
시작하며
안녕하세요, 유형규 선임연구원입니다. 이번 포스트에서는 먼저 큐브리드 프로젝트의 개발 프로세스를 소개하고, 프로세스를 개선하기 위한 노력과 개발 문화를 소개하려고 합니다. 큐브리드에 입사한 지 벌써 거의 2년 반이 흘렀습니다. 처음 입사했을 때 하나의 팀이었던 개발 조직도 어느새 대단한 동료 개발자분들이 많이 입사하면서 세 개발팀과 QA팀까지 규모가 제법 커지면서 새로 합류한 신입 동료 개발자분들도 많아졌습니다. 입사 후 첫 메이저 버전 릴리즈를 경험하면서 릴리즈 과정을 돌아보며 동료 개발자들과 큐브리드의 개발 프로세스를 조금 더 개선하게 되었습니다.
오픈소스 데이터베이스 프로젝트, CUBRID의 개발 프로세스
큐브리드는 오픈소스 프로젝트 입니다. 큐브리드는 참여, 개방, 공유의 가치를 지향하며 이를 실현하기 위해 정보의 공유와 프로세스의 투명성은 큐브리드의 개발 프로세스와 문화에 녹아있습니다.
큐브리드에 기여하는 모든 개발자는 오픈소스 프로젝트 개발 프로세스를 기반으로 개발을 진행합니다. 이 의미는 큐브리드 사내의 개발자든 큐브리드에 외부 기여자 (컨트리뷰터) 모두 동일한 과정으로 개발을 진행한다는 것입니다. 또한 개발 과정에서 만들어지는 정보 (기능 정의, 디자인 설계, 소스 구현)는 자연스럽게 개발 프로세스 과정에서 공유됩니다.
CUBRID의 모든 프로젝트, 기능 추가, 버그 수정은 다음과 같은 과정을 거쳐서 완료됩니다.

- - 커뮤니케이션 (Communication): 프로젝트, 기능 추가, 버그 수정에 대한 제안과 토론을 합니다.
- - 선별 (Triage): 세상의 모든 문제를 해결할 순 없는 것 처럼, 큐브리드에 필요한 모든 기능을 단번에 모두 개발 하거나, 모든 버그를 완벽하게 알아내고 해결할 수 없습니다. 프로젝트 메인테이너 (개발 리더)가 해결해야할 작업인지, 어떤 작업을 우선해서 먼저 시작할 지 판단합니다.
- - 개발 (Dev): 지정된 개발자가 설계 디자인, 코드 구현, 코드 리뷰를 수행합니다.
- - 검증과 테스트 (QA): 구현 결과에 대해 큐브리드 QA 시스템에서 기능, 성능 테스트를 수행합니다.
큐브리드는 위에서 설명한 개발 과정을 JIRA와 Github 협업 도구를 사용하여 CUBRID 개발 프로세스를 정의하고 운영하고 있습니다. JIRA는 소프트웨어 프로세스 관리를 도와주는 협업 도구입니다. 각각의 작업을 JIRA 이슈라는 단위로 관리할 수 있습니다. Github은 오픈소스 프로젝트를 위한 원격 저장소를 제공해주는 서비스로, 웹 상에서 Pull Request라는 기능을 통해 코드 리뷰를 수행할 수 있습니다.
JIRA

예시) http://jira.cubrid.org/browse/CBRD-23629
CUBRID의 모든 프로젝트, 기능추가, 버그수정은 JIRA 이슈 생성으로부터 시작합니다. 개발 과정에서 이슈에는 어떤 작업을 할 건지 (기능 정의), 어떻게 할 것인지 (설계 디자인) 또 어떤 과정으로 작업이 완료했는지 (상세 설계/구현)에 대한 기록이 위 그림과 같이 자연스럽게 남게됩니다
.

큐브리드 개발 프로세스와 JIRA 이슈 상태
각 JIRA 이슈에 대해 앞서 설명한 [기능 제안/토론 → 선별 → 개발 → 테스트] 과정은 위 그림과 같이 이슈의 상태를 가집니다. (OPEN, CONFIRMED, IN PROGRESS, REVIEW IN PROGRESS, REVIEWED, RESOLVED, CLOSED) 상태의 이름을 보면 각 단계에서 어떤 작업을 하고 있는지 쉽게 파악할 수 있는데, 각 상태에 따라 설계/구현 중인지, 코드 리뷰 중인지, 테스트 중인지 알 수 있습니다.
Github 코드 리뷰
코드 리뷰란 이슈를 담당한 개발자가 작성한 코드를 큐브리드에 반영하기 전에 다른 개발자가 코드를 검토하고 피드백하는 과정입니다. Github에서는 각 이슈에서 개발한 결과물에 대해 Pull Request 기능을 이용해 코드 리뷰를 수행합니다. JIRA에서 공유된 내용 (기능 스펙, 설계 디자인) 을 참고하여 큐브리드의 개발자들은 구현 로직에 대해서 더 안전하고 더 빠른 방법을 찾기 위해 토론합니다.

개발 프로세스 개선
개발 프로세스는 왜 개선하게 되었는가?
어느 날 업무를 하다가 동료들과 점심시간에 꿀 같은 낮잠을 포기하고 개발자들의 창의성이 가장 높아진다는 커피 타임 & 잡담을 가지고 있었습니다. 가장 최근에 릴리즈된 CUBRID 11 버전의 기능을 개발하면서 있었던 일, 힘들었던 이야기를 하면서요.
그러다 동료 개발자들끼리 앞서 설명한 개발 프로세스에 따라 작업을 할 때 조금씩 디테일이 차이가 난다는 것을 알게 되었습니다. 작업이 종료된 순간에는 "모로 가도 서울만 가면 된다"라는 말처럼 성공적으로 릴리즈는 했지만, 어딘가 찜찜했습니다.
그래서 동료 개발자들과 큐브리드의 개발 프로세스를 뜯어보기 시작했습니다. "이건 왜 이렇게 해야 하지? 매번 넣어주는 이 정보의 의미는 뭘까? 이 절차가 효율적일까?" 하고 서로 질문하며 Why? 를 생각해보기 시작했습니다. 많은 부분에서 대답은 "모호한 부분이 많아 개선이 필요하다." 였습니다.
앞서 설명했던 큐브리드의 개발프로세스는 이전에 누군가의 노력으로 만들어진 절차입니다. 우리가 왜, 어떤 목표를 가지고 개발프로세스를 운영하고 있는지 충분한 이해를 못 한다면 개발 문화로 자리 잡지 못한다고 생각했습니다. 시간이 지날수록 모호한 규칙들은 금방 잊어버리거나 확실히 합의 되지 않아 일부의 구성원들만 알고 있는 것 같은 경우가 생기고 있었습니다. 개발 프로세스의 각 요소에 대해서 충분한 합의가 없이 구성원들의 문화로 자리 잡지 못한다면, 서로 조금씩 다르게 이해하고 있는 디테일들은 구성원들의 귀차니즘과 까먹음에 의해서, 지켜야 할 가치 있는 개발 문화에서 멀어질 것이 당연했습니다.
그래서 큐브리드가 개발 문화로 지켜야 할 가치는 무엇일까 생각해보았습니다. 그것은 이 포스팅의 첫 문단에서 소개한 오픈소스의 주요 가치인 "참여, 개방, 공유" 입니다. 큐브리드의 개발 문화의 관점에서 해석해보면 "큐브리드 프로젝트에 누구든 쉽고 안전하게 참여할 수 있고, 그 과정은 누구든 투명하게 볼 수 있으며 정보들이 충분히 잘 공유되어야 한다"라고 볼 수 있습니다. 그리고 비로소 이러한 가치들을 잘 지키는 것이 더 높은 수준의 개발 결과물과 연결된다는 것을 알게 되었습니다.
이러한 내용들이 사내에서 공유되어, 잘 정립된 개발 프로세스는 단순히 관리의 편의성, 성숙한 개발문화를 표현하는 것을 넘어서 업무의 효율성을 극대화해 줄 것이라는 공감대가 형성되어 개발 프로세스를 조금 더 개선하게 되었습니다. 다음 장에서 개발 프로세스의 개선사항과 "참여, 개방, 공유"의 가치와 어떻게 연결되는지 알아보겠습니다.
JIRA 프로세스 정리
앞서 큐브리드 개발 프로세스 소개에서 설명한 것과 같이 CUBRID의 모든 프로젝트, 기능추가, 버그수정은 JIRA 이슈 생성으로부터 시작합니다. 이슈를 생성하고 관리할 때 각 개발 프로세스 단계에서 필수로 작성되어야 할 항목들과 내용들을 작성해야 하는데 사용자가 파악하기 힘든 부분이 많았습니다.

위의 화면은 JIRA 프로세스를 개선하기 전의 이슈 생성 창입니다. JIRA 프로젝트를 만들면 기본으로 설정된 화면을 그대로 사용하고 있었고 다음과 같은 문제가 있었습니다.
- - 이슈를 생성할 때 입력해야 할 항목들이 너무 많이 보여서 어떤 항목만 작성해야할 지 모르겠음
- - 어떤 내용을 작성해야할지 모르겠음
이 문제로 이슈 작업마다 필요한 내용들이 일관적으로 작성되지 않거나, 매번 작업을 시작할 때마다 내용을 넣어야하나 말아야하나 고민하면서 생산성이 떨어지고 있었습니다.
이슈를 생성할 때 입력해야 할 항목들이 너무 많이 보여서 어떤 항목만 작성해야할 지 모르겠음
큐브리드에 새로 합류한 동료개발자가 처음 이슈를 생성할 때 가장 많이 하는 질문은 "헉... 여기 있는 내용 다 입력해야해요??" 였습니다. 이슈를 생성할 때 프로젝트 메인테이너가 이슈를 선별하기 위해서 필요한 내용은 이 중 몇 가지만 정해져 있는데, JIRA의 기본 설정을 그대로 사용해서 모든 필드가 보여지고 있었습니다.
이런 상황은 외부 기여자가 큐브리드에 참여하기 위한 문턱을 높이게 되는데, 이슈 생성 버튼을 눌렀을 때, 너무 많은 필드가 한꺼번에 보이면 혹시나 잘못 입력할까봐 여기저기 찾아보다가 기여해보기를 포기하게 됩니다.
따라서 각 이슈의 상태에서 필요한 내용들을 정리해서, 그 상태로 변경할 때 필수적으로 입력해야하는 내용만 보여져 입력하도록 설정했습니다.
모든 개선사항을 설명하기 힘들어 한 가지 예만을 소개하자면, 버전과 관련한 필드의 경우 이슈를 생성하고 관리할 때 구성원들이 가장 헷갈려하는 부분들 중에 하나였습니다. 위 그림에서 빨간색으로 표시한 것 처럼 다음 세 가지 버전 필드가 이슈 생성 과정에서 함께 보여지니 어디에 입력해야 할지 모르니 이 중 하나에만 값을 넣어주거나 입력을 포기하는 경우가 생겼습니다.
- - Affected Version: 이슈 생성자가 분석 과정에서 버그나 문제를 찾은 버전 (버그 수정 타입 only)
- - Planned Version: 이슈를 진행하도록 계획한 버전
- - Fixed Version: 이슈 결과가 반영된 버전
그래서 각 버전에 대해 명확한 의미를 공유하고, 어떤 이슈의 상태에서 입력해야 하는지 정의했습니다. Affected Version은 이슈 생성 시(OPEN 상태), Planned Version은 프로젝트 메인테이너가 이슈 선별 시(CONFIRMED), 그리고 Fixed Version은 이슈 해결 시(RESOLVED) 에 입력해야합니다. 그래서 다음 그림과 같이 이슈 상태가 변할 때마다 각 단계에서 필요한 항목, 입력해야 하는 버전만 보여져 자연스럽게 내용을 빠뜨리지 않고 또 좀 더 편하게 개발 프로세스를 따라 작업을 진행할 수 있습니다.

어떤 내용을 작성해야할지 모르겠음
큐브리드에서는 이슈를 생성할 때 해야할 작업에 따라 이슈 타입(Issue Types)를 지정합니다.
- - Correct Error: 버그 수정
- - Improve Function/Performance: 기존의 기능을 개선하거나 성능을 향상
- - Development Subject: 새로운 기능
- - Refactoring: 불필요한 코드 정리, 코드 구조 변경 등의 작업
- - Internal Management: 소스 관리를 위한 작업
- - Task: 나머지
이러한 이슈 타입에 따라 작성할 내용이 달라지게 됩니다. 예를 들어 버그 수정의 경우에 어떤 버그가 발생했는지, 버그를 재현해보려면 어떻게 해야하는지, 버그를 고치면 어떻게 동작해야하는지 등을 적어야 합니다. 또 기능 개선이나 새로운 기능인 경우에 어떤 기능을 어떻게 추가할건지 자세한 설명이 필요합니다 (기능 스펙과 설계 디자인). 이 내용을 충분히 잘 작성하고 공유하면 프로젝트에 참여하는 사람들에게 좀 더 쉽게 프로젝트에 반영된 내용들을 파악할 수 있게 합니다. 그리고 이렇게 잘 정리해서 공유된 기능 스펙이나 설계 디자인은 개발 작업 결과의 품질을 높이는 장점도 가지게 됩니다.
그래서 우리는 각 이슈 타입에 따라 꼭 담아야 할 내용들을 적도록 내용 템플릿을 구성했습니다.
| Correct Error |
Improve Function/Performance Development Subject Refactoring |
Internal Management Task |
|---|---|---|
|
|
Description: 이슈 설명 |
이 내용들은 다음 장에서 설명할 코드 리뷰 프로세스를 개선하는데 큰 도움을 줍니다. 큐브리드는 여러 기능과 모듈이 복잡하게 얽혀있는 시스템인 만큼 코드 변경사항만을 가지고 모든 맥락을 파악하기 어렵기 때문입니다.
Github 코드 리뷰/코드 반영 프로세스 개선
개발 프로세스에서 가장 중요한 목표 중 하나는 코드 리뷰를 어떻게 잘 할 수 있을까입니다. 코드 리뷰로 얻을 수 있는 장점은 다음과 같습니다. [3]
- - 더 좋은 코드 수준: 코드의 품질과 쉽게 관리할 수 있는 구조로 만듭니다.
- - 결함 발견: 기능 정확성(버그), 성능 문제, 보안 취약성 등을 더 잘 발견 할 수 있습니다.
- - 학습/지식 전달: 리뷰어와 저자, 그리고 오픈소스 프로젝트 참여자에게 코드베이스, 해결 방법에 대한 접근법 등의 지식등을 전달하고 공유할 수 있습니다.
- - 책임감 증대: 리뷰어와 저자 모두가 그 코드에 대한 책임감을 가질 수 있습니다.
- - 더 나은 솔루션: 더 나은 해결 방법과 아이디어에 대한 공유가 이루어집니다.
이러한 장점들은 구성원 모두 잘 알고 있지만, 막상 코드 리뷰를 하면 리뷰어는 어느 수준까지 리뷰해야하지? 또 작성자는 이런 수준의 리뷰까지 과연 필요한가? 라는 생각들을 하면서 조금은 의무적인 리뷰가 되어버릴 수 있습니다.
그래서 조금 더 효과적/효율적인 코드 리뷰를 유도하기 위해 어떻게 코드 리뷰를 잘 할 것인지 고민하고 개선할 필요가 있었습니다. 코드를 읽는 것은 고수준의 집중력을 요구하는 작업입니다. 따라서 리뷰어가 짧은 시간에 고수준의 고민을 하고 피드백을 줄 수 있도록 해야합니다.
큐브리드에서 코드 리뷰를 잘 하기 위해 도입해왔고, 또 개선한 내용을 소개해드리겠습니다.
자동화 도구 도입
지루하고, 컴퓨터가 더 잘 할 수 있는 부분에는 자동화 도구를 활용해서 리뷰어의 정신적인 노력을 낭비하지 않도록 해야합니다. 예를 들어 코드 스타일, 라이선스를 고치거나 자주 발생하는 실수 (변수를 초기화하지 않거나 필요 없는 코드가 남아있는 등) 와 같은 것입니다.
큐브리드에서는 코드 리뷰에 도움을 줄 수 있도록 기본적으로 다음의 자동화 도구를 도입하고 있었습니다.
- - 빌드: 반영할 코드에 대해서 각 환경 별로 (CentOS, Ubuntu, Windows) 빌드를 하고 성공 여부를 보여줍니다.
- - SQL 테스트 자동화: 많은 SQL 테스트 케이스를 돌려보고 기능에 문제가 없는지 검증합니다.
참고) https://app.circleci.com/pipelines/github/CUBRID
이러한 자동화 도구는 좀 더 안정적인 코드가 반영될 수 있도록 도움을 주었습니다. 하지만 리뷰어가 코드가 설계 디자인을 얼마나 잘 충족하는지, 반영할 코드의 로직에 집중할 수 있도록 도와주기엔 부족합니다. 리뷰어는 단순 실수나, 코드 포매팅과 같은 눈에 쉽게 보이는 문제에 리뷰 시간 동안 매몰되기 쉽기 때문입니다.

코드 퀄리티 유지에 중요하지만, 고수준의 리뷰와는 거리가 먼 코드포매팅 피드백
따라서, Pull Request에서 이러한 저수준의 리뷰는 자동화 도구를 사용하여 리뷰어가 고수준의 리뷰만을 집중할 수 있도록 개선했습니다.
- - license: 오픈소스의 라이선스 준수와 책임을 다하기 위해 올바른 형태의 라이센스 헤더 주석을 가지고 있는지 확인합니다.
- - Pull Request Style: 반영할 코드에 대한 정보가 충분히 잘 공유될 수 있도록 모든 Pull Request이 각각의 JIRA 이슈와 연결되어야한다는 규칙을 가지고 있고 이를 검사합니다.
- - code-style: 일관성 있는 코드 유지를 위해 정의된 코드스타일을 따르는지 확인합니다. 코드 스타일은 코드 포맷팅 도구들을 이용하여 정의하고, code-style은 이 도구들을 이용해 정해진 규칙을 올바르게 따르는지 확인하고 수정합니다. 만약 규칙과 다르다면 실패하고 PR의 suggestion을 통해 리포트 합니다.
- - cppcheck: Cppcheck는 C++ 언어를 위한 정적분석 도구입니다. 사용되지 않는 변수, NULL 참조 등 개발자가 저지를 수 있는 많은 문제들이 정적 분석을 통해 발견될 수 있습니다. 이러한 오류들은 실수하기 쉽지만 명백하여 문맥없이 코드를 살펴보는 것만으로 찾아낼 수 있습니다. 그렇기에 리뷰어가 일일이 찾아내고 코멘트를 다는 것은 낭비입니다. 에러가 있을 경우 실패하고 PR에 코멘트를 사용하여 리포트 합니다.

새로 도입된 자동화 도구는 Github에서 직접 제공하는 CI 도구인 Github Actions (https://docs.github.com/en/actions) 를 사용했습니다. 이 도구의 도입으로 큐브리드에 기여자들이 큐브리드의 코드 컨벤션과 도달하려는 코드의 퀄리티를 좀 더 쉽게 이해하고 참여할 수 있습니다. 자동화 도구를 통과하지 않으면 쉽게 머지 (코드 반영) 되지 않아 혹시라도 실수할 걱정을 하지 않아도 됩니다.
큰 리뷰를 잘게 나누기
큐브리드는 여러 기능과 모듈이 복잡하게 얽혀있는 데이터베이스 시스템인 만큼 반영하려고 리뷰를 요청한 코드의 양이 어마어마하게 많은 경우가 많이 생깁니다. 너무 많은 코드 변경사항을 가진 하나의 Pull Request는 리뷰어의 효과적인 리뷰를 불가능하게 합니다.
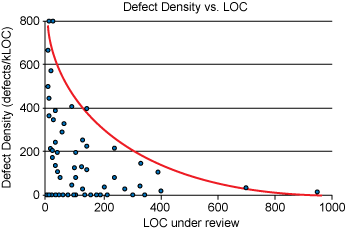
LOC (코드 라인 수) 가 400 줄 이상 넘어 갈수록 코드 결함 발견 밀집된 (Defect Density)은 적어진다. [4]
큐브리드에서는 너무 많은 변경사항을 가진 Pull Request를 피하기 위해 Feature branch를 생성해서, 하나의 의미 있는 작은 기능 단위로 코드 리뷰를 수행하려고 노력합니다. Feature branch에 대한 자세한 설명은 [5]를 참고해주세요.
개발 프로세스 (큐브리드 기여 가이드) 문서 작성
큐브리드 개발에 조금 더 쉽게 참여하도록, 전체적으로 개발 프로세스가 어떻게 진행되는지 설명하고 각 단계에서 필수적으로 작성해야 하는 내용을 공유할 방법이 필요했습니다. 그래서 큐브리드에 관심있어서 기여해보려는 개발자, 큐브리드에 새로 합류하는 신입 개발자 모두 참고할 수 있는 설명하는 가이드라인 문서를 작성했습니다.

이 가이드라인 문서를 작성하면서 고려했던 사항들이 있는데 다음과 같습니다.
- - 보기 힘든 문서는 읽지 않는다. 개발 프로세스는 단계별로 되어있으니 각 단계를 설명한 단락으로 쉽게 찾아갈 수 있게 하자!
- - 누구나 최신 버전을 항상 볼 수 있게 하자!
- - 완벽한 개발 프로세스도, 가이드 문서도 없다. 더 쉽게 편집할 수 있도록 하자!
워드 문서, JIRA 위키, 구글 문서, 웹 페이스 작성, Github pages 등 많은 도구와 서비스를 고민했습니다. 이러한 고민의 결과로 Gitbook 서비스를 사용하게 되었습니다. (Thank you for Gitbook Team)
- - 문서 구조별로 탭 형식으로 표시해주어 단락별로 쉽게 볼 수 있습니다.
- - 웹페이지로 배포되고 실시간으로 수정하고 반영하면 실시간으로 수정사항을 볼 수 있습니다.
- -오픈소스 프로젝트에 대해서 Open Source Community 플랜을 지원합니다!
다른 오픈소스 프로젝트에서도 기여 가이드문서를 작성해보려고 한다면 문서 배포 방법과 도구를 고민할 때 한번 참고해보세요!
마치며... 큐브리드의 개발 문화에 대하여
많은 개발자들이 당연히 좋은 개발 문화에서 일하고 싶어합니다. 그러나 세상에 완벽한 개발 문화를 가진 개발 조직은 없다고 생각합니다. 앞서 설명한 개발 프로세스는 '개발 문화'가 만들어지기 위한 수단이고 개발 프로세스에 검증 과정만을 더 추가할수록 당연히 생산성은 그에 따라 떨어집니다. 또 시간이 지나가고 상황이 바뀌면서 개선한 프로세스가 제대로 동작하지 않을 수도 있습니다.
큐브리드는 좀 더 나은 퀄리티의 결과와 높은 생산성의 균형을 찾으려고 노력하며 계속 나아가고 있습니다. 모든 구성원이 좀 더 자연스럽게 큐브리드의 개발 문화에 올라탈 수 있도록 다음의 내용과 같은 코드 리뷰를 잘 하는 법에 대해 구성원들이 모여서 공유하고 토론하기도 합니다.
- - How to Do Code Review Like a Human (https://mtlynch.io/human-code-reviews-1/, https://mtlynch.io/human-code-reviews-2/)

수평적이고 자유로운 소통, 지식의 공유를 중요하게 생각하는 큐브리드의 조직 문화를 기반으로, 많은 분들이 적극적으로 함께하고 도와주어 개발 프로세스를 개선할 수 있었습니다.
(Special Thanks to CTO, 김재은, 김주호 선임연구원). 이 글을 통해 큐브리드의 개발 조직이 일하는 방식을 소개하고, 개발 문화에 대해 이해할 수 있는 기회가 되었으면 합니다.
감사합니다 :-)
참고자료
[1] 오픈소스 가이드, https://opensource.guide/ko/
[2] 오픈소스 기술혁신, 수평적인 정보 공유와 투명한 프로세스가 생명이다, 소프트웨어정책연구소, https://spri.kr/posts/view/19821?page=2&code=column
[3] 코드 리뷰, 위키피디아, https://en.wikipedia.org/wiki/Code_review
[4] Best Practices for Code Review, https://smartbear.com/learn/code-review/best-practices-for-peer-code-review/
[5] Feature branch workflow, https://www.atlassian.com/git/tutorials/comparing-workflows/feature-branch-workflow
 CUBRID TDE(Transparent Data Encryption)
CUBRID TDE(Transparent Data Encryption)
 CUBRID를 이용한 스니핑 방지 - 패킷암호화
CUBRID를 이용한 스니핑 방지 - 패킷암호화









