 로그와 보관 로그 모두 적용됩니다.
3. 백업 볼륨
- 데이터 볼륨과 로그 볼륨에 암호화된 테이블이 있는 경우 백업 볼륨에도 암호화된 상태로 저장됩니다.
4. DWB(Double Write Buffer)
- 영구 데이터는 데이터 볼륨에 쓰이기 전에 DWB(이중 쓰기 버퍼)에 일시적으로 쓰여지는데, 이는 암호화된 테이블에 대한 데이터를 포함할 수 있기 때문에 DWB 파일 또한 암호화됩니다.
그럼 TDE 사용시 유의사항에 대해 알아보겠습니다.
$ cubrid createdb testdb ko_KR.utf8
Creating database with 512.0M size using locale ko_KR.utf8. The total amount of disk space needed is 1.5G.
CUBRID 11.0
$ ll
합계 1050348
drwxrwxr-x. 2 cubrid11 cubrid11 6 4월 30 16:01 lob
-rw-------. 1 cubrid11 cubrid11 536870912 4월 30 16:01 testdb
-rw-------. 1 cubrid11 cubrid11 65 4월 30 16:01 testdb_keys
-rw-------. 1 cubrid11 cubrid11 536870912 4월 30 16:01 testdb_lgar_t
-rw-------. 1 cubrid11 cubrid11 536870912 4월 30 16:01 testdb_lgat
-rw-------. 1 cubrid11 cubrid11 214 4월 30 16:01 testdb_lginf
-rw-------. 1 cubrid11 cubrid11 278 4월 30 16:01 testdb_vinf
- tde_keys_file_path
키 파일의 경로를 설정합니다.
키 파일의 이름은 [database_name]_keys 로 고정되어 있고, 해당 키 파일이 존재하는 디렉토리를 지정합니다.
이 값이 설정되지 않았을 경우에는 데이터베이스 볼륨과 같은 위치에서 키 파일을 찾습니다.
키 파일 경로 변경 시, 이 설정값은 동적변경이 되지 않으므로 서비스를 재기동해야합니다. 이 때, 키 파일만 옮겨두고 키 파일의 경로는 수정하지 않으면 암호화 테이블에 접근 시(DDL, DML) TDE 모듈을 로드하지 못했다는 에러가 발생합니다.
- tde_default_algorithm
TDE 암호화 테이블 생성 시에 사용하는 기본 알고리즘을 설정합니다.
로그 및 임시 데이터는 항상 이 값으로 설정된 알고리즘을 이용하여 암호화됩니다.
3. 키 파일이 삭제되었을 경우
데이터 베이스가 구동되어 있는 경우, 마스터 키의 내용을 메모리에 로딩해놓고 서비스하기 때문에 마스터 키 파일이 삭제되어도 서비스에 문제가 없습니다.
그러나 재기동될 때 설정값을 다시 읽어들이기 때문에 문제가 될 수 있습니다.
csql> SELECT * FROM tbl_tde;
In the command from line 1,
ERROR: TDE Module is not loaded.
* HA 환경
HA 환경에서는 각각의 노드(master/slave/replica)마다 키 파일 및 TDE 관련 설정이 개별적으로 적용됩니다.
그러나 암호화된 데이터는 master/slave 상호간 복제되므로 설정값을 다르게 하거나 파일을 지우면 복제가 정상적으로 수행되지 않습니다. 따라서 설정이나 키 파일은 동일하게 유지하여야 합니다.
* 백업 시 TDE
1. 백업 키 파일
$ **cubrid backupdb --separate-keys -D . testdb@localhost**
Backup Volume Label: Level: 0, Unit: 0, Database testdb, Backup Time: Wed May 5 23:18:38 2021
$ ll
-rw-------. 1 cubrid11 cubrid11 65 5월 5 23:18 testdb_bk0_keys
-rw-------. 1 cubrid11 cubrid11 1614820352 5월 5 23:18 testdb_bk0v000
백업 볼륨에는 기본적으로 키 파일이 포함되는데 --separate-keys 옵션을 통해 키를 분리하여 백업할 수 있습니다.
분리된 백업 키 파일은 백업 볼륨과 같은 경로에 생성되며 <database_name>_bk<backup_level>_keys 라는 이름을 가집니다.
하지만, 이렇게 키 파일을 분리한 경우에는 복구를 위해 키 파일을 분실하지 않게 관리해야 합니다.
2. 백업 복구 시 키 파일 선택
백업 복구 시 키 파일이 필요하며, 키 파일은 다음의 순서로 찾아집니다.
- 백업 복구 시 키 파일 탐색 순서
- 백업 볼륨이 포함하고 있는 백업 키 파일
- 백업 시에 --separate-keys 옵션으로 생성된 백업 키 파일 (e.g. testdb_bk0_keys). 이 키 파일은 백업 볼륨과 같은 위치에 존재해야 합니다.
- 시스템 파라미터 tde-keys-file-path 로 지정된 경로에 있는 서버 키 파일
- 데이터 볼륨과 같은 위치에 있는 서버 키 파일 (e.g. testdb_keys)
--keys-file-path 옵션을 통해 복구에 사용할 키 파일로 지정해 줄 수 있으며, 해당 경로에 키 파일이 없는 경우 에러가 발생합니다.
백업 키 파일: 백업 시에 생성된 키 파일로 백업 볼륨 내에 포함되어 있거나, --separate-keys로 분리된 키 파일
3. 올바른 키 파일을 찾지 못하더라도 백업 볼륨에 암호화된 데이터가 전혀 없다면 복구에 성공할 수 있습니다.
하지만, 키 파일이 존재하지 않으므로 이후에 TDE 기능을 사용할 수 없습니다.
4. 기본적으로 백업 키 파일을 분실한 경우에는 백업 복구를 수행할 수 없습니다.
그러나 키를 변경하지 않은 경우, 이전 볼륨의 백업 키 파일을 --keys-file-path 옵션으로 지정하여 복구가 가능합니다.
또한, 기본 경로에 이전 볼륨의 백업 키가 존재한다면 백업 복구에 사용할 수 있습니다.
5. 증분 백업의 경우 여러 백업 볼륨을 사용해 백업 복구를 수행하면 --level 옵션으로 지정하는 레벨의 백업 키 파일을 사용합니다.
--level 옵션을 지정해주지 않을 경우에는 가장 높은 레벨의 백업 키 파일을 사용합니다.
사용하는 키 파일만 존재하면 복구가 가능합니다.
* TDE 기능을 사용할 수 없을 때의 동작
다음과 같은 경우에는 TDE 기능을 사용할 수 없고, TDE 모듈이 올바르게 로드되지 않았다고 오류를 발생합니다.
- 올바른 키 파일을 찾을 수 없을 때
- 키 파일 내에 데이터베이스에 등록된 키를 찾을 수 없을 때
위와 같은 상황에서도 서버는 정상 구동되며 암호화되지 않은 테이블에 대해서는 접근할 수 있습니다. 그러나 암호화된 테이블에 대해서는 접근할 수 없습니다.
또한 암호화된 로그데이터를 읽어들이지 못하므로 리커버리, HA, VACCUM 등 로그 데이터를 필요로하는 프로세스가 작동될 시 시스템이 올바르게 수행될 수 없어 서버 전체가 동작을 정지합니다.
* 제약 사항
- HA 구성 시 복제 로그는 암호화되지 않습니다.
- ALTER TABLE 구문을 통한 암호화 알고리즘 변경 및 해제를 제공하지 않습니다. 기존 암호화된 테이블의 암호화 알고리즘을 변경 - 또는 해제하고 싶은 경우, 새로운 테이블로 데이터를 이동시키는 작업이 필요합니다.
- SQL 로그에 찍히는 데이터는 암호화되지 않습니다.
그렇다면 CUBRID TDE기능 외에 어떤 보안 기능이 있을까요?
SSL
- 인터넷 상에 전송중인 데이터를 누군가 가로채는 행위인 스니핑(sniffing)을 방지하기 위해 큐브리드는 패킷 암호화를 제공합니다.
- 전송될 데이터에 대해 패킷이 암호화되어 전송되는데, 이 패킷 암호화에 SSL/TLS 프로토콜을 사용합니다.
자세한 내용은 큐브리드 블로그에서 확인하실 수 있습니다.
ACL
- 허용되지 않은 IP 목록과 DB 사용자가 해당 브로커나 데이터베이스 서버로 접속하는 것을 제한하기 위해 접근 권한(Access Control)이라는 기능을 사용하는데요, 외부의 잘못된 접근으로 인하여 발생하는 문제로부터 데이터베이스를 보호할 수 있습니다.
자세한 내용은 큐브리드 블로그에서 확인하실 수 있습니다.
Audit Log
- 개발자 또는 사용자의 DDL로그에 대한 감사를 위해 큐브리드는 DDL Audit Log를 제공하고있습니다.
- CAS, csql 및 loaddb를 통해 수행된 DDL을 실행된 파일의 복사본과 함께 로그 파일에 기록할 수 있습니다.
- 시스템 파라미터인 ddl_audit_log를 yes로 설정했을 시 $CUBRID/log/ddl_audit 디렉토리에 DDL Audit log가 생성됩니다.
- DDL 실행 시작 시간, 클라이언트 IP주소, 사용자 이름 등이 파일에 기록됩니다.
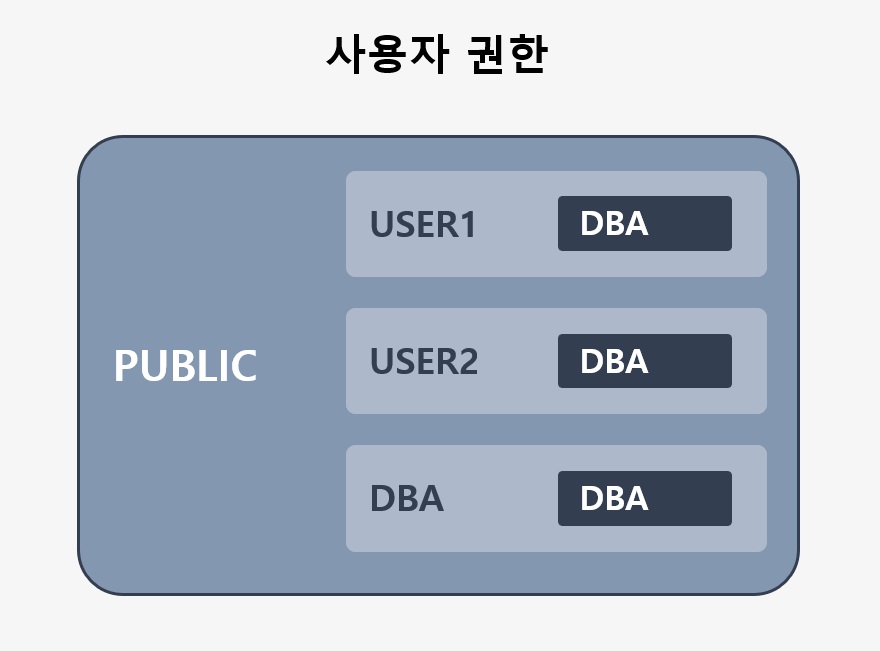
GRANT/REVOKE / 소유자
- 큐브리드에서 권한 부여의 최소 단위는 테이블입니다. GRANT/REVOKE 문을 적절히 사용하여 자신이 만든 테이블에 다른 사용자(그룹)의 접근을 허용하거나 제한할 수 있습니다.
- 모든 사용자는 PUBLIC 사용자에게 부여된 권한을 소유합니다. 즉 데이터베이스의 모든 사용자는 PUBLIC 의 멤버가 됩니다.
- 데이터베이스 관리자(DBA) 또는 DBA 그룹의 멤버는 ALTER ... OWNER문을 사용하여 테이블, 뷰, 트리거, Java 저장 함수/프로시저의소유자를 변경할 수 있습니다.
큐브리드 보안에 대한 문서는 하기 링크에서 확인하실 수 있습니다.
CUBRID 보안 - CUBRID 11.0.0 documentation
👍 CUBRID의 다양한 보안 기능을 활용하여 데이터 베이스 보안 수준을 높일 수 있습니다.
 [CUBRID inside] HASH SCAN Method
[CUBRID inside] HASH SCAN Method
 CUBRID의 개발 문화: CUBRID DBMS는 어떻게 개발되고 있을까?
CUBRID의 개발 문화: CUBRID DBMS는 어떻게 개발되고 있을까?









